
问题
我们经常遇到一种情况,在SSMS中运行很慢的一个查询,当把查询转化成从源到目的数据库的SSIS数据流以后,需要花费几倍的时间!源和数据源都没有任何软硬件瓶颈,并且没有大量的格式转换。之前看了很多关于这种情况的优化方案,例如扩大缓存大小等。虽然也能快一点,但是仍然远远比直接在SSMS中查询的速度满的多。究竟是什么原因导致的呢?
解决
首先这个数据流性能是有很多因素决定的,例如源数据的速度、目标库的写入速度、数据转换和路径数量的使用等等。但是,如果只是一个很简单的数据流,那么提高缓存的容量即可改善性能。例如,如果缓存设的更大,那么数据流一次转换更多的数据行,所以性能可以提升。当然很多其他情况就不是这么容易优化了。并且缓存过大时一旦源读取填充缓存时间过长导致了目标库闲置一直处于等待状态直到缓存完成。在这个技巧中,将会介绍如何解决这种问题。
测试场景
首先创建一个百万数据的源表。表结构是一个典型的name-value 键值对表,便于阐述我们的问题。其中value 列设为5000char。如下:
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[NameValuePairs]') AND [type] IN (N'U')) DROP TABLE [dbo].[NameValuePairs]; GO IF NOT EXISTS (SELECT 1 FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[NameValuePairs]') AND [type] IN (N'U')) BEGIN CREATE TABLE [dbo].[NameValuePairs] ([ID] [int] IDENTITY(1,1) NOT NULL ,[Type] [varchar](100) NOT NULL ,[Value] [varchar](5000) NULL PRIMARY KEY CLUSTERED ([ID] ASC)); END GO
使用AdventureWorksDW2012 样板数据,你可以搜索下载。表中有各种用户信息:names, gender, addresses, birth dates, email addresses 和phone numbers。如下:
INSERT INTO [dbo].[NameValuePairs]([Type],[Value]) SELECT [Type] = 'Customer Name' ,[Value] = [FirstName] + ' ' + [LastName] FROM [AdventureWorksDW2012].[dbo].[DimCustomer] UNION ALL SELECT [Type] = 'BirthDate' ,[Value] = CONVERT(CHAR(8),[BirthDate],112) FROM [AdventureWorksDW2012].[dbo].[DimCustomer] UNION ALL SELECT [Type] = 'Gender' ,[Value] = [Gender] FROM [AdventureWorksDW2012].[dbo].[DimCustomer] UNION ALL SELECT [Type] = 'Email Address' ,[Value] = [EmailAddress] FROM [AdventureWorksDW2012].[dbo].[DimCustomer] UNION ALL SELECT [Type] = 'Address' ,[Value] = [AddressLine1] FROM [AdventureWorksDW2012].[dbo].[DimCustomer] UNION ALL SELECT [Type] = 'Phone Number' ,[Value] = [Phone] FROM [AdventureWorksDW2012].[dbo].[DimCustomer]; GO 500
当然也可以自己写一个循环脚本插入数据。DimCustomer 维度表中有18000行数据,通过不同的结果集能返回110,000行数据 。注意这个语句INSERT …SELECT … ,最后有个GO,这不是官方的,但是也是可以用的,后面紧跟的数字表示批处理执行的次数。本例中就是500次。意味着5,500,000行数据被插入,大概有2.3gb。


