
大家好,又见面了,我是你们的朋友全栈君。
前言
这一段时间爬取一些数据的时候遭到了封ip。免费的ip满足不了我的需求并且不是很稳定,所以选择的代理ip,我买了一天2000ip,这些对于我的小爬爬就够了。记录了第一次使用代理ip的一些坎坷和经历,希望能够减少初学者的坑。
更新:在使用代理是如果频率过快返回的是‘{“code”:“3001”,“msg”:“提取频繁请按照规定频率提取!”}’不可将该msg添加到ip池中,故需要先判断返回状态。
在使用代理ip之前,首先要了解几样东西:
- 一:
对返回ip格式的操作,很显然xx代理是给出json格式的数据,可以直接请求后返回json数据进行操作包过提取,删除,增加。当然,在实际使用ip代理的时候最好先在浏览器中请求一次,复制下来新建一个py文件练习对其操作。 - 二:
ip的有效期,现在大部分的ip代理都是有有效期的,我买的就是1-5分钟的有效期(蘑菇的有效期其实还是挺长的),当ip失效后你需要将此ip从ip池中删除。当ip不够的时候又要引入新的ip添加到当前的ip池中。要动态维护ip池。 - 三:python3使用代理ip的方式:下文会介绍,以前我的python3使用代理ip也有格式,你爬取的是http用http,是https用https就行。
- 四:
异常处理,再写爬虫的时候一定要对所有可能产生异常的操作进行try except的异常处理。异常又要注意是否为超时异常,还是ip不可用,过期的异常,还是操作dom树的时候产生的异常。不同的异常要采用不同的策略。(可用状态码,全局变量判断)。 - 五:注意使用信息和要求:我买的那个xx代理不能请求频率超过5s。还有就要有添加本地ip地址。(可能是基于安全考虑)
- 六:分析目标网站对ip的需求。你需要设置ip池的最小和请求ip的个数不至于太大或太小,可以预先测试。打个比方你爬的网站同一个时段10个ip更换就不够了。你不至于开100个ip去爬吧,ip过期而没咋么用就是对资源的浪费(当然土豪请随意。)
我个人的解决方向:
- 先写个小程序操作返回的json数据测试。
- 设置全局的列表ipdate[],全局的一个msg{}字典(其实字典就是列表中随机选的一个ip和端口,只不过通过记录标记可以很好的进行删除操作?),
- 将请求ip的操作添加到全局列表(数组)中写成一个loadip()函数,以便判断ip不够时候即使添加(列表extend方法了解下,不是append哦)。
- 写一个随机选ip的函数getproxies(),更换proxies{}里面的内容。同时msg也要更换。注意python函数改变全局变量需要在函数里先global msg声明。每次进行http(s)请求前执行一次更新操作。
- 所有的操作都在try excpet操作,对不同的异常采用不同处理。比如(有的因为ip异常没爬到需要从爬,而有的因为dom结构异常就需要跳过)。
当然实际处理可能会遇到各种问题,比如页面跳转重定向,ssl证书,有的网站也会卡浏览器名称,或者cookie。这里不做过多介绍了。
