
大家好,又见面了,我是你们的朋友全栈君。
最近因为项目需要所以需要使用kafka 所以自己最近也实践了下。下面为大家简单介绍下在windows下的安装使用
因为它是基于zookepper的使用也要安装zookepper
1.安装Zookeeper
Kafka的运行依赖于Zookeeper,所以在运行Kafka之前我们需要安装并运行Zookeeper
1.1 下载安装文件: http://mirror.bit.edu.cn/apache/zookeeper/
1.2 解压文件(本文解压到 D:\zookeeper-3.4.8)
1.3 打开D:\zookeeper-3.4.8\conf,把zoo_sample.cfg重命名成zoo.cfg
1.4 从文本编辑器里打开zoo.cfg
1.5 修改dataDir和dataLogDir保存路径
dataDir=D:\data\logs\zookeeper
dataLogDir=D:\data\logs\zookeeper
1.6 添加如下系统变量:ZOOKEEPER_HOME: D:\zookeeper-3.4.8
Path: 在现有的值后面添加 ;%ZOOKEEPER_HOME%\bin;
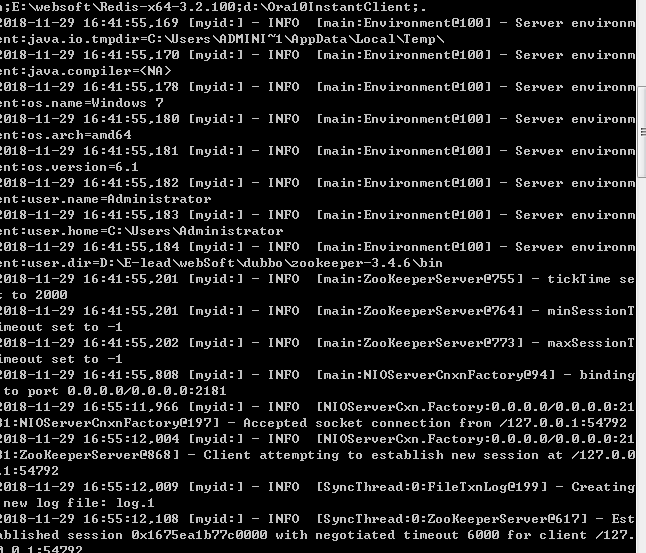
1.7 运行Zookeeper: 打开cmd然后执行zkserver 命令。如果打印以下信息则表示zookeeper已经安装成功并运行在2181端口。

2.安装并运行Kafka
2.1 下载安装文件:http://kafka.apache.org/downloads.html
2.2 解压文件(本文解压到 D:\kafka_2.11-0.10.2.0)
2.3 打开D:\kafka_2.11-0.10.2.0\config\ server.properties
2.4 把 log.dirs的值改成 log.dirs=D:\data\logs\kafka
2.5 D:\kafka_2.11-0.10.2.0\bin文件夹下的.sh命令脚本是在shell下运行的,此文件夹下还有个 windows文件夹,里面是windows下运行的.bat命令脚本
2.6 在D:\kafka_2.11-0.10.2.0文件夹中”Shift+鼠标右键”点击空白处打开命令提示窗口
2.7 输入并执行一下命令以打开kafka:
.\bin\windows\kafka-server-start.bat .\config\server.properties3.创建topics
3.1在\bin\windows文件夹中”Shift+鼠标右键”点击空白处打开命令提示窗口
kafka-topics.bat –create –zookeeper localhost:2181 –replication-factor 1 –partitions 1 –topic test
4.打开一个Producer
4.1\bin\windows文件夹中”Shift+鼠标右键”点击空白处打开命令提示窗口
kafka-console-producer.bat –broker-list localhost:9092 –topic test
1
5.打开一个Consumer
5.1\bin\windows文件夹中”Shift+鼠标右键”点击空白处打开命令提示窗口
kafka-console-consumer.bat --broker-list localhost:9092 --topic test效果: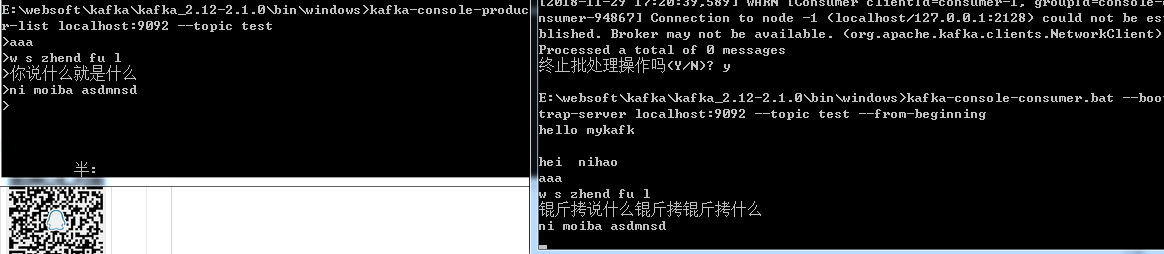
设置多个broker集群
到目前,我们只是单一的运行一个broker,没什么意思。对于Kafka,一个broker仅仅只是一个集群的大小,所有让我们多设几个broker。
首先为每个broker创建一个配置文件:
> cp config/server.properties config/server-1.properties
> cp config/server.properties config/server-2.properties
