
大家好,又见面了,我是你们的朋友全栈君。
众所周知,集成学习算法,它将多个弱分类器集成起来,以达到较高的分类准确率。
常见的集成学习方法:
- boosting
- bagging
- stacking
今天主要讲stacking.
Stacking 的基本思想
将个体学习器结合在一起的时候使用的方法叫做结合策略。对于分类问题,我们可以使用投票法来选择输出最多的类。对于回归问题,我们可以将分类器输出的结果求平均值。
上面说的投票法和平均法都是很有效的结合策略,还有一种结合策略是使用另外一个机器学习算法来将个体机器学习器的结果结合在一起,这个方法就是Stacking。
在stacking方法中,我们把个体学习器叫做初级学习器,用于结合的学习器叫做次级学习器或元学习器(meta-learner),次级学习器用于训练的数据叫做次级训练集。次级训练集是在训练集上用初级学习器得到的。
stacking学习算法。

过程1-3 是训练出来个体学习器,也就是初级学习器。
过程5-9 是 使用训练出来的个体学习器来得预测的结果,这个预测的结果当做次级学习器的训练集。
过程11 是用初级学习器预测的结果训练出次级学习器,得到我们最后训练的模型。
如果想要预测一个数据的输出,只需要把这条数据用初级学习器预测,然后将预测后的结果用次级学习器预测便可。
——来自周志华老师《机器学习》
Stacking的实现
最先想到的方法是这样的,
- 用数据集D来训练h1,h2,h3…,
- 用这些训练出来的初级学习器在数据集D上面进行预测得到次级训练集。
- 用次级训练集来训练次级学习器。
但是这样的实现是有很大的缺陷的。在原始数据集D上面训练的模型,然后用这些模型再D上面再进行预测得到的次级训练集肯定是非常好的。会出现过拟合的现象。
Stacking是模型融合的一个重要的方法,几乎每个数据科学竞赛的前几名都会使用,接下来我主要是介绍stacking的原理。
相信大家看很多stacking的资料都会看到下面的这个图:
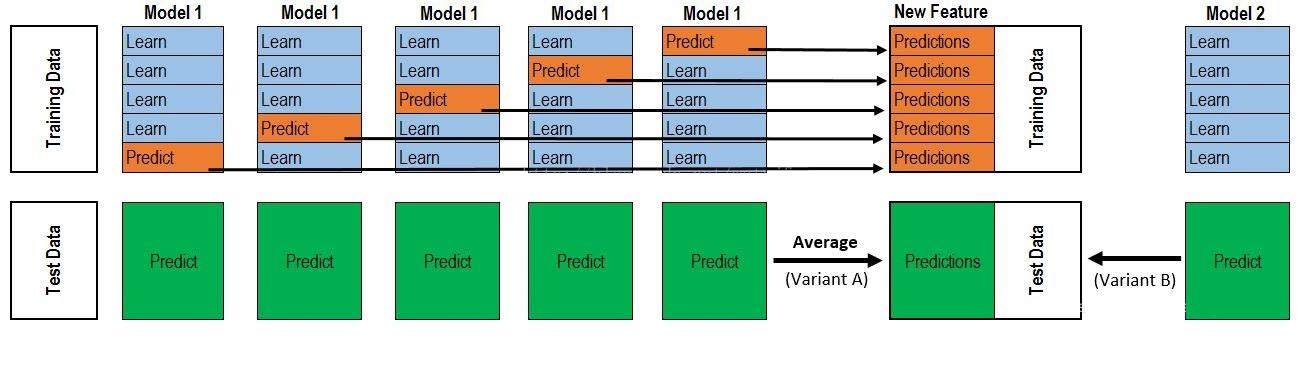
这个图很形象,他具体是这样做的(交叉验证):
首先我们将训练集使用kfold切分为k分,每一分包括一个验证集和测试集,每次取其中k-1分训练,另外的1分用来验证,stacking是这样做的。
