
大家好,又见面了,我是你们的朋友全栈君。
时间序列预测(四)—— LSTM模型
欢迎大家来我的个人博客网站观看原文:https://xkw168.github.io/2019/05/20/时间序列预测-四-LSTM模型.html
文章链接
模型原理
LSTM(Long-short time memory,LSTM)模型,亦即是长段时间模型。LSTM的原理这篇博客讲的十分的清楚,建议英语好的小伙伴直接去看原文,我这里就大致的翻译精简一下。
人类天生具备的一个能力就是记忆的持久性,可以根据过往经验,从而推断出当前看到的内容的实际含义。如看电影的时候可以通过先前时间去推断后续事件;看一篇文章的时候,同样可以通过过往的知识积累去推断文章中每个词语的含义。而传统的神经网络并没有“持久性”,每一个神经元不能通过前面神经元的结果进行推断,为了解决这一问题科学家提出了递归神经网络(Recurrent Neural Networks,RNN)。RNN是包含循环的神经网络(如图所示),允许信息的持久化。其中A可以看作神经网络的一个缩影,接受某时刻的输入 X t X_t Xt然后输出对应的结果 h t h_t ht,一个回路可以允许信息从一步传递到另一步。
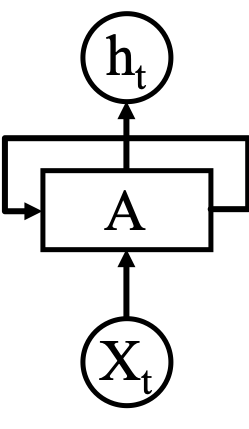

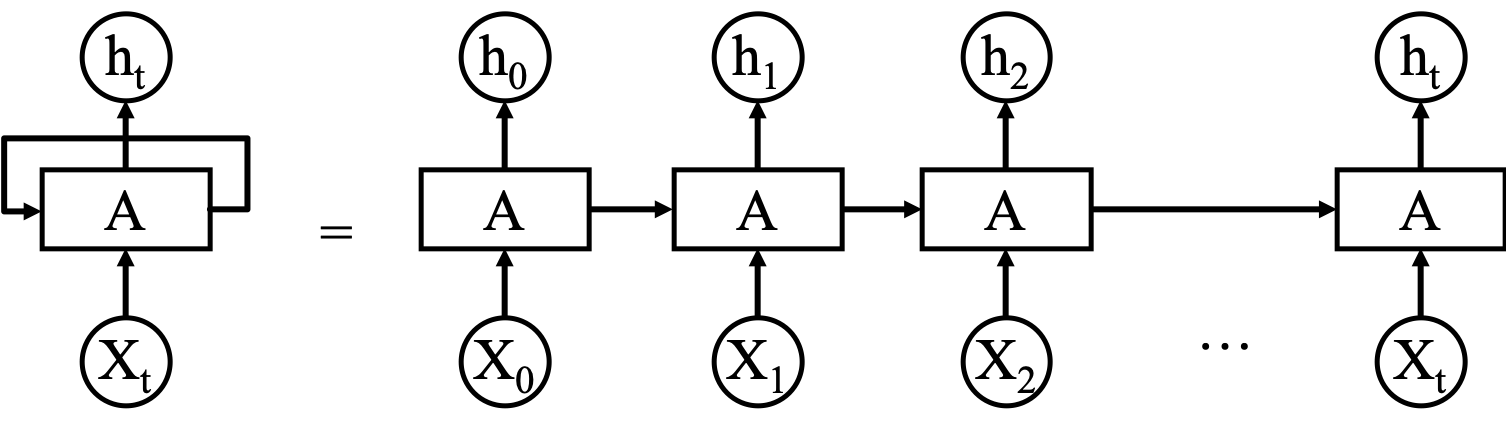
为了更直观的展示,将回路拆分开来,用一个连续的序列进行表示(如图所示)。一个循环神经网络可以看作是若干个相同的基本单元连接起来,每一个基本单元都可以将信息传递到下一个基本单元。
常规的RNN存在一个问题就是,无法解决“长期依赖”(long-term dependency)问题,即有用信息和预测点相隔较远。以词语预测为例,“我来自中国,我会讲中文”,这句话里面有用信息与预测点相隔较近,RNN可以很轻易的推断出下一个词语应该是中文,但假如有用信息与预测点相隔较远,如“我来自中国……我会讲中文”,此时RNN便无法推断出接下来的词语。换句话说,RNN的信息持久性不够高,不能保持几十甚至上百步。
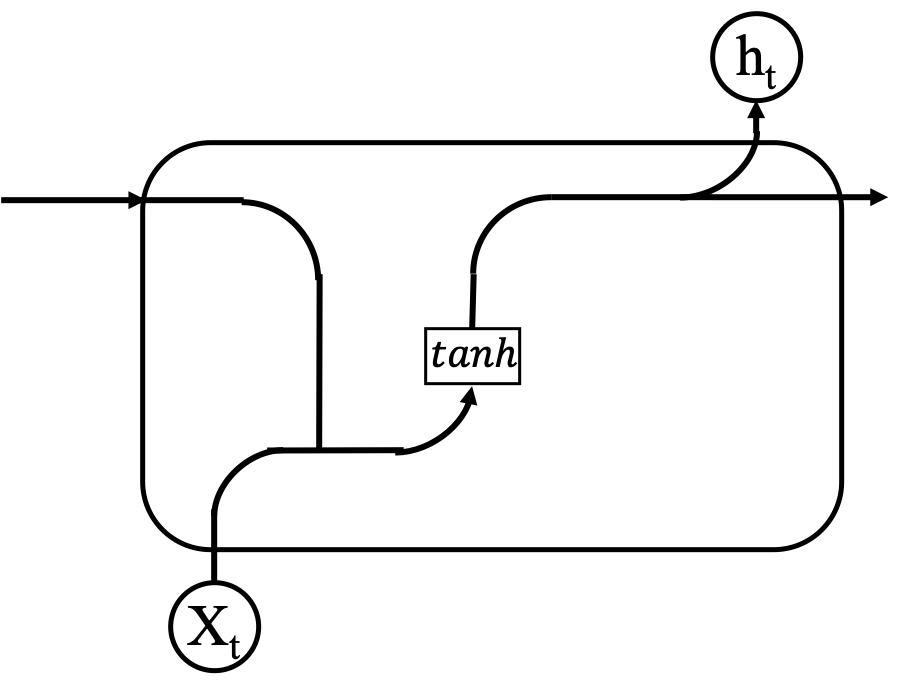
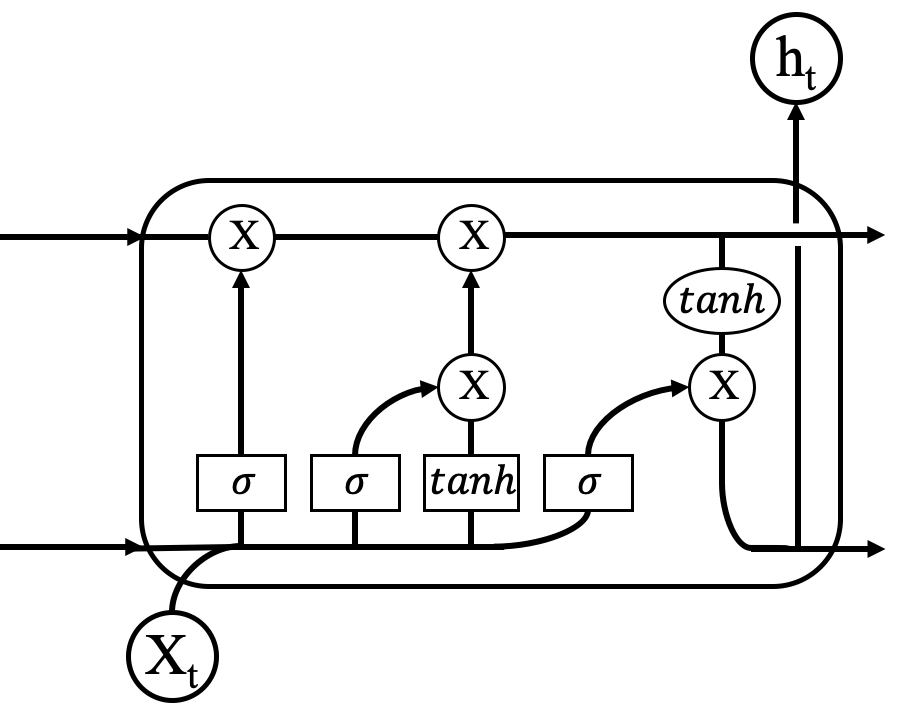
为了弥补传统RNN的这个缺点,人们引入了LSTM(long short-term memory)这个模型。LSTM可以看作是一种特殊的RNN,相较于传统RNN,LSTM天生就对长期依赖有着很好的支持。LSTM模型的核心思想主要有两个,分别为记忆元组(memory cell)和非线性的门单元(nonlinear gating unit),其中记忆元组用于保持系统的状态,非线性的门单元用于在每一个时间点调节流入和流出记忆元组的信息。每个递归的神经网络都可以分解成无数个基本重复单元,传统的RNN是这样,LSTM也是如此。在传统的RNN里面,基本重复单元内部结构十分简单,通常只有一个简单的神经网络层(通常为一个tanh模块,如图所示);在LSTM中,使用了四个神经网络层并且彼此之间以一种特殊的关系进行交互(如图所示)。
模型安装
pip install tensorflow
模型实现
这里同样使用的是TensorFlow里面的Timeseries模块实现。
def now():
return datetime.now().strftime("%m_%d_%H_%M_%s")