现在编辑这些新建的文件,设置以下属性:
config/server-1.properties:
broker.id=1
listeners=PLAINTEXT://:9093
log.dir=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2
listeners=PLAINTEXT://:9094
log.dir=/tmp/kafka-logs-2
broker.id是集群中每个节点的唯一且永久的名称,我们修改端口和日志目录是因为我们现在在同一台机器上运行,我们要防止broker在同一端口上注册和覆盖对方的数据。
我们已经运行了zookeeper和刚才的一个kafka节点,所有我们只需要在启动2个新的kafka节点。
> bin/kafka-server-start.sh config/server-1.properties &
...
> bin/kafka-server-start.sh config/server-2.properties &
...
现在,我们创建一个新topic,把备份设置为:3
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
好了,现在我们已经有了一个集群了,我们怎么知道每个集群在做什么呢?运行命令“describe topics”
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
输出解释:第一行是所有分区的摘要,其次,每一行提供一个分区信息,因为我们只有一个分区,所以只有一行。
- “leader”:该节点负责该分区的所有的读和写,每个节点的
leader都是随机选择的。 - “replicas”:备份的节点列表,无论该节点是否是leader或者目前是否还活着,只是显示。
- “isr”:“同步备份”的节点列表,也就是活着的节点并且正在同步leader。
我们运行这个命令,看看一开始我们创建的那个节点:
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
这并不奇怪,刚才创建的主题没有Replicas,并且在服务器“0”上,我们创建它的时候,集群中只有一个服务器,所以是“0”。
让我们来发布一些信息在新的topic上:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic
...
my test message 1
my test message 2
^C
现在,消费这些消息。
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic
...
my test message 1
my test message 2
^C
我们要测试集群的容错,kill掉leader,Broker1作为当前的leader,也就是kill掉Broker1。
> ps | grep server-1.properties
7564 ttys002 0:15.91 /System/Library/Frameworks/JavaVM.framework/Versions/1.6/Home/bin/java...
> kill -9 7564
在Windows上使用:
> wmic process where "caption = 'java.exe' and commandline like '%server-1.properties%'" get processid
ProcessId
6016
> taskkill /pid 6016 /f
备份节点之一成为新的leader,而broker1已经不在同步备份集合里了。
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 1,2,0 Isr: 2,0
但是,消息仍然没丢:
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic
...
