
大家好,又见面了,我是你们的朋友全栈君。
CUDA编程(四)
CUDA编程(四)并行化我们的程序
上一篇博客主要讲解了怎么去获取核函数执行的准确时间,以及如何去根据这个时间评估CUDA程序的表现,也就是推算所谓的内存带宽,博客的最后我们计算了在GPU上单线程计算立方和的程序的内存带宽,发现其内存带宽的表现是十分糟糕的,其所使用的内存带宽大概只有 5M/s,而像GeForce 8800GTX这样比较老的显卡,也具有超过50GB/s 的内存带宽 。
面对我们首先需要解决的内存带宽问题,我们首先来分析这个问题,然后我们将使用并行化来大大改善这一情况。
为什么我们的程序表现的这么差?
为什么我们的程序使用的内存带宽这么小?这里我们需要好好讨论一下。
在 CUDA 中,一般的数据复制到的显卡内存的部份,称为global memory。这些内存是没有 cache 的,而且,存取global memory 所需要的时间(即 latency)是非常长的,通常是数百个 cycles。由于我们的程序只有一个 thread,所以每次它读取 global memory 的内容,就要等到实际读取到数据、累加到 sum 之后,才能进行下一步。这就是为什么表现会这么的差,所使用的内存带宽这么的小。
由于 global memory 并没有 cache,所以要避开巨大的 latency 的方法,就是要利用大量的threads。假设现在有大量的 threads 在同时执行,那么当一个 thread 读取内存,开始等待结果的时候,GPU 就可以立刻切换到下一个 thread,并读取下一个内存位置。因此,理想上当thread 的数目够多的时候,就可以完全把 global memory 的巨大 latency 隐藏起来了,而此时就可以有效利用GPU很大的内存带宽了。

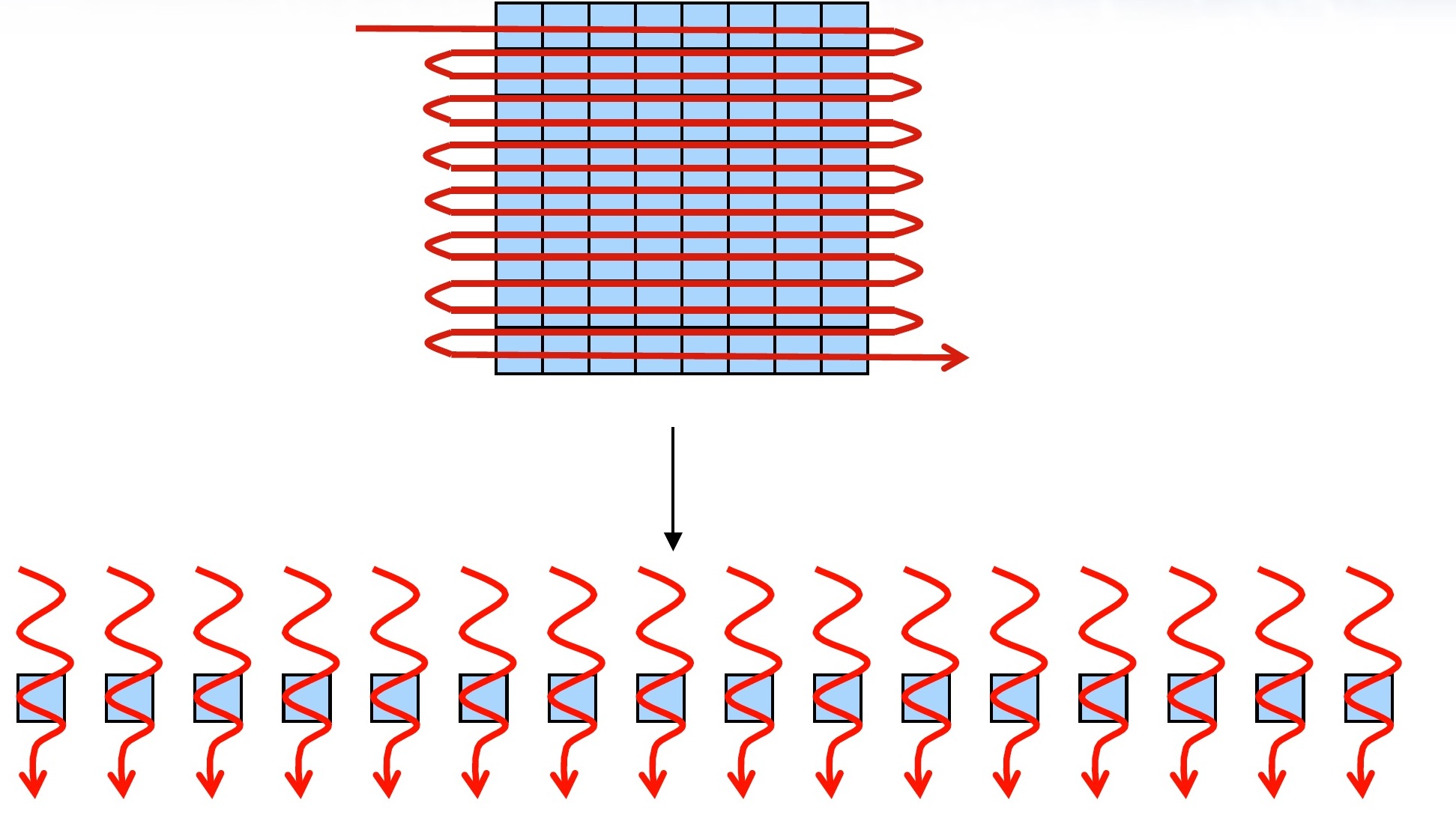
使用多Thread完成程序的初步并行化
上面已经提到过了,要想隐藏IO巨大的Latency,也就是能充分利用GPU的优势——巨大内存带宽,最有效的方法就是去并行化我们的程序。现在我们还是基于上次单线程计算立方和的程序,使用多Thread完成程序的初步并行。
先贴一下单线程的程序代码,我们将继续在这个代码的基础上进行改进:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
//CUDA RunTime API
#include <cuda_runtime.h>
//1M
#define DATA_SIZE 1048576
int data[DATA_SIZE];
//产生大量0-9之间的随机数
void GenerateNumbers(int *number, int size)
{
for (int i = 0; i < size; i++) {
number[i] = rand() % 10;
}
}
//打印设备信息
void printDeviceProp(const cudaDeviceProp &prop)
{
printf("Device Name : %s.\n", prop.name);
printf("totalGlobalMem : %d.\n", prop.totalGlobalMem);
printf("sharedMemPerBlock : %d.\n", prop.sharedMemPerBlock);
printf("regsPerBlock : %d.\n", prop.regsPerBlock);
printf("warpSize : %d.\n", prop.warpSize);
printf("memPitch : %d.\n", prop.memPitch);
printf("maxThreadsPerBlock : %d.\n", prop.maxThreadsPerBlock);
printf("maxThreadsDim[0 - 2] : %d %d %d.\n", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2]);
printf("maxGridSize[0 - 2] : %d %d %d.\n", prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]);
printf("totalConstMem : %d.\n", prop.totalConstMem);
printf("major.minor : %d.%d.\n", prop.major, prop.minor);
