
大家好,又见面了,我是你们的朋友全栈君。
BERT模型也出来很久了,之前看了论文学习过它的大致模型(可以参考前些日子写的笔记NLP大杀器BERT模型解读),但是一直有杂七杂八的事拖着没有具体去实现过真实效果如何。今天就趁机来动手写一写实战,顺便复现一下之前的内容。这篇文章的内容还是以比较简单文本分类任务入手,数据集选取的是新浪新闻cnews,包括了[‘体育’, ‘财经’, ‘房产’, ‘家居’, ‘教育’, ‘科技’, ‘时尚’, ‘时政’, ‘游戏’, ‘娱乐’]总共十个主题的新闻数据。那么我们就开始吧!
Transformer模型
BERT模型就是以Transformer基础上训练出来的嘛,所以在开始之前我们首先复习一下目前NLP领域可以说是最高效的‘变形金刚’Transformer。由于网上Transformer介绍解读文章满天飞了都,这里就不浪费太多时间了。
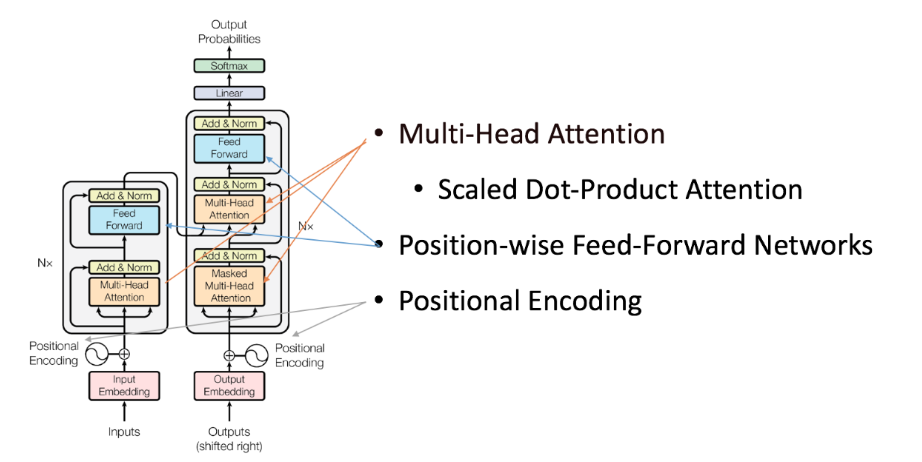

本质上来说,Transformer就是一个只由attention机制形成的encoder-decoder结构。关于attention的具体介绍可以参考之前这篇理解Attention机制原理及模型。理解Transformer模型可以将其进行解剖,分成几个组成部分:
- Embedding (word + position)
- Attention mechanism (scaled dot-product + multi-head)
- Feed-Forward network
- ADD(类似于Resnet里的残差操作)
- Norm(加快收敛)
- Softmax
- Fine-tuning
前期准备
1.下载BERT
我们要使用BERT模型的话,首先要去github上下载相关源码:
git clone https://github.com/google-research/bert.git
下载成功以后我们现在的文件大概就是这样的
2.下载bert预训练模型
Google提供了多种预训练好的bert模型,有针对不同语言的和不同模型大小的。Uncased参数指的是将数据全都转成小写的(大多数任务使用Uncased模型效果会比较好,当然对于一些大小写影响严重的任务比如NER等就可以选择Cased)

对于中文模型,我们使用Bert-Base, Chinese。下载后的文件包括五个文件:
bert_model.ckpt:有三个,包含预训练的参数
vocab.txt:词表
bert_config.json:保存模型超参数的文件
3. 数据集准备
前面有提到过数据使用的是新浪新闻分类数据集,每一行组成是 【标签+ TAB + 文本内容】

Start Working
BERT非常友好的一点就是对于NLP任务,我们只需要对最后一层进行微调便可以用于我们的项目需求。我们只需要将我们的数据输入处理成标准的结构进行输入就可以了。
DataProcessor基类
首先在run_classifier.py文件中有一个基类DataProcessor类:
class DataProcessor(object):
"""Base class for data converters for sequence classification data sets."""
def get_train_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the train set."""
raise NotImplementedError()
def get_dev_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the dev set."""
raise NotImplementedError()
def get_test_examples(self, data_dir):
"""Gets a collection of `InputExample`s for prediction."""
raise NotImplementedError()
def get_labels(self):
"""Gets the list of labels for this data set."""
raise NotImplementedError()
@classmethod
def _read_tsv(cls, input_file, quotechar=None):
"""Reads a tab separated value file."""