比如对于集成的第一个模型,clf1,我们使用kfold交叉验证,那么可以得到k个clf1模型,模型的类型是一样的,但是模型里面学到的参数不一样,因为他们的训练集是不一样的,对与每一折的训练,我们还有一个验证集啊,那么我们用训练得到的模型在验证集合上做一次预测,你想,因为这个时候我们的验证集是不是只有1分,也就是只有train_set_number/k个样本(train_set_number表示训练样本的个数),但是这只是一折啊,我们还有k折,每一折我们都会在验证集上预测,所以最终对于clf1在验证集上得到是不是train_set_number个结果,不用担心是没有重复的,因为你是kflod。
是不是每一折的验证集样本都不会相同,也就是没有哪个样本同时出现在两个验证集上,这样下来,我们就得到第一级的结果,也是train_set_number个结果。
然后在每一折上,我们在测试集上做一次预测,那么k个clf1模型预测k次得到了k个结果,也就是每一个样本预测结果有k个,我们就取一下平均,看到是取平均,这样取完平均以后每一个样本在clf1模型上就得到一个预测结果。这只是一个模型的过程,因为我们需要集成很多个模型,那么我重复n个模型,做法和上面是一样的,假设我们有n个模型,那么请问我们stacking第一层出来,在验证集上得到的结果特征是什么维度?应该就是训练样本的个数行(train_set_number),列数就是n吧,因为n个模型啊,这就是我们对第一层结果的一个特征堆叠方法,这样第一层出来的结果又可以作为特征训练第二层,第二层任然可以使用stacking多个模型,或者直接接一个模型用于训练,然后直接预测。那么同样,对于测试集第一层出来的维度是不是(test_set_number,n),也就是测试集样本的行数,这样是不是可以用第二层训练的模型在这个上面预测,得到我们最后的结果。这个就是stacking的整个过程。
然后我们看一段stacking的代码:
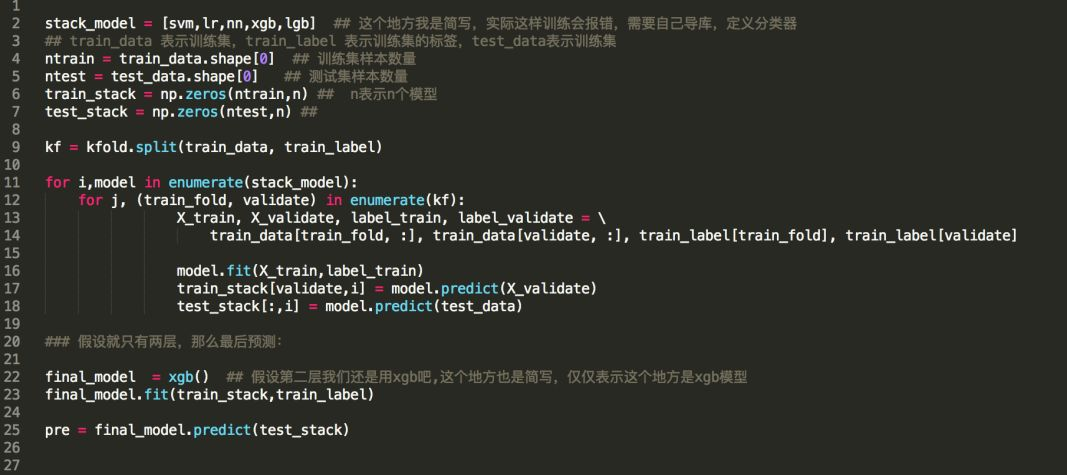
构造stacking类
事实上还可以构造一个stacking的类,它拥有fit和predict方法

参考:
https://www.cnblogs.com/jiaxin359/p/8559029.html
https://zhuanlan.zhihu.com/p/32896968
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/128248.html原文链接:https://javaforall.net


