
大家好,又见面了,我是你们的朋友全栈君。
这里写目录标题
1.做时间序列问题
2.问题
1.数据集自己做,为多个输入对应多个或一个输出
2.损失函数
注意:不能用交叉熵 nn.CrossEntropyLoss()
nn.CrossEntropyLoss()要求target目标值即真实值是标签,是torch.int64类型数据,即整数,不允许小数,如果输入小数会强行取整,
应该用
nn.MSELoss()
我在这个问题上纠结了很久,总是显示
RuntimeError: expected scalar type Long but found Float
导致我找了很久怎么样才能把torch.float64保留小数的情况下转成long,后来查资料torch.long就是torch.int64,简直变态
后来一点一点往上找才知道的这个错误
注意2:真实值(目标值)必须是两个维度,否则会警告,不会报错
增加维度方法:
1.torch.unsqueeze(tensor, dim)
2.numpy_array = .numpy_array [np.newaxis, :, :] # 原来维度(10, 13)——(1, 10, 13)
补充
np.unaqueeze总是报错,不明白为什么
3.准确率
分类问题是有准确率这个评价的,但是我训练的rnn,loss一直降低,但是准确率为0,才反应过来,回归问题很难达到完全一致
3.结果
这是测试集预测结果,前10步预测后1步,勉强可以
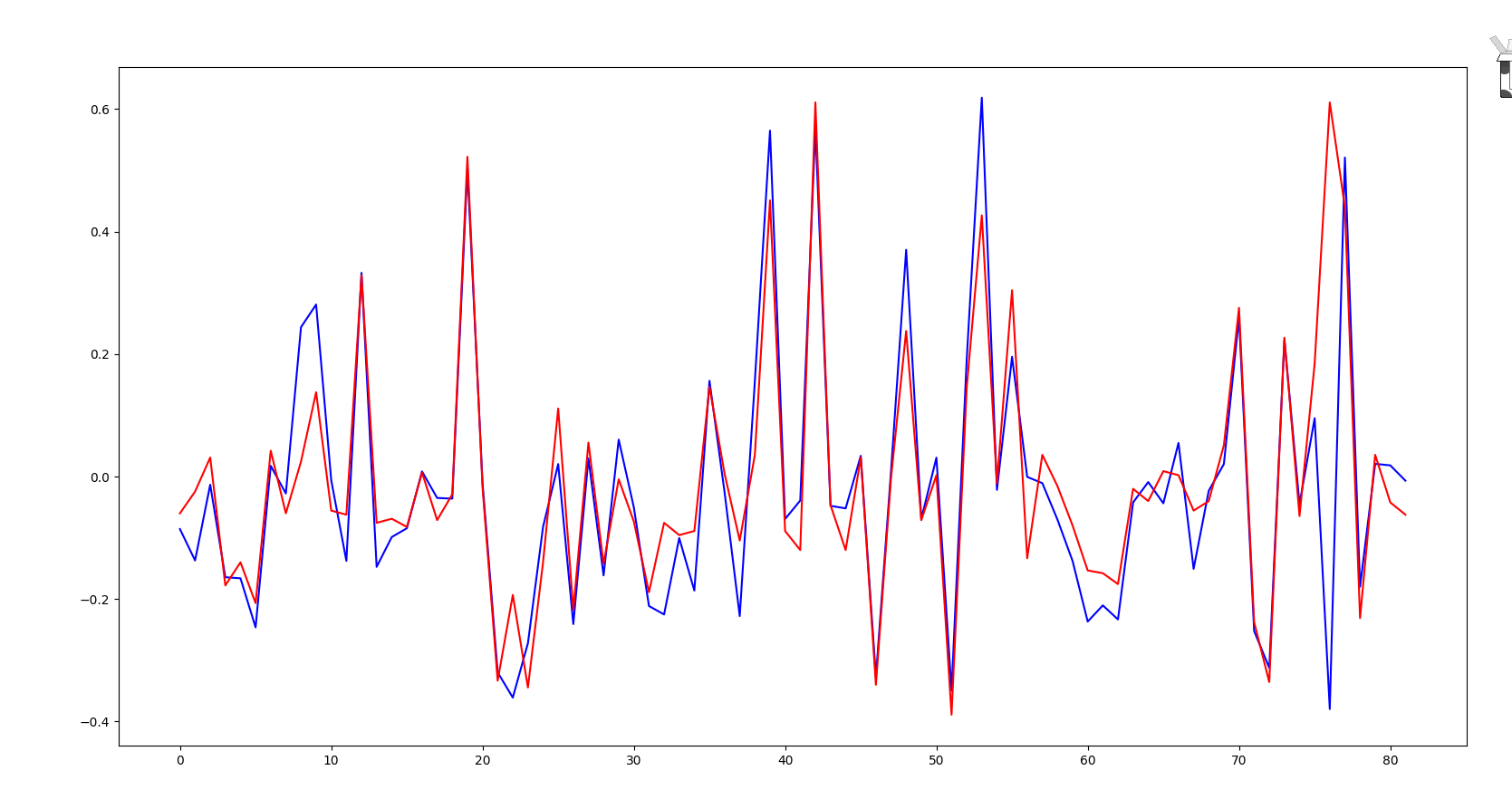

训练集结果:
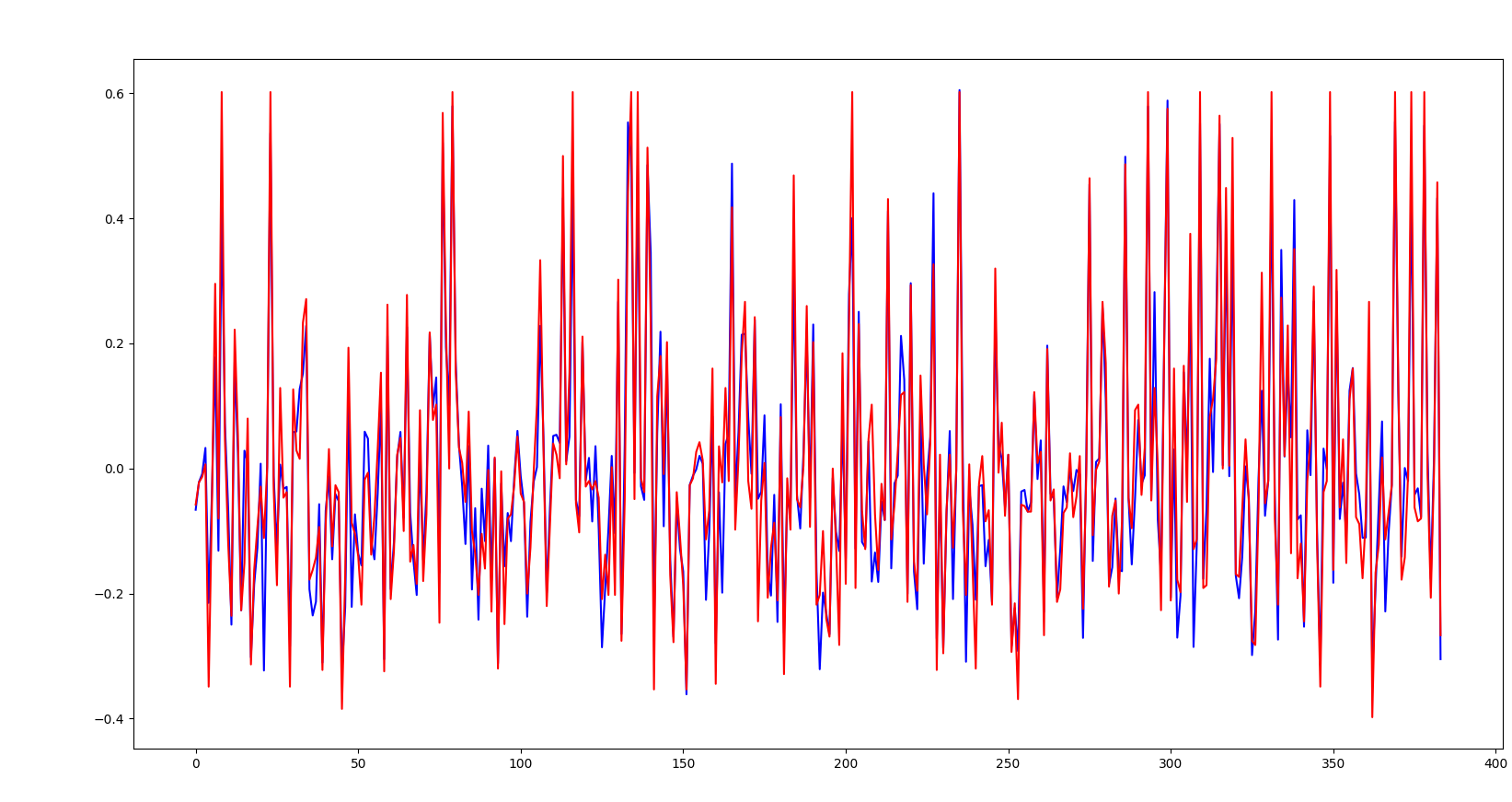
之后需要
0.5. 根据上一步预测结果预测下一个——做不到,x为13个变量,y只有1个,无法用y作为下一个x
- 找一个预测结果评价指标
- transformer编码解码
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/127416.html原文链接:https://javaforall.net