printf("clockRate : %d.\n", prop.clockRate);
printf("textureAlignment : %d.\n", prop.textureAlignment);
printf("deviceOverlap : %d.\n", prop.deviceOverlap);
printf("multiProcessorCount : %d.\n", prop.multiProcessorCount);
}
//CUDA 初始化
bool InitCUDA()
{
int count;
//取得支持Cuda的装置的数目
cudaGetDeviceCount(&count);
if (count == 0) {
fprintf(stderr, "There is no device.\n");
return false;
}
int i;
for (i = 0; i < count; i++) {
cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, i);
//打印设备信息
printDeviceProp(prop);
if (cudaGetDeviceProperties(&prop, i) == cudaSuccess) {
if (prop.major >= 1) {
break;
}
}
}
if (i == count) {
fprintf(stderr, "There is no device supporting CUDA 1.x.\n");
return false;
}
cudaSetDevice(i);
return true;
}
// __global__ 函数 (GPU上执行) 计算立方和
__global__ static void sumOfSquares(int *num, int* result, clock_t* time)
{
int sum = 0;
int i;
clock_t start = clock();
for (i = 0; i < DATA_SIZE; i++) {
sum += num[i] * num[i] * num[i];
}
*result = sum;
*time = clock() - start;
}
int main()
{
//CUDA 初始化
if (!InitCUDA()) {
return 0;
}
//生成随机数
GenerateNumbers(data, DATA_SIZE);
/*把数据复制到显卡内存中*/
int* gpudata, *result;
clock_t* time;
//cudaMalloc 取得一块显卡内存 ( 其中result用来存储计算结果,time用来存储运行时间 )
cudaMalloc((void**)&gpudata, sizeof(int)* DATA_SIZE);
cudaMalloc((void**)&result, sizeof(int));
cudaMalloc((void**)&time, sizeof(clock_t));
//cudaMemcpy 将产生的随机数复制到显卡内存中
//cudaMemcpyHostToDevice - 从内存复制到显卡内存
//cudaMemcpyDeviceToHost - 从显卡内存复制到内存
cudaMemcpy(gpudata, data, sizeof(int)* DATA_SIZE, cudaMemcpyHostToDevice);
// 在CUDA 中执行函数 语法:函数名称<<<block 数目, thread 数目, shared memory 大小>>>(参数...);
sumOfSquares << <1, 1, 0 >> >(gpudata, result, time);
/*把结果从显示芯片复制回主内存*/
int sum;
clock_t time_used;
//cudaMemcpy 将结果从显存中复制回内存
cudaMemcpy(&sum, result, sizeof(int), cudaMemcpyDeviceToHost);
cudaMemcpy(&time_used, time, sizeof(clock_t), cudaMemcpyDeviceToHost);
//Free
cudaFree(gpudata);
cudaFree(result);
cudaFree(time);
printf("GPUsum: %d time: %d\n", sum, time_used);
sum = 0;
for (int i = 0; i < DATA_SIZE; i++) {