my test message 1
my test message 2
^C
Step 7: 使用 Kafka Connect 来 导入/导出 数据
从控制台写入和写回数据是一个方便的开始,但你可能想要从其他来源导入或导出数据到其他系统。对于大多数系统,可以使用kafka Connect,而不需要编写自定义集成代码。
Kafka Connect是导入和导出数据的一个工具。它是一个可扩展的工具,运行连接器,实现与自定义的逻辑的外部系统交互。在这个快速入门里,我们将看到如何运行Kafka Connect用简单的连接器从文件导入数据到Kafka主题,再从Kafka主题导出数据到文件。
首先,我们首先创建一些“种子”数据用来测试,(ps:种子的意思就是造一些消息,片友秒懂?):
echo -e "foo\nbar" > test.txt
windowns上:
> echo foo> test.txt
> echo bar>> test.txt
接下来,我们开始2个连接器运行在独立的模式,这意味着它们运行在一个单一的,本地的,专用的进程。我们提供3个配置文件作为参数。首先是Kafka Connect处理的配置,包含常见的配置,例如要连接的Kafka broker和数据的序列化格式。其余的配置文件都指定了要创建的连接器。包括连接器唯一名称,和要实例化的连接器类。以及连接器所需的任何其他配置。
> bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
kafka附带了这些示例的配置文件,并且使用了刚才我们搭建的本地集群配置并创建了2个连接器:第一个是源连接器,从输入文件中读取并发布到Kafka主题中,第二个是接收连接器,从kafka主题读取消息输出到外部文件。
在启动过程中,你会看到一些日志消息,包括一些连接器实例化的说明。一旦kafka Connect进程已经开始,导入连接器应该读取从
test.txt
和写入到topic
connect-test
,导出连接器从主题
connect-test
读取消息写入到文件
test.sink.txt
. 我们可以通过验证输出文件的内容来验证数据数据已经全部导出:
more test.sink.txt
foo
bar
注意,导入的数据也已经在Kafka主题
connect-test
里,所以我们可以使用该命令查看这个主题:
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic connect-test --from-beginning
{"schema":{"type":"string","optional":false},"payload":"foo"}
{"schema":{"type":"string","optional":false},"payload":"bar"}
...
连接器继续处理数据,因此我们可以添加数据到文件并通过管道移动:
echo "Another line" >> test.txt
你应该会看到出现在消费者控台输出一行信息并导出到文件。
Step 8: 使用Kafka Stream来处理数据
Kafka Stream是kafka的客户端库,用于实时流处理和分析存储在kafka broker的数据,这个快速入门示例将演示如何运行一个流应用程序。一个WordCountDemo的例子(为了方便阅读,使用的是java8 lambda表达式)
KTable wordCounts = textLines
// Split each text line, by whitespace, into words.
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("W+")))
// Ensure the words are available as record keys for the next aggregate operation.
.map((key, value) -> new KeyValue<>(value, value))
// Count the occurrences of each word (record key) and store the results into a table named "Counts".
.countByKey("Counts")
它实现了wordcount算法,从输入的文本计算出一个词出现的次数。然而,不像其他的WordCount的例子,你可能会看到,在有限的数据之前,执行的演示应用程序的行为略有不同,因为它的目的是在一个无限的操作,数据流。类似的有界变量,它是一种动态算法,跟踪和更新的单词计数。然而,由于它必须假设潜在的无界输入数据,它会定期输出其当前状态和结果,同时继续处理更多的数据,因为它不知道什么时候它处理过的“所有”的输入数据。
现在准备输入数据到kafka的topic中,随后kafka Stream应用处理这个topic的数据。
> echo -e "all streams lead to kafka\nhello kafka streams\njoin kafka summit" > file-input.txt
接下来,使用控制台的producer 将输入的数据发送到指定的topic(streams-file-input)中,(在实践中,stream数据可能会持续流入,其中kafka的应用将启动并运行)
> bin/kafka-topics.sh --create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 1 \
--topic streams-file-input
> cat /tmp/file-input.txt | ./bin/kafka-console-producer --broker-list localhost:9092 --topic streams-file-input
现在,我们运行 WordCount 处理输入的数据:
> ./bin/kafka-run-class org.apache.kafka.streams.examples.wordcount.WordCountDemo
不会有任何的STDOUT输出,除了日志,结果不断地写回另一个topic(streams-wordcount-output),demo运行几秒,然后,不像典型的流处理应用程序,自动终止。
现在我们检查WordCountDemo应用,从输出的topic读取。
> ./bin/kafka-console-consumer --zookeeper localhost:2181
--topic streams-wordcount-output
--from-beginning
--formatter kafka.tools.DefaultMessageFormatter
--property print.key=true
--property print.key=true
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
输出数据打印到控台(你可以使用Ctrl-C停止):
all 1
streams 1
lead 1
to 1
kafka 1
hello 1
kafka 2
streams 2
join 1
kafka 3
summit 1
^C
第一列是message的key,第二列是message的value,要注意,输出的实际是一个连续的更新流,其中每条数据(即:原始输出的每行)是一个单词的最新的count,又叫记录键“kafka”。对于同一个key有多个记录,每个记录之后是前一个的更新。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/132181.html原文链接:https://javaforall.net


