
大家好,又见面了,我是你们的朋友全栈君。
数组:其实所谓的数组指的就是一组相关类型的变量集合,并且这些变量彼此之间没有任何的关联。存储区间连续,占用内存严重,数组有下标,查询数据快,但是增删比较慢;
链表:一种常见的基础数据结构,是一种线性表,但是不会按照线性的顺序存储数据,而是每一个节点里存到下一个节点的指针。存储区间离散,占用内存比较宽松,使用链表查询比较慢,但是增删比较快;
哈希表:Hash table 既满足了数据的快速查询(根据关键码值key value 而直接进行访问的数据结构),也不会占用太多的内存空间,十分方便。哈希表是数组加链表组成。
HashMap结构及原理
HashMap是基于哈希表的Map接口的非同步实现。实现HashMap对数据的操作,允许有一个null键,多个null值。
HashMap底层就是一个数组结构,数组中的每一项又是一个链表。数组+链表结构,新建一个HashMap的时候,就会初始化一个数组。Entry就是数组中的元素,每个Entry其实就是一个key-value的键值对,它持有一个指向下一个元素的引用,这就构成了链表,HashMap底层将key-value当成一个整体来处理,这个整体就是一个Entry对象。HashMap底层采用一个Entry【】数组来保存所有的key-value键值对,当需要存储一个Entry对象时,会根据hash算法来决定在其数组中的位置,在根据equals方法决定其在该数组位置上的链表中的存储位置;当需要取出一个Entry对象时,也会根据hash算法找到其在数组中的存储位置, 在根据equals方法从该位置上的链表中取出Entry;
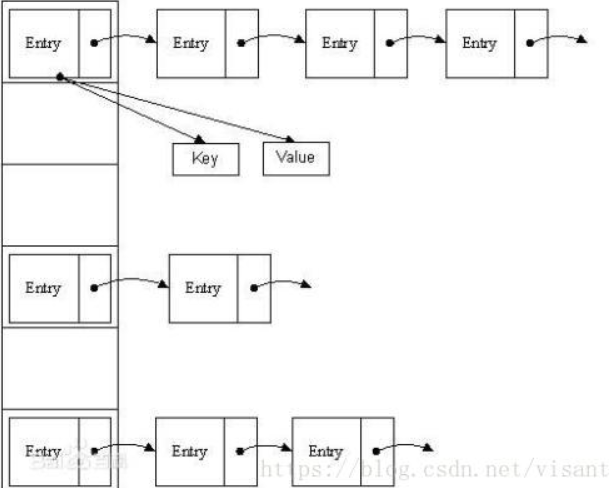

