
大家好,又见面了,我是你们的朋友全栈君。
本算法是CTR中的系列算法之一,具体的原理就不说了。网上其他的博客一大堆。都是互相抄来抄去,写上去之后容易让人误会。因此我只传上代码实现部分。大家做个参考。
这里我们的FFM算法是基于Tensorflow实现的。
为什么用Tensorflow呢?观察二次项,由于field的引入,Vffm需要计算的参数有 nfk 个,远多于FM模型的 nk个,而且由于每次计算都依赖于乘以的xj的field,所以,无法用fm的计算技巧(ab = 1/2(a+b)^2-a^2-b^2),所以计算复杂度是 O(n^2)。
因此使用Tensorflow的目的是想通过GPU进行计算。同时这也给我们提供了一个思路:如果模型的计算复杂度较高,当不能使用CPU快速完成模型训练时,可以考虑使用GPU计算。比如Xgboost是已经封装好可以用在GPU上的算法库,而那些没有GPU版本的封装算法库时,例如我们此次采用的FFM算法,我们可以借助Tensorflow的GPU版本框架设计算法,并完成模型训练。
代码主要分三部分:
build_data.py
主要是完成对原始数据的转化。主要包括构造特征值对应field的字典。
FFM.py
主要包括线性部分及非线性部分的代码实现。
tools.py
主要包括训练集的构造。
这里我们主要分析 FFM.py,也就是模型的构建过程:
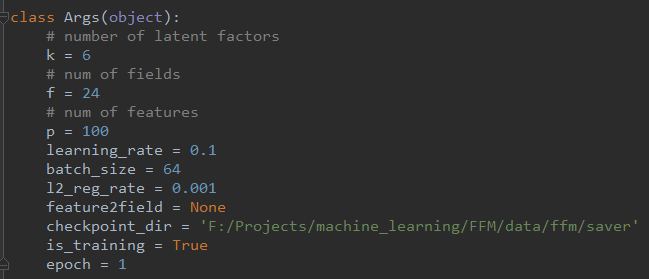
首先初始化一些参数,包括:
- k:隐向量长度
- f :field个数
- p:特征值个数
- 学习率大小
- 批训练大小
- 正则化
- 模型保存位置等
代码如下图所示:

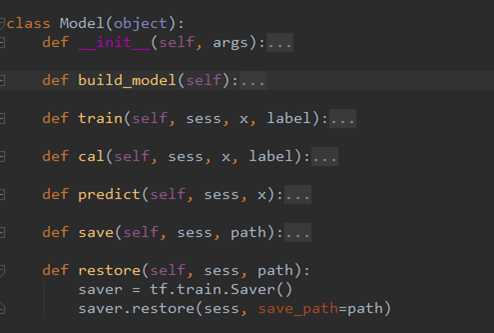
然后,构造了一个model类,主要存放:
- 初始化的一些参数
- 模型结构
- 模型训练op(参数更新)
- 预测op
- 模型保存以及载入的op
代码如下图所示:
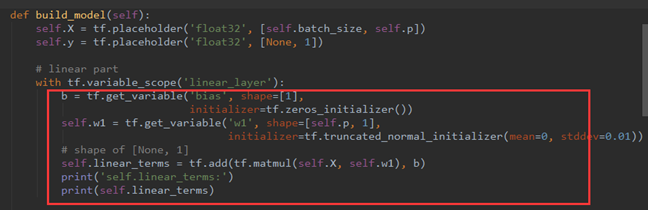
之后,对模型构造部分代码进行分析,可发现模型由两部分组成,第一部分是下图红框内容,其实就是线性表达式 w^Tx+b,其中:
- b shape(None,1)
- x shape (batch_size,p)
- w1 shape(p,1) 注:p为特征值个数
定义变量及初始化后,就可以构造线性模型,代码如下图所示:
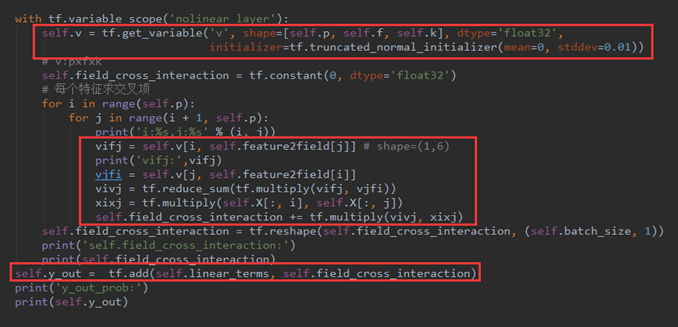
然后,定义一个Vffm变量用来存放交叉项的权重,并初始化。因为我们已经了解到Vffm是一个三维向量,所以,v :shape(p,f,k) 。
之后是vi,fj、vj,fi的构造。因为v 有p行,代表共有p个特征值,所以vifj = v[i, feature2field[j]],说人话就是第i个特征值在第j个特征值对应的field上的隐向量。
vjfi 的构造方法类似,所以vivj就可以求出来.然后就是把交叉项累加,然后 reshape 成(batch_size,1)的形状,以便与线性模型进行矩阵加法计算。
代码如下图所示:
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/131719.html原文链接:https://javaforall.net