sum += data[i] * data[i] * data[i];
}
printf("CPUsum: %d \n", sum);
return 0;
}
下面我们要把程序并行化,那么要怎么把计算立方和的程序并行化呢?
最简单的方法,就是把数字分成若干组,把各组数字分别计算立方和后,最后再把每组的和加总起来就可以了。目前,我们可以写得更简单一些,就是把最后加总的动作交给 CPU 来进行。
那么接下来我们就按照这个思路来并行我们的程序~
首先我们先define一下我们的Thread数目
#define THREAD_NUM 256接着我们要修改一下我们的kernel函数:
// __global__ 函数 (GPU上执行) 计算立方和
__global__ static void sumOfSquares(int *num, int* result, clock_t* time)
{
//表示目前的 thread 是第几个 thread(由 0 开始计算)
const int tid = threadIdx.x;
//计算每个线程需要完成的量
const int size = DATA_SIZE / THREAD_NUM;
int sum = 0;
int i;
//记录运算开始的时间
clock_t start;
//只在 thread 0(即 threadIdx.x = 0 的时候)进行记录
if (tid == 0) start = clock();
for (i = tid * size; i < (tid + 1) * size; i++) {
sum += num[i] * num[i] * num[i];
}
result[tid] = sum;
//计算时间的动作,只在 thread 0(即 threadIdx.x = 0 的时候)进行
if (tid == 0) *time = clock() - start;
}threadIdx 是 CUDA 的一个内建的变量,表示目前的 thread 是第几个 thread(由 0 开始计算)。
在我们的例子中,有 256 个 threads,所以同时会有 256 个 sumOfSquares 函数在执行,但每一个的 threadIdx.x 是不一样的,分别会是 0 ~ 255。所以利用这个变量,我们就可以让每一个函数执行时,对整个数据的不同部份计算立方和。
另外,我们让时间计算只在 thread 0进行。
这样就会出现一个问题,由于有 256 个计算结果,所以原来存放 result 的内存位置也要扩大。
/*把数据复制到显卡内存中*/
int* gpudata, *result;
clock_t* time;
//cudaMalloc 取得一块显卡内存 ( 其中result用来存储计算结果,time用来存储运行时间 )
cudaMalloc((void**)&gpudata, sizeof(int)* DATA_SIZE);
cudaMalloc((void**)&time, sizeof(clock_t));
//扩大记录结果的内存,记录THREAD_NUM个结果
cudaMalloc((void**)&result, sizeof(int) * THREAD_NUM);
之前也提到过了,我们使用
函数名称<<<block 数目, thread 数目, shared memory 大小>>>(参数...);这种形式调用核函数,现在这里的线程数也要随之改变
sumOfSquares < << 1, THREAD_NUM, 0 >> >(gpudata, result, time);然后从GPU拿回结果的地方也需要改,因为先在不仅要拿回一个sum,而是线程个sum,然后用CPU进行最后的加和操作
int sum[THREAD_NUM];
//cudaMemcpy 将结果从显存中复制回内存
cudaMemcpy(&sum, result, sizeof(int) * THREAD_NUM, cudaMemcpyDeviceToHost);最后在CPU端进行加和
int final_sum = 0;
for (int i = 0; i < THREAD_NUM; i++) {
final_sum += sum[i];
}
printf("sum: %d gputime: %d\n", final_sum, time_use);同样不要忘记check结果:
final_sum = 0;
for (int i = 0; i < DATA_SIZE; i++) {
final_sum += data[i] * data[i] * data[i];
}
printf("CPUsum: %d \n", final_sum);