def parse_result_tf(tf_data):
""" parse the result of model output in tensorflow :param tf_data: the output of tensorflow :return: data in DataFrame format """
return pd.DataFrame.from_dict({
"ds": tf_data["times"].reshape(-1), "y": tf_data["mean"].reshape(-1)})
def generate_time_series(
start_date=datetime(2006, 1, 1),
cnt=4018, delta=timedelta(days=1), timestamp=False
):
""" generate a time series/index :param start_date: start date :param cnt: date count. If =cnt are specified, delta must not be; one is required :param delta: time delta, default is one day. :param timestamp: output timestamp or format string :return: list of time string or timestamp """
def per_delta():
curr = start_date
while curr < end_date:
yield curr
curr += delta
end_date = start_date + delta * cnt
time_series = []
if timestamp:
for t in per_delta():
time_series.append(t.timestamp())
else:
for t in per_delta():
time_series.append(t)
# print(t.strftime("%Y-%m-%d"))
return time_series
def LSTM_predict_tf(train_data, evaluation_data, forecast_cnt=365, freq="D", model_dir=""):
""" predict time series with LSTM model in tensorflow :param train_data: data use to train the model :param evaluation_data: data use to evaluate the model :param forecast_cnt: how many point needed to be predicted :param freq: the interval between time index :param model_dir: directory of pre-trained model(checkpoint, params) :return: """
model_directory = "./model/LSTM_%s" % now()