with tf.gfile.Open(input_file, "r") as f:
reader = csv.reader(f, delimiter="\t", quotechar=quotechar)
lines = []
for line in reader:
lines.append(line)
return lines
在这个基类中定义了一个读取文件的静态方法_read_tsv,四个分别获取训练集,验证集,测试集和标签的方法。接下来我们要定义自己的数据处理的类,我们将我们的类命名为MyTaskProcessor
编写MyTaskProcessor
MyTaskProcessor继承DataProcessor,用于定义我们自己的任务
class MyTaskProcessor(DataProcessor):
"""Processor for my task-news classification """
def __init__(self):
self.labels = ['体育', '财经', '房产', '家居', '教育', '科技', '时尚', '时政', '游戏', '娱乐']
def get_train_examples(self, data_dir):
return self._create_examples(
self._read_tsv(os.path.join(data_dir, 'cnews.train.txt')), 'train')
def get_dev_examples(self, data_dir):
return self._create_examples(
self._read_tsv(os.path.join(data_dir, 'cnews.val.txt')), 'val')
def get_test_examples(self, data_dir):
return self._create_examples(
self._read_tsv(os.path.join(data_dir, 'cnews.test.txt')), 'test')
def get_labels(self):
return self.labels
def _create_examples(self, lines, set_type):
"""create examples for the training and val sets"""
examples = []
for (i, line) in enumerate(lines):
guid = '%s-%s' %(set_type, i)
text_a = tokenization.convert_to_unicode(line[1])
label = tokenization.convert_to_unicode(line[0])
examples.append(InputExample(guid=guid, text_a=text_a, label=label))
return examples
注意这里有一个self._read_tsv()方法,规定读取的数据是使用TAB分割的,如果你的数据集不是这种形式组织的,需要重写一个读取数据的方法,更改“_create_examples()”的实现。
编写main以及训练
至此我们就完成了对我们的数据加工成BERT所需要的格式,就可以进行模型训练了。
def main(_):
tf.logging.set_verbosity(tf.logging.INFO)
processors = {
"cola": ColaProcessor,
"mnli": MnliProcessor,
"mrpc": MrpcProcessor,
"xnli": XnliProcessor,
"mytask": MyTaskProcessor,
}
python run_classifier.py \
--task_name=mytask \
--do_train=true \
--do_eval=true \
--data_dir=$DATA_DIR/ \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=3.0 \
--output_dir=mytask_output
其中DATA_DIR是你的要训练的文本的数据所在的文件夹,BERT_BASE_DIR是你的bert预训练模型存放的地址。task_name要求和你的DataProcessor类中的名称一致。下面的几个参数,do_train代表是否进行fine tune,do_eval代表是否进行evaluation,还有未出现的参数do_predict代表是否进行预测。如果不需要进行fine tune,或者显卡配置太低的话,可以将do_trian去掉。max_seq_length代表了句子的最长长度,当显存不足时,可以适当降低max_seq_length。
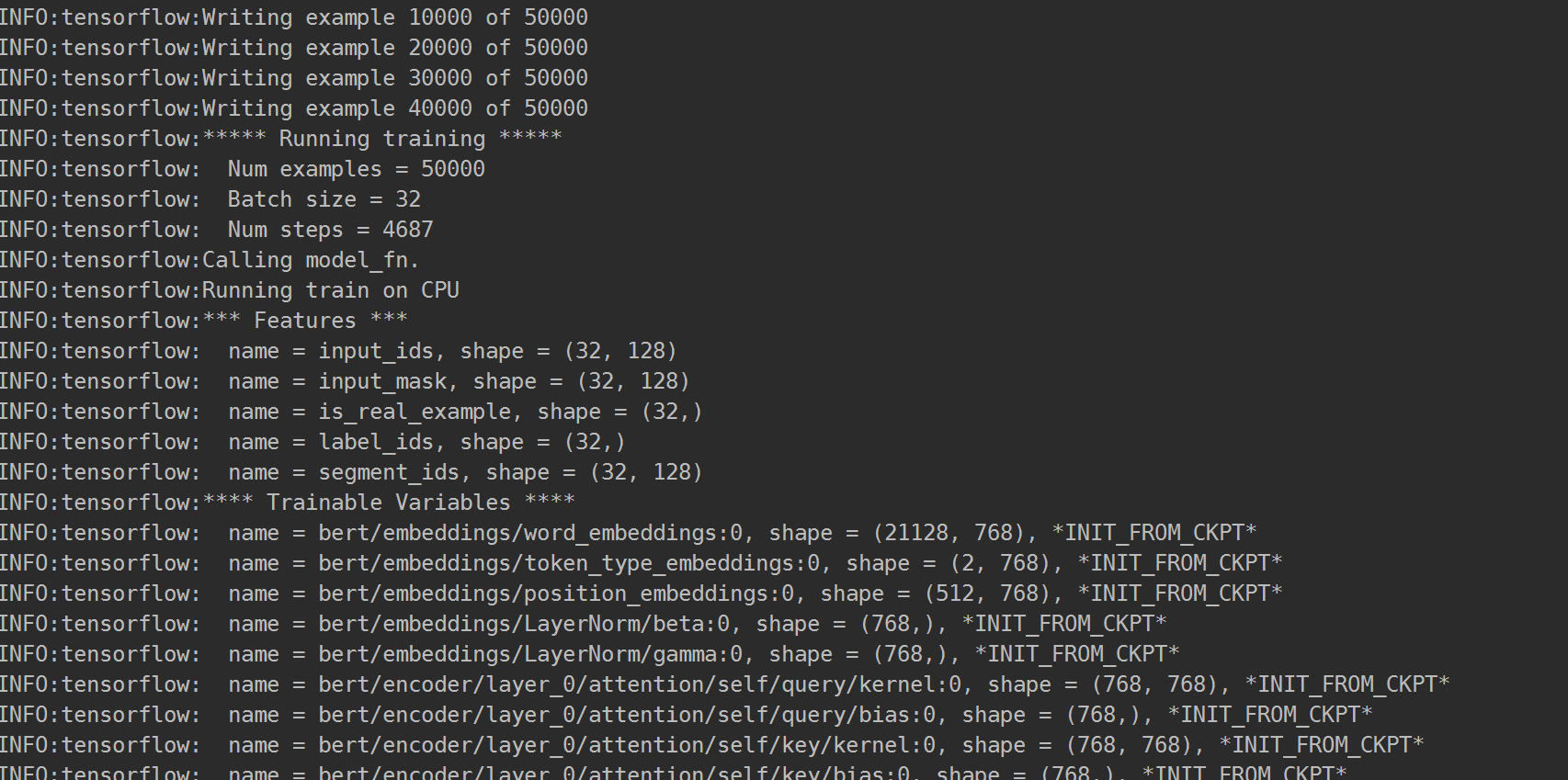
BERT prediction
上面一节主要就是介绍了怎么去根据我们实际的任务(多文本分类)去fine-tune bert模型,那么训练好适用于我们特定的任务的模型后,接下来就是使用这个模型去做相应地预测任务。预测阶段唯一需要做的就是修改 – do_predict=true。你需要将测试样本命名为test.csv,输出会保存在输出文件夹的test_result.csv,其中每一行代表一个测试样本对应的预测输出,每一列代表对应于不同类别的概率。
