
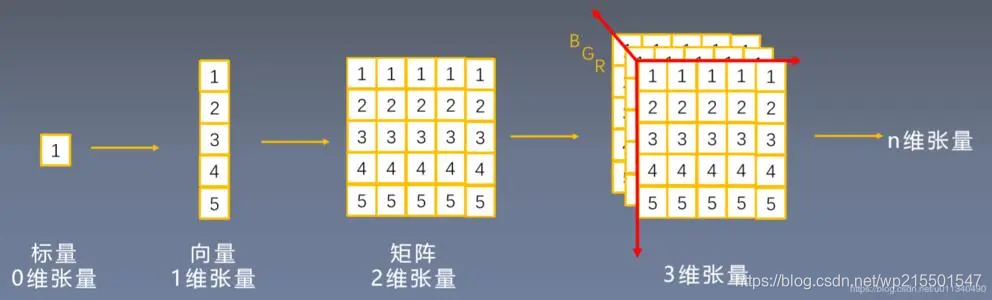
一、张量
(一)张量介绍
张量(也可以叫做Tensors)是pytorch中数据存储和表示的一个基本数据结构和形式,它是一个多维数组,是标量、向量、矩阵的高维拓展。它相当于Numpy的多维数组(ndarrays),但是tensor可以应用到GPU上加快计算速度, 并且能够存储数据的梯度信息。
维度大于2的一般称为高维张量。以计算机的图像处理数据为例
3维张量,可以表示图像的:通道数×高×宽
4维张量,通常表示图像的:样本数×通道数×高×宽

(二)张量的创建
①基于torch.tensor()创建张量
torch.tensor()创建张量共有8个属性:data、dtype、shape、device、requires_grad、grad、grad_fn
import torch
#创建张量
#参数data:可以为列表,或者数组
t1=torch.tensor([3,5])
print(t1)
print("类型",type(t1))
print("设备",t1.device)
print("要求梯度",t1.requires_grad)
print("梯度值",t1.grad)
print("梯度函数",t1.grad_fn)
print("是否为叶子",t1.is_leaf)#自动创建的为叶子True
运行结果:
tensor([3, 5])
类型 <class 'torch.Tensor'>
设备 cpu
要求梯度 False
梯度值 None
梯度函数 None
是否为叶子 True
②创建张量,修改数据类型,要求梯度
import torch
#创建张量,修改数据类型为float,增加梯度回传之后张量的变化
t1=torch.tensor([3,5],dtype=torch.float,requires_grad=True)
print(t1)
print("类型",type(t1))
print("设备",t1.device)
print("要求梯度",t1.requires_grad)
print("梯度值",t1.grad)
print("梯度函数",t1.grad_fn)
print("是否为叶子",t1.is_leaf)#自动创建的为叶子True
运行结果:
tensor([3., 5.], requires_grad=True)
类型 <class 'torch.Tensor'>
设备 cpu
要求梯度 True
梯度值 None
梯度函数 None
是否为叶子 True
③创建张量,非叶子(必须要求梯度,才可以)
import torch
#创建张量
t1=torch.tensor([3,5],dtype=torch.float,requires_grad=True)
t2=t1*10
print(t2)
print("类型",type(t2))#<class 'torch.Tensor'>
print("设备",t2.device)#cpu
print("要求梯度",t2.requires_grad)#False
print("梯度值",t2.grad)#None
print("梯度函数",t2.grad_fn)#Mul是加法等到的
#只有叶子可以计算梯度,不是叶子没有梯度,如果查看会出警告
print("是否为叶子",t2.is_leaf)#<Add>自动创建的为叶子True
运行结果:
tensor([30., 50.], grad_fn=<MulBackward0>)
类型 <class 'torch.Tensor'>
设备 cpu
要求梯度 True
梯度值 None
梯度函数 <MulBackward0 object at 0x000000000258E7B8>#Mul是加法等到的
是否为叶子 False
总结
(1)如果原始tensor是要求梯度,该tensor是一个叶子节点,基于该tensor的操作是个非叶子节点,没有梯度信息的
(2)如果原始tensor是不要求梯度,该tensor是一个叶子节点,基于该tensor的操作得到也是一个叶子节点
④利用Numpy创建张量
1、直接利用Numpy创建数组,转换为张量
import torch
import numpy as np
#基于Numpy的创建Tensor
arr=np.array([1,2,3,6])
t1=torch.tensor(arr)
print(t1)
运行结果
tensor([1, 2, 3, 6], dtype=torch.int32)
2、修改原数组,看看张量与数组的关系
import torch
import numpy as np
#基于Numpy的创建Tensor
arr=np.array([1,2,3,6])
t1=torch.tensor(arr)
print(t1)
arr[0]=1000
print('修改后'.center(60,'-'))
print("数组\n",arr)
print("tensor\n",t1)
tensor([1, 2, 3, 6], dtype=torch.int32)
----------------------------修改后-----------------------------
数组
[1000 2 3 6]
tensor
tensor([1, 2, 3, 6], dtype=torch.int32)
3、利用form_numpy创建张量,并修改和查看内存
import torch
import numpy as np
#基于Numpy的创建Tensor
arr=np.array([1,2,3,6])
t1=torch.tensor(arr)
print(t1)
#如果使用from_numpy创建tensor,张量和数组共享内存,指向同一个共享
#张量和数组,一个变换,另一个也变换
t2=torch.from_numpy(arr)
arr[0]=1000
print('修改后'.center(60,'-'))
print("数组\n",arr,id(arr))
print("tensor\n",t2,id(arr))
运行结果:
tensor([1, 2, 3, 6], dtype=torch.int32)
----------------------------修改后-----------------------------
数组
[1000 2 3 6] 4151456
tensor
tensor([1000, 2, 3, 6], dtype=torch.int32) 4151456