这样我们的程序就分在了256个线程上进行,让我们看一下这次的效率是否有一些提升
完整程序:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
//CUDA RunTime API
#include <cuda_runtime.h>
//1M
#define DATA_SIZE 1048576
#define THREAD_NUM 256
int data[DATA_SIZE];
//产生大量0-9之间的随机数
void GenerateNumbers(int *number, int size)
{
for (int i = 0; i < size; i++) {
number[i] = rand() % 10;
}
}
//打印设备信息
void printDeviceProp(const cudaDeviceProp &prop)
{
printf("Device Name : %s.\n", prop.name);
printf("totalGlobalMem : %d.\n", prop.totalGlobalMem);
printf("sharedMemPerBlock : %d.\n", prop.sharedMemPerBlock);
printf("regsPerBlock : %d.\n", prop.regsPerBlock);
printf("warpSize : %d.\n", prop.warpSize);
printf("memPitch : %d.\n", prop.memPitch);
printf("maxThreadsPerBlock : %d.\n", prop.maxThreadsPerBlock);
printf("maxThreadsDim[0 - 2] : %d %d %d.\n", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2]);
printf("maxGridSize[0 - 2] : %d %d %d.\n", prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]);
printf("totalConstMem : %d.\n", prop.totalConstMem);
printf("major.minor : %d.%d.\n", prop.major, prop.minor);
printf("clockRate : %d.\n", prop.clockRate);
printf("textureAlignment : %d.\n", prop.textureAlignment);
printf("deviceOverlap : %d.\n", prop.deviceOverlap);
printf("multiProcessorCount : %d.\n", prop.multiProcessorCount);
}
//CUDA 初始化
bool InitCUDA()
{
int count;
//取得支持Cuda的装置的数目
cudaGetDeviceCount(&count);
if (count == 0) {
fprintf(stderr, "There is no device.\n");
return false;
}
int i;
for (i = 0; i < count; i++) {
cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, i);
//打印设备信息
printDeviceProp(prop);
if (cudaGetDeviceProperties(&prop, i) == cudaSuccess) {
if (prop.major >= 1) {
break;
}
}
}
if (i == count) {
fprintf(stderr, "There is no device supporting CUDA 1.x.\n");
return false;
}
cudaSetDevice(i);
return true;
}
// __global__ 函数 (GPU上执行) 计算立方和
__global__ static void sumOfSquares(int *num, int* result, clock_t* time)
{
//表示目前的 thread 是第几个 thread(由 0 开始计算)
const int tid = threadIdx.x;
//计算每个线程需要完成的量
