
大家好,又见面了,我是你们的朋友全栈君。
学习率是神经网络训练中最重要的超参数之一,针对学习率的优化方式很多,Warmup是其中的一种
(一)、什么是Warmup?
Warmup是在ResNet论文中提到的一种学习率预热的方法,它在训练开始的时候先选择使用一个较小的学习率,训练了一些epoches或者steps(比如4个epoches,10000steps),再修改为预先设置的学习来进行训练。
(二)、为什么使用Warmup?
由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches或者一些steps内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
E x a m p l e Example Example:Resnet论文中使用一个110层的ResNet在cifar10上训练时,先用0.01的学习率训练直到训练误差低于80%(大概训练了400个steps),然后使用0.1的学习率进行训练。
(三)、Warmup的改进
(二)所述的Warmup是constant warmup,它的不足之处在于从一个很小的学习率一下变为比较大的学习率可能会导致训练误差突然增大。于是18年Facebook提出了gradual warmup来解决这个问题,即从最初的小学习率开始,每个step增大一点点,直到达到最初设置的比较大的学习率时,采用最初设置的学习率进行训练。
1.gradual warmup的实现模拟代码如下:
"""
Implements gradual warmup, if train_steps < warmup_steps, the
learning rate will be `train_steps/warmup_steps * init_lr`.
Args:
warmup_steps:warmup步长阈值,即train_steps<warmup_steps,使用预热学习率,否则使用预设值学习率
train_steps:训练了的步长数
init_lr:预设置学习率
"""
import numpy as np
warmup_steps = 2500
init_lr = 0.1
# 模拟训练15000步
max_steps = 15000
for train_steps in range(max_steps):
if warmup_steps and train_steps < warmup_steps:
warmup_percent_done = train_steps / warmup_steps
warmup_learning_rate = init_lr * warmup_percent_done #gradual warmup_lr
learning_rate = warmup_learning_rate
else:
#learning_rate = np.sin(learning_rate) #预热学习率结束后,学习率呈sin衰减
learning_rate = learning_rate**1.0001 #预热学习率结束后,学习率呈指数衰减(近似模拟指数衰减)
if (train_steps+1) % 100 == 0:
print("train_steps:%.3f--warmup_steps:%.3f--learning_rate:%.3f" % (
train_steps+1,warmup_steps,learning_rate))
2.上述代码实现的Warmup预热学习率以及学习率预热完成后衰减(sin or exp decay)的曲线图如下:
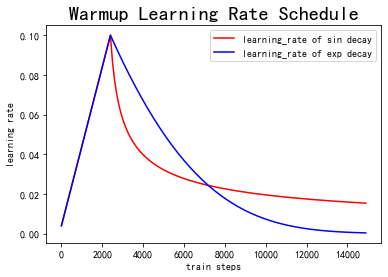

(四)总结
使用Warmup预热学习率的方式,即先用最初的小学习率训练,然后每个step增大一点点,直到达到最初设置的比较大的学习率时(注:此时预热学习率完成),采用最初设置的学习率进行训练(注:预热学习率完成后的训练过程,学习率是衰减的),有助于使模型收敛速度变快,效果更佳。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/132203.html原文链接:https://javaforall.net