下面附上详细步骤:
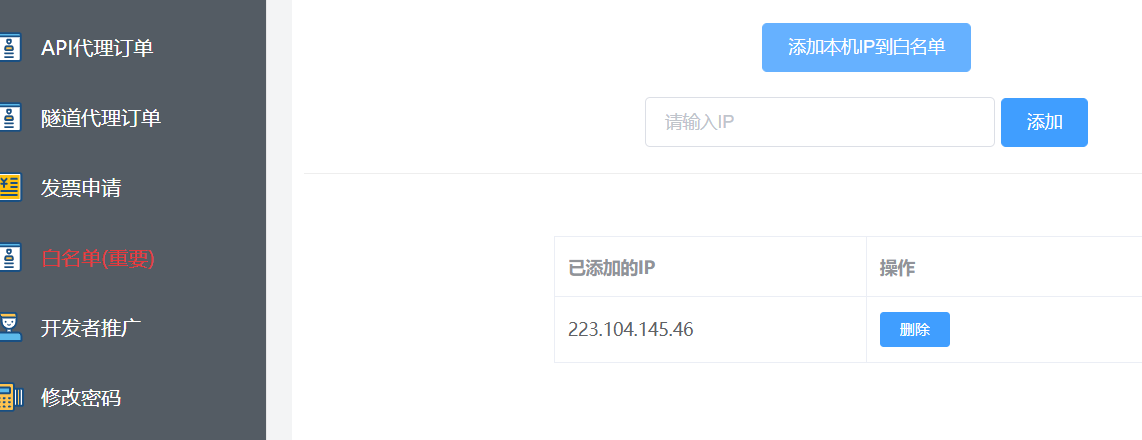
- 添加白名单:

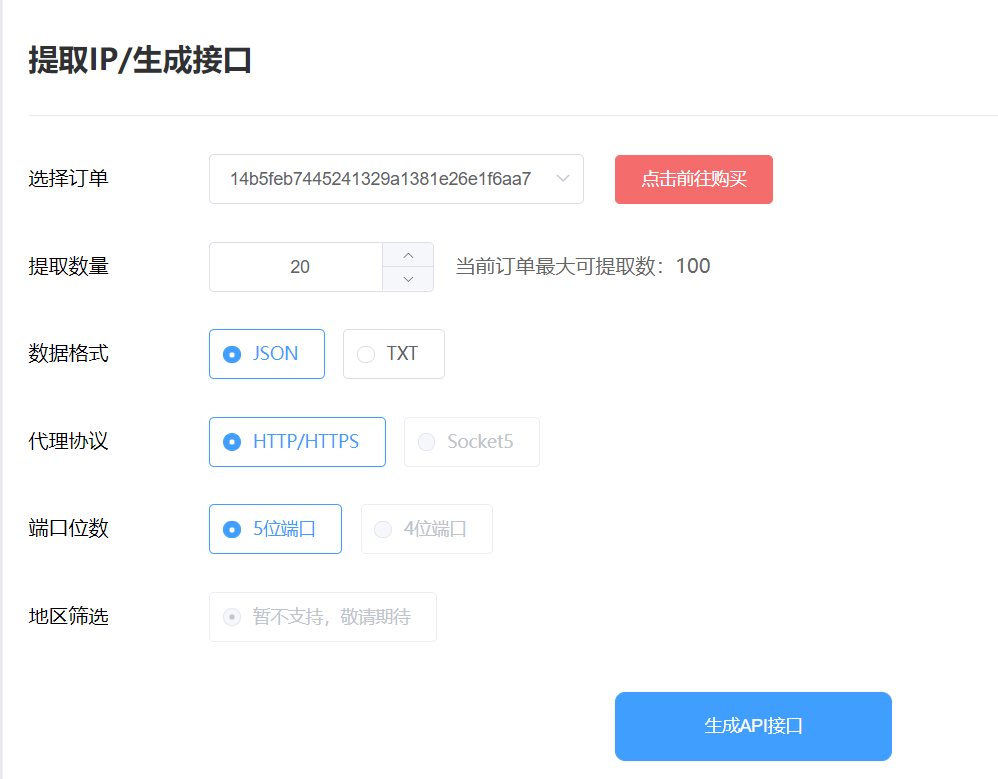
- 提取api:
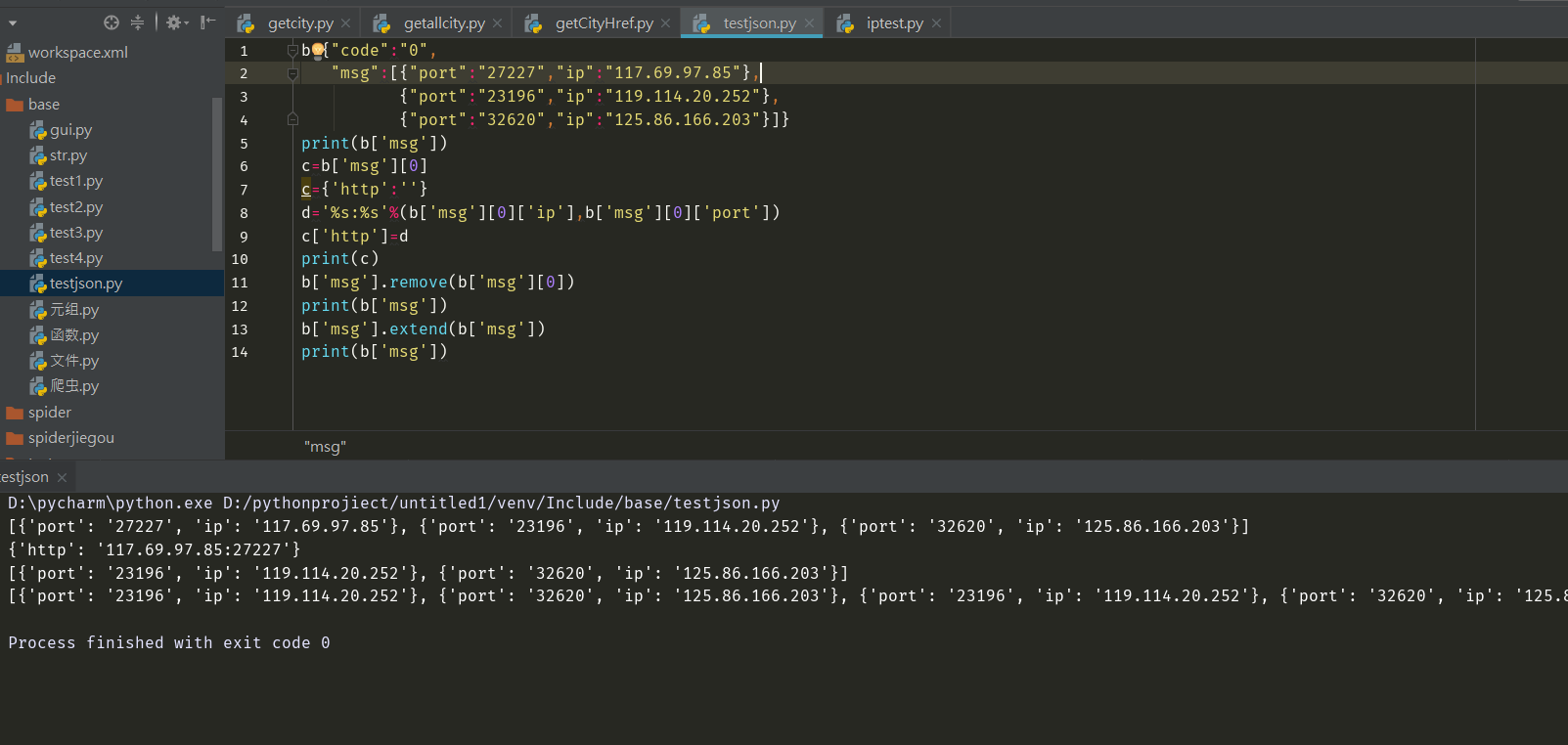
- 写一个py文件测试自己的接口返回的文件
- 测试无误后可接入爬虫程序:附上我的demo(爬取马蜂窝)后面会写具体操作,这里不讲爬虫的思路。
import requests
from bs4 import BeautifulSoup
import pymysql
import re
import json
import time
import random
# 打开数据库连接
db = pymysql.connect(host="localhost", user="root",
password="123456", db="date", port=3306)
ipdate=[]
msg={
}
proxies = {
'http': ''}
stadus=0
def loadip():
url='http://piping.mogumiao.com/proxy/api/get_ip_bs?appKey=14b5feb7445241329a1381e26e1f6aa7&count=20&expiryDate=0&format=1&newLine=2'
req=requests.get(url)
date=req.json()
ipdate2=date['msg']
global ipdate
ipdate.extend(ipdate2)
print(ipdate)
def getproxies():
b=random.choice(ipdate)
d = '%s:%s' % (b['ip'], b['port'])
global proxies
proxies['http']=d
global msg
msg=b
# 使用cursor()方法获取操作游标
cur = db.cursor()
header={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
def jud(cityid):
try:
url='http://www.mafengwo.cn/travel-scenic-spot/mafengwo/'+str(cityid)+'.html'
if(len(ipdate)<30):#拓展ip池
loadip()
getproxies()
req=requests.get(url,headers=header,proxies=proxies,timeout=2,allow_redirects=False)
global stadus
stadus=req.status_code
print(cityid,stadus)
if stadus==200:#请求成功
html=req.text