const int size = DATA_SIZE / THREAD_NUM;
int sum = 0;
int i;
//记录运算开始的时间
clock_t start;
//只在 thread 0(即 threadIdx.x = 0 的时候)进行记录
if (tid == 0) start = clock();
for (i = tid * size; i < (tid + 1) * size; i++) {
sum += num[i] * num[i] * num[i];
}
result[tid] = sum;
//计算时间的动作,只在 thread 0(即 threadIdx.x = 0 的时候)进行
if (tid == 0) *time = clock() - start;
}
int main()
{
//CUDA 初始化
if (!InitCUDA()) {
return 0;
}
//生成随机数
GenerateNumbers(data, DATA_SIZE);
/*把数据复制到显卡内存中*/
int* gpudata, *result;
clock_t* time;
//cudaMalloc 取得一块显卡内存 ( 其中result用来存储计算结果,time用来存储运行时间 )
cudaMalloc((void**)&gpudata, sizeof(int)* DATA_SIZE);
cudaMalloc((void**)&result, sizeof(int)*THREAD_NUM);
cudaMalloc((void**)&time, sizeof(clock_t));
//cudaMemcpy 将产生的随机数复制到显卡内存中
//cudaMemcpyHostToDevice - 从内存复制到显卡内存
//cudaMemcpyDeviceToHost - 从显卡内存复制到内存
cudaMemcpy(gpudata, data, sizeof(int)* DATA_SIZE, cudaMemcpyHostToDevice);
// 在CUDA 中执行函数 语法:函数名称<<<block 数目, thread 数目, shared memory 大小>>>(参数...);
sumOfSquares << < 1, THREAD_NUM, 0 >> >(gpudata, result, time);
/*把结果从显示芯片复制回主内存*/
int sum[THREAD_NUM];
clock_t time_use;
//cudaMemcpy 将结果从显存中复制回内存
cudaMemcpy(&sum, result, sizeof(int) * THREAD_NUM, cudaMemcpyDeviceToHost);
cudaMemcpy(&time_use, time, sizeof(clock_t), cudaMemcpyDeviceToHost);
//Free
cudaFree(gpudata);
cudaFree(result);
cudaFree(time);
int final_sum = 0;
for (int i = 0; i < THREAD_NUM; i++) {
final_sum += sum[i];
}
printf("GPUsum: %d gputime: %d\n", final_sum, time_use);
final_sum = 0;
for (int i = 0; i < DATA_SIZE; i++) {
final_sum += data[i] * data[i] * data[i];
}
printf("CPUsum: %d \n", final_sum);
return 0;
}运行结果:
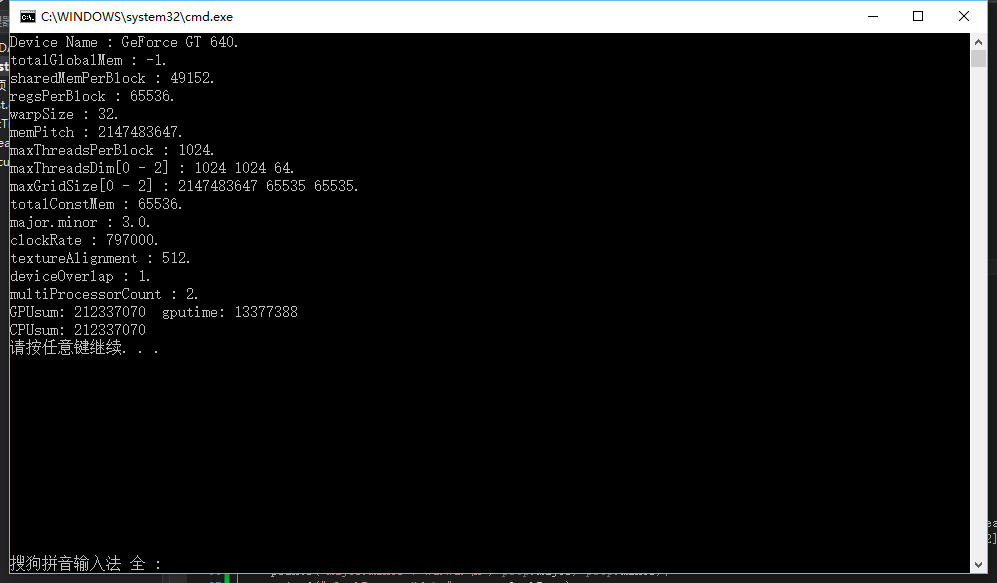
不知道大家是否还记得不并行时的运行结果:679680304个时钟周期,现在我们使用256个线程最终只使用了13377388个时钟周期
679680304/13377388 = 50.8可以看到我们的速度整整提升了50倍,那么这个结果真的是非常优秀吗,我们还是从内存带宽的角度来进行一下评估:
首先计算一下使用的时间:
13377388 / (797000 * 1000) = 0.016785S然后计算使用的带宽:
数据量仍然没有变 DATA_SIZE 1048576,也就是1024*1024 也就是 1M
1M 个 32 bits 数字的数据量是 4MB。
因此,这个程序实际上使用的内存带宽约为:
4MB / 0.016785S = 238MB/s可以看到这和一般显卡具有的几十G的内存带宽仍然具有很大差距,我们还差的远呢。
使用更多的Thread?