4、利用form_numpy创建张量后进行修改,将张量转换为数组
import torch
import numpy as np
#基于Numpy的创建Tensor
arr=np.array([1,2,3,6])
t2=torch.from_numpy(arr)
arr[0]=1000
t2[-1]=999
print('修改后'.center(60,'-'))
print("数组\n",arr,id(arr))
print("tensor\n",t2,id(arr))
#将tensor转换为数组
t2_arrr=t2.numpy()
print(t2_arrr, type(t2_arrr))
运行结果:
----------------------------修改后-----------------------------
数组
[1000 2 3 999] 31348896
tensor
tensor([1000, 2, 3, 999], dtype=torch.int32) 31348896
[1000 2 3 999] <class 'numpy.ndarray'>
二、梯度
只有x是叶子节点,其他节点y、z都是被动生成的,通过out.backward()进行反向传播
import torch
#x是叶子节点
x=torch.ones((2,2),requires_grad=True)
print(x)
y=x+2
z=y*y*3
print(y)
print(z)
out=z.mean()
print(out)
#在进行反向传播之前,查看x的梯度
print("x的梯度before",x.grad)
#反向传播
out.backward()
#只有叶子节点才能计算梯度,查看x的梯度
print("x的梯度",x.grad)
运行结果:
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
tensor([[3., 3.],
[3., 3.]], grad_fn=<AddBackward0>)
tensor([[27., 27.],
[27., 27.]], grad_fn=<MulBackward0>)
tensor(27., grad_fn=<MeanBackward0>
x的梯度before None
x的梯度 tensor([[4.5000, 4.5000],
[4.5000, 4.5000]])
三、反向传播
利用一个具体环境,理解反向传播:
已知房屋的面积与价格成正比例关系,利用通过已知的真实价格与
import torch
#设置随机种子,使得随机数不发生变换
torch.manual_seed(1)
#面积
x=torch.randint(low=10,high=40,size=(10,1))
#print(x)
#价格
y=5*x+torch.randn(10,1)
#y=5*x+torch.linspace(-0.002,0.002,100).reshape(-1,1)
#print(y)
#寻找w,b
#随机制订w,b
#w=torch.randn([2.0],requires_grad=True)#权重,要求梯度,才能回传
w=torch.tensor([2.0],requires_grad=True)
#b=torch.randn(1,requires_grad=True)#偏执,要求梯度,才能回传
b=torch.zeros(1,requires_grad=True)
#定义学习率
lr=0.0001
for epoch in range(5000):
# wx=w*x+b
#print(wx)
y_pred=w*x+b
#回归问题:1*2((y_pred-y)**2)
#均方误差
loss=0.5*(((y_pred-y)**2).mean())#很多值
#print(loss)
#print("w之前的梯度", w.grad)
loss.backward()
#print("w的梯度",w.grad)
#更新梯度
#w = w - lr * w.grad
w.data= w.data - lr * w.grad
#b = b - lr * b.grad
b.data = b.data - lr * b.grad
#结束条件
print("第{}次的loss={}".format(epoch,loss))
print("第{}次的w={},b={}:".format(epoch, w.grad, b.grad))
if loss.data.numpy()<1:
break
print("最终的w和b",w,b)
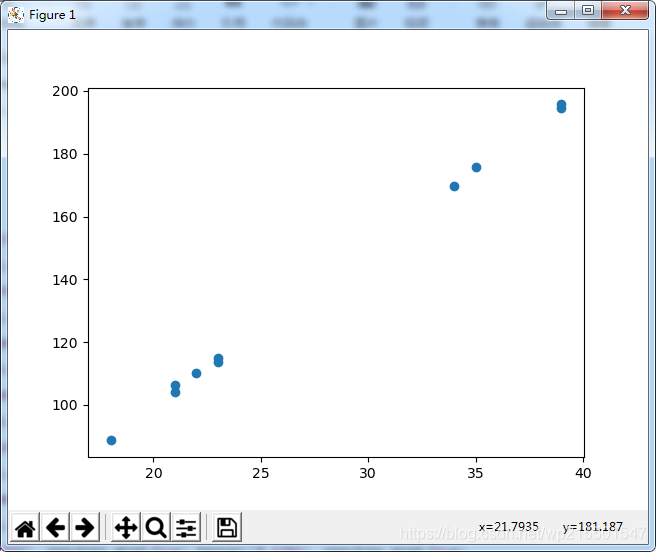
import matplotlib.pyplot as plt
plt.scatter(x.data.numpy(),y.data.numpy())
#plt.plot(x.data.numpy,(w*x+b).data.numpy())
plt.show()
第0次的loss=3678.266357421875
第0次的w=tensor([-2451.6199]),b=tensor([-82.4380]):
第1次的loss=3101.153076171875
第1次的w=tensor([-4702.6914]),b=tensor([-158.1258]):
第2次的loss=2131.90380859375
第2次的w=tensor([-6569.0713]),b=tensor([-220.8654]):
第3次的loss=1081.1798095703125
第3次的w=tensor([-7898.0845]),b=tensor([-265.5179]):
第4次的loss=285.7577819824219
第4次的w=tensor([-8581.0156]),b=tensor([-288.4241]):
第5次的loss=0.5849725008010864
第5次的w=tensor([-8561.9990]),b=tensor([-287.7038]):
最终的w和b tensor([5.8764], requires_grad=True) tensor([0.1303], requires_grad=True)
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/114465.html原文链接:https://javaforall.net