soup=BeautifulSoup(html,'lxml')
href=soup.find(attrs={
'class':'navbar clearfix'})
infourl='http://www.mafengwo.cn'+str(href.find(attrs={
'data-cs-p':'概况'}).get('href'))#主要信息
viewhref='http://www.mafengwo.cn'+str(href.find(attrs={
'data-cs-p':'景点'}).get('href'))#景点信息
foodhref='http://www.mafengwo.cn'+str(href.find(attrs={
'data-cs-p':'餐饮'}).get('href'))#餐饮信息'
updatehref="update cityhref set infohref='%s',viewhref='%s',foodhref='%s' where city_id=%d"%(infourl,viewhref,foodhref,cityid)
print(cityid,foodhref,len(ipdate))
try:
cur.execute(updatehref)
db.commit()
except Exception as e:
print(updatehref,e)
db.rollback()
stadus=0
except Exception as e3:
if ( stadus == 301 or stadus==302 or stadus==200):
print('no prbo',cityid,stadus)
else:
print(e3, cityid, stadus)
try:
print('remove')
ipdate.remove(msg)
# ipdate.remove(msg)
except Exception as e6:
print(e6)
jud(cityid)
loadip()#先填充一部分ip
time.sleep(5)#休眠五秒
sql='select city_id,infohref from cityhref'
cur.execute(sql)
value=cur.fetchall()
# for cityid in value:
# if(cityid[1]==None):
# print('start:',cityid[0])
# jud(cityid[0])
#jud(64641)
# jud(5429475)
db.close()
有些核心部分已经被注释掉,如果有其他问题可以一起交流。总的来说蘑菇代理还是不错的,可用率还行,时间也没那么苛刻。
如果对后端、爬虫、数据结构算法等感性趣欢迎关注我的个人公众号交流:bigsai
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/128201.html原文链接:https://javaforall.net