export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12
export GLUE_DIR=/path/to/glue
export TRAINED_CLASSIFIER=/path/to/fine/tuned/classifier
python run_classifier.py \
--task_name=MRPC \
--do_predict=true \
--data_dir=$GLUE_DIR/MRPC \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$TRAINED_CLASSIFIER \
--max_seq_length=128 \
--output_dir=/tmp/mrpc_output/
有趣的优化
指定训练时输出loss
bert自带代码中是这样的,在run_classifier.py文件中,训练模型,验证模型都是用的tensorflow中的estimator接口,因此我们无法实现在训练迭代100步就用验证集验证一次,在run_classifier.py文件中提供的方法是先运行完所有的epochs之后,再加载模型进行验证。训练模型时的代码:
train_input_fn = file_based_input_fn_builder(
input_file=train_file,
seq_length=FLAGS.max_seq_length,
is_training=True,
drop_remainder=True)
estimator.train(input_fn=train_input_fn, max_steps=num_train_steps)
想要实现在训练过程中输出loss日志,我们可以使用hooks参数:
train_input_fn = file_based_input_fn_builder(
input_file=train_file,
seq_length=FLAGS.max_seq_length,
is_training=True,
drop_remainder=True)
tensors_to_log = {
'train loss': 'loss/Mean:0'}
logging_hook = tf.train.LoggingTensorHook(tensors=tensors_to_log, every_n_iter=100)
estimator.train(input_fn=train_input_fn, hooks=[logging_hook], max_steps=num_train_steps)
增加验证集输出的指标值
原生BERT代码中验证集的输出指标值只有loss和accuracy,
def metric_fn(per_example_loss, label_ids, logits, is_real_example):
predictions = tf.argmax(logits, axis=-1, output_type=tf.int32)
accuracy = tf.metrics.accuracy(
labels=label_ids, predictions=predictions, weights=is_real_example)
loss = tf.metrics.mean(values=per_example_loss, weights=is_real_example)
return {
"eval_accuracy": accuracy,
"eval_loss": loss,
}
但是在分类时,我们可能还需要分析auc,recall,precision等的值。
def metric_fn(per_example_loss, label_ids, logits, is_real_example):
predictions = tf.argmax(logits, axis=-1, output_type=tf.int32)
accuracy = tf.metrics.accuracy(
labels=label_ids, predictions=predictions, weights=is_real_example)
loss = tf.metrics.mean(values=per_example_loss, weights=is_real_example)
auc = tf.metrics.auc(labels=label_ids, predictions=predictions, weights=is_real_example)
precision = tf.metrics.precision(labels=label_ids, predictions=predictions, weights=is_real_example)
recall = tf.metrics.recall(labels=label_ids, predictions=predictions, weights=is_real_example)
return {
"eval_accuracy": accuracy,
"eval_loss": loss,
'eval_auc': auc,
'eval_precision': precision,
'eval_recall': recall,
}
以上~
2019.03.21
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/132579.html原文链接:https://javaforall.net