HashMap的存储
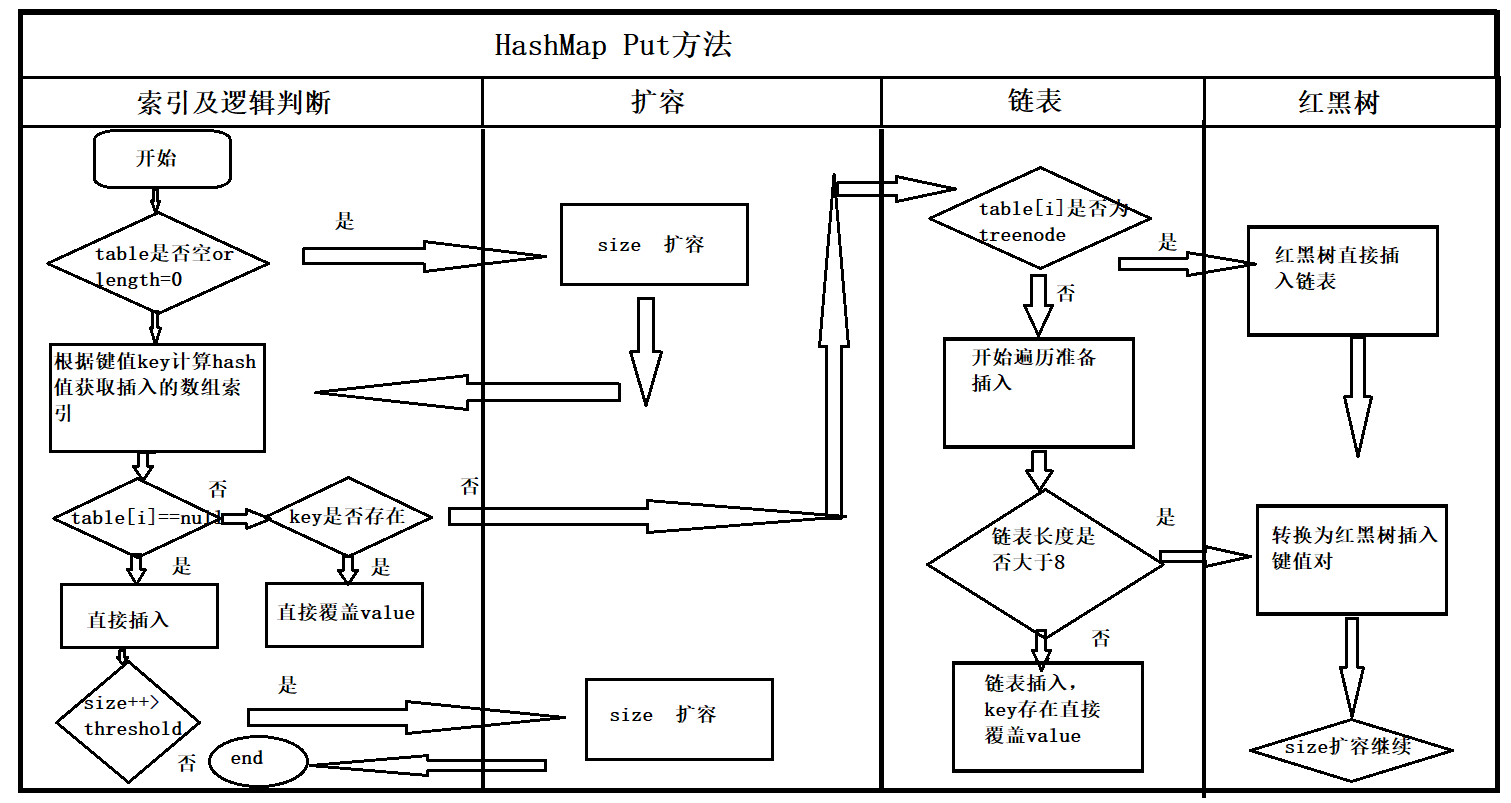
put:(key-value)方法是HashMap中最重要的方法,使用HashMap最主要使用的就是put,get两个方法。
- 判断键值对数组table[i]是否为空或者为null,否则执行resize()进行扩容;
- 根据键值key计算hash值得到插入的数组索引 i ,如果table[i] == null ,直接新建节点添加即可,转入6,如果table[i] 不为空,则转向3;
- 判断table[i] 的首个元素是否和key一样,如果相同(hashCode和equals)直接覆盖value,否则转向4;
- 判断table[i] 是否为treeNode,即table[i]是否为红黑树,如果是红黑树,则直接插入键值对,否则转向5;
- 遍历table[i] ,判断链表长度是否大于8,大于8的话把链表转换成红黑树,进行插入操作,否则进行链表插入操作;便利时遇到相同key直接覆盖value;
- 插入成功后,判断实际存在的键值对数量size是否超过了threshold,如果超过,则扩容;
看一下put源码

get方法取值过程:
int hash = key.hashCode();
int index = hash%Entry[].length;
- 指定key通过hash函数得到key的hash值;
- 调用内部方法getNode(),得到桶号(一般为hash值对桶数求摸);
- 比较桶的内部元素是否和key相等,如不相等,则没有找到,相等,则取出相等记录的value;
- 如果得到key所在桶的头结点恰好是红黑树节点,就调用红黑树节点的getTreeNode()方法,否则就遍历链表节点。getTreeNode()方法通过调用树形节点的find()方法进行查找。由于之前添加时已经保证这个树是有序的,因此查找时基本就是折半查找,效率高;
- 如果对比节点的哈希值和要查找的哈希值相等,就会判断key是否相等,相等就直接返回;不相等就从子树中递归查找;
HashMap中直接地址用hash函数生成,冲突用比较函数解决。如果每个桶内部只有一个元素,那么查找的时候只有一次比较。当许多桶内没有值得时候,许多查询就会更快
addEntry方法
- 添加新元素前,判断是否需要对map的数组进行扩容,如果需要扩容,则扩容多大?
- 对于新增key-value键值对,如果可以的hash值相同,则构造单向列表;
源码分析:

createEntry
该方法主要完成两个功能,一个是添加新的key到Entry数组中,第二个就是对于不同的key的hash值相同的情况下,在同一个数组下标出,构建单向链表进行存储;
源码如下:

HashMap碰撞以及解决方法(开放定址法,在哈希法,链地址法,建立一个公共溢出区)
当两个对象的hashCode相同时,他们的bucket位置相同,hash碰撞就会发生。因为HashMap使用LinkedList存储对象,这个Entry(存储键值对的Map.Entry对象)会存储在LinkedList中。这两个对象算hashCode相同,但是他们可能并不相等。那么如何获取这两个对象的值呢?当我们调用get()方法,HashMap会使用键值对象的hashCode找到bucket位置,遍历LinkedList一直找到值对象。找到bucket位置以后,会调用keys.equals()方法去找到LinkedList中正确的节点,最终找到要找的值对象,使用final修饰,并采用合适的equals()和hashCOde()方法,减少碰撞。
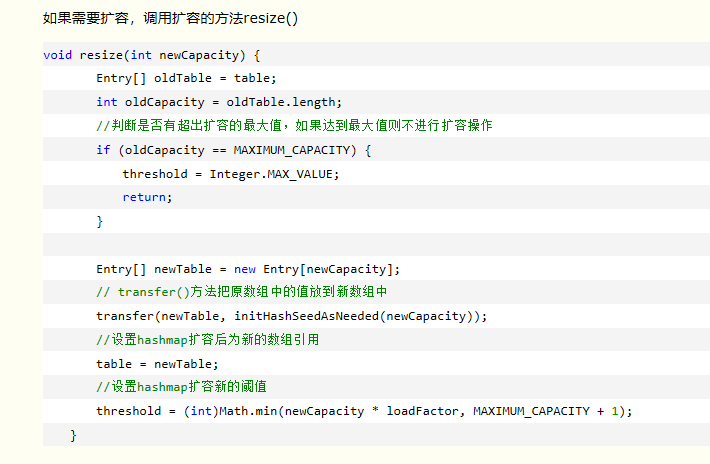
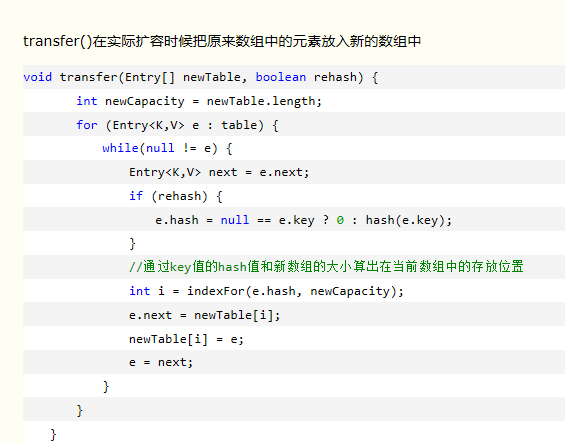
HashMap扩容机制
扩容必须满足两个条件
- 存放新值的时候当前已有元素必须大于阈值;
- 存放新值的时候当前存放数据发生hash碰撞(当前key计算的hash值计算出的数组索引位置已经存在值)
- HashMap在添加值的时候,它默认能存储16个键值对,直到你使用这个HashMap时,它才会给HashMap分配16个键值对的存储空间,(负载因子为0.75,阈值为12),当16个键值对已经存储满了,我们在添加第17个键值对的时候才会发生扩容现象,因为前16个值,每个值在底层数组中分别占据一个位置,并没有发生hash碰撞。
- HashMap也有可能存储更多的键值对,最多可以存储26个键值对,我们来算一下:存储的前11个值全部发生hash碰撞,存到数组的同一个位置中,(这时元素个数小于阈值12,不会扩容),之后存入15个值全部分散到数组剩下的15个位置中,(这时元素个数大于等于阈值,但是每次存入元素并没有发生hash碰撞,不会扩容),11+15=26,当我们存入第27个值得时候满足以上两个条件,HashMap才会发生扩容;

发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/127646.html原文链接:https://javaforall.net