大家可以看到即使取得了50倍的加速,但是从内存带宽的角度来看我们还只是仅仅迈出了第一步,那么是因为256个线程太少了吗?我们最多可以打开多少个线程呢?我们可以看到我们打印出来的显卡属性中有这么一条:
MaxThreadPerBlock : 1024
也就是说我们最多可以去开1024个线程,那么我们就试试极限线程数量下有没有一个满意的答案:
#define THREAD_NUM 1024运行结果:
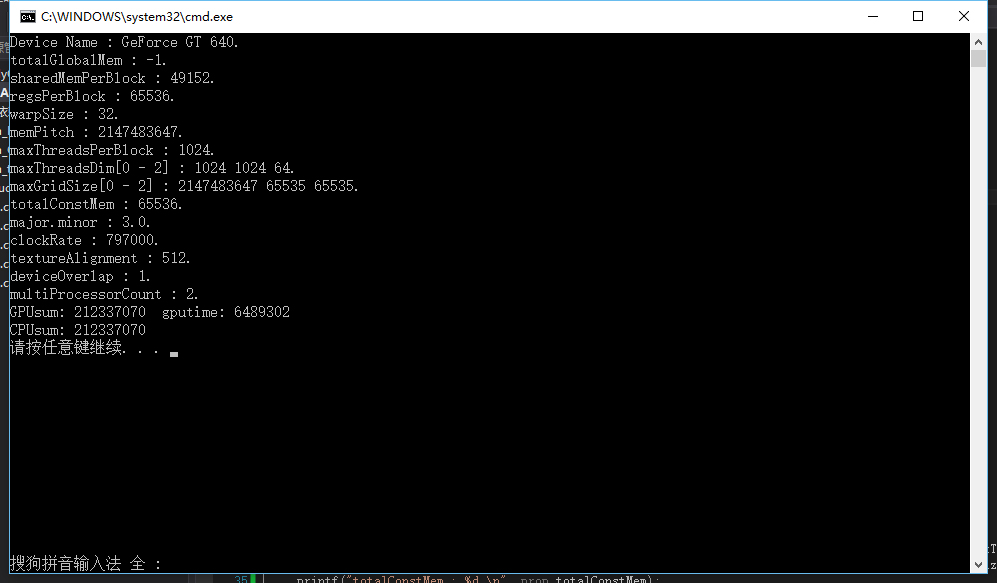
刚才我们使用256个线程使用了13377388个时钟周期,现在1024个线程的最终使用时间又小了一个数量级,达到了6489302
679680304/6489302 = 104.7 13377388/6489302 = 2.06可以看到我们的速度相对于单线程提升了100倍,但是相比256个线程只提升了2倍,我们再从内存带宽的角度来进行一下评估:
使用的时间:
6489302 / (797000 * 1000) = 0.00814S然后计算使用的带宽:
4MB / 0.00814S = 491MB/s我们发现极限线程的情况下带宽仍然不够看,但是大家别忘了,我们之前似乎除了Thread还讲过两个概念,就是Grid和Block,当然另外还有共享内存,这些东西可不会没有他们存在的意义,我们进一步并行加速就要通过他们。另外之前也提到了很多优化步骤,每个步骤中都有大量的优化手段,所以我们仅仅用了线程并行这一个手段,显然不可能一蹴而就。
总结:
这篇博客主要讲解了怎么去使用Thread去简单的并行我们的程序,虽然我们的程序运行速度有了50甚至上百倍的提升,但是根据内存带宽来评估的化我们的程序还远远不够,甚至离1G/S的水平都还差不少,所以我们的优化路还有很长。
虽然我们现在想到除了使用多个Thread外,我们还可以去使用多个block,让每个block包含大量的线程,我们的线程数将成千上万,毫无疑问这对提升带宽是很有用的,但是我们下一步先把这个事情放一放,为了让大家印象深刻,我们插播一个访存方面非常重要的优化,同样可以大幅提高程序的性能。
希望我的博客能帮助到大家~
参考资料:《深入浅出谈CUDA》
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/127496.html原文链接:https://javaforall.net