params = {
"batch_size": 3,
"window_size": 4,
# The number of units in the model's LSTMCell.
"num_units": 128,
# The dimensionality of the time series (one for univariate, more than one for multivariate)
"num_features": 1,
# how many steps we train the model
"global_steps": 3000
}
# if there is a pre-trained model, use parameters from it
if model_dir:
model_directory = model_dir
params = read_model_param(model_dir + "/params.txt")
# create time index for model training(use int)
time_int = range(len(train_data) + len(evaluation_data))
data_train = {
tf.contrib.timeseries.TrainEvalFeatures.TIMES: time_int[:len(train_data)],
tf.contrib.timeseries.TrainEvalFeatures.VALUES: train_data["y"],
}
data_eval = {
tf.contrib.timeseries.TrainEvalFeatures.TIMES: time_int[len(train_data):],
tf.contrib.timeseries.TrainEvalFeatures.VALUES: evaluation_data["y"],
}
reader_train = NumpyReader(data_train)
reader_eval = NumpyReader(data_eval)
""" define in tensorflow/contrib/timeseries/python/timeseries/input_pipeline.py """
train_input_fn = tf.contrib.timeseries.RandomWindowInputFn(
reader_train, batch_size=params["batch_size"], window_size=params["window_size"])
""" define in tensorflow/contrib/timeseries/python/timeseries/estimators.py """
estimator_lstm = ts_estimators.TimeSeriesRegressor(
model=_LSTMModel(num_features=params["num_features"], num_units=params["num_units"]),
optimizer=tf.train.AdamOptimizer(learning_rate=0.01),
model_dir=model_directory
)
if not model_dir:
""" website: https://www.tensorflow.org/api_docs/python/tf/estimator/Estimator#train """
estimator_lstm.train(input_fn=train_input_fn, steps=params["global_steps"])
evaluation_input_fn = tf.contrib.timeseries.WholeDatasetInputFn(reader_eval)
evaluation = estimator_lstm.evaluate(input_fn=evaluation_input_fn, steps=1)
# Predict starting after the evaluation
(predictions,) = tuple(estimator_lstm.predict(
input_fn=tf.contrib.timeseries.predict_continuation_input_fn(
evaluation, steps=forecast_cnt)))
save_model_param(model_directory, params)
if "loss" in evaluation.keys():
print("loss:%.5f" % evaluation["loss"])
f = open(model_directory + "/%s" % evaluation["loss"], "w")
f.close()
model_log(
evaluation["loss"],
average_loss=-1 if "average_loss" not in evaluation.keys() else evaluation["average_loss"],
content=model_dir
)
evaluation = parse_result_tf(evaluation)
predictions = parse_result_tf(predictions)
first_date = evaluation_data["ds"].tolist()[0]
evaluation["ds"] = generate_time_series(first_date, cnt=len(evaluation), delta=delta_dict[freq])
latest_date = evaluation_data["ds"].tolist()[-1]
predictions["ds"] = generate_time_series(latest_date, cnt=len(predictions), delta=delta_dict[freq])
return evaluation, predictions
关键参数
- window_size:“观察窗”大小,用于控制将多少个连续的时间序列放在一起;
- batch_size:批次大小,用于控制将多少个“观察窗”,该值越大,模型训练的时候梯度就会越稳定;
- num_features:与AR模型一致,是时间序列的维度;
- num_units:每个LSTM元组(cell)里面包含多少个基本单元(unit);
- optimizer:优化器的种类;
- learning_rate:学习速率,与模型训练时间成负相关,学习率越大训练时间越短,但是过大的学习率可能会导致模型无法收敛;
- steps:模型的训练迭代次数。
注意由于LSTM模型较为复杂,故当数据量较少而规律不明显的情况下,其模型表现可能不尽人意。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/128267.html原文链接:https://javaforall.net