比如我们可查询邮箱地址:
SELECT [Customer Email] = [Value] FROM [dbo].[NameValuePairs] WHERE [Type] = 'Email Address';
查询会返回9,242,000 行数据用33秒左右。这个是我们包的最快运行的时间理论上。那么包能不能运行的更快呢?SSIS中将邮件地址转换成邮箱维度表,该列在新表中只有50个字符的宽度,但是在源表中的该列却是5000个字符。但是我们知道在本例中这个邮箱地址不会超过50个字符。
CREATE TABLE dbo.DimEmail ([SK_Email] INT IDENTITY(1,1) NOT NULL ,[Email Address] VARCHAR(50) NOT NULL ,[InsertDate] DATE NOT NULL);
SSIS包
生成包是相对简单的,整个控制流由4分任务组成:
- 第一个任务是记录包开始的日志。
- 第二个任务是清空目标表。
- 第三个任务是数据流任务,下面详细介绍。
- 最后日志记录任务结束。
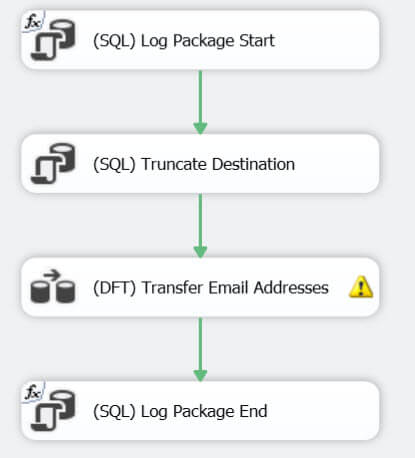
数据流本身也是很简单:使用前面提到查询读取数据源,然后将加入了审核列和目标表的派生列将结果集写入邮箱维度表。

目标数据库展示了一个截断警告,因为我们试图将超过目标表字段长度的数据插入进来。
初始性能
为了限制外部影响,目标数据库的日志和数据文件足够大,不会影响整个事务。在开发环境下,整个包运行了大约40秒。这是要比直接查询慢的!写入操作是可以被优化的。下面看一下如何优化行数据的插入…
优化数据流
之前提到的最佳实践之一就是扩大缓冲区,具体操作就是修改数据流属性里面的DefaultBufferMaxRows(默认缓存最大行数) 和DefaultBufferSize(默认缓存大小)。SSIS引擎就是使用这个属性来估计在管道中传送数据的缓存大小。更大的缓存意味着更多行可以被同时处理。
当设定最大值行数为30000并且默认缓存为20M的时候,执行包花费了30秒,这也仅仅比之前源查询快了一点。所以还应该有空间去优化。
在源组件端,估计行的大小是取决于查询返回所有列中的最大列。这也是性能问题的所在:我们建立的键值对表,最大列我5000字符,SSIS引擎将会认为这个列一定包含5000个字符,及时实际上小于50个字符。5000个非Unicode字符等于5000个字节或者5kb。默认的缓存大小事10MB,因此意味着一次仅仅能存储2000行数据,15分之一。这也意味着我们我们并没有最优化的使用缓存。
那么我们只需要调整源数据查询映射的实际数据长度,就能够实现潜在性能的提升。如下:
SELECT [Customer Email] = CONVERT(VARCHAR(50),[Value]) FROM [dbo].[NameValuePairs] WHERE [Type] = 'Email Address';
既然我们已经知道该列最大的是50个字符,改成这样以后一次性能多放入一百倍的数据。当包运行时数据流执行仅仅用了12秒!
我们可以看一下三次不同的包的执行比较(默认配置–扩大缓存–扩大缓存并减小列宽),分别在SSIS catalog 中运行20次在,曲线图如下:
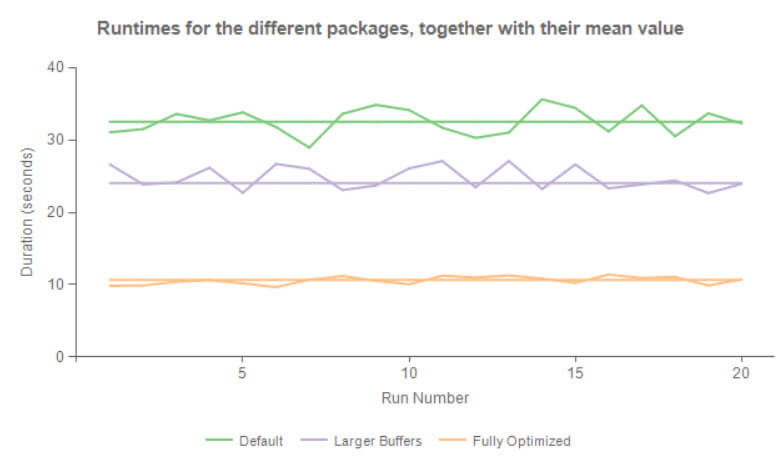
不用多说大家都知道这三种性能如何了。
总结
本篇只是针对数据流进行了优化,并不涉及SQL本身的优化,这里偏重BI一点。通过关注返回源数据的列宽,极大的提高了性能,除此之更小的列性能更好。一次性缓存的行也越多。通过扩大缓存也进一步能提升性能
补充:
除了以上两点还有一个引擎线程数,该参数用来实现并行执行。
“EngineThreads” 属性 ,也是数据流任务中的参数,它定义有多少个工作线程在引擎调度时可以被使用。默认值为10,可设置范围为2-60之间,建议根据物理CPU个数调高到总CPU个数左右。如双核8CPU的服务器(CPU核心总数为16),可设置为15-17个左右。具体实现的时候还要考虑其他程序的并行执行带来的影响。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/119719.html原文链接:https://javaforall.net


