
大家好,又见面了,我是你们的朋友全栈君。
在服务端访问量大的时候检测到大量的time wait,并且接口请求延时较高。
执行 netstat -n |awk ‘/^tcp/{++S[$NF]}END{for(m in S) print m,S[m]}’
这个shell命令的意思是把netstat -n 后结果的最后一条放到S[]数组中,如果相同则执行+1操作。
此时能看到TCP各种状态下的连接数量,示例


服务端架构是采用nginx 负载均衡后台有多台tomcat。
先说下TCP建立连接和终止连接的流程
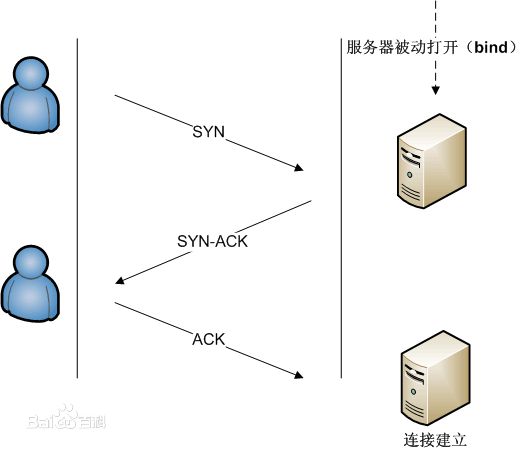
tcp三次握手过程:
1、客户端发送SYN(SEQ=x)报文给服务器端,进入SYN_SEND状态。
2、服务器端收到SYN报文,回应一个SYN (SEQ=y)ACK(ACK=x+1)报文,进入SYN_RECV状态。
3、客户端收到服务器端的SYN报文,回应一个ACK(ACK=y+1)报文,进入Established状态。
三次握手完成,TCP客户端和服务器端成功地建立连接,可以开始传输数据了。
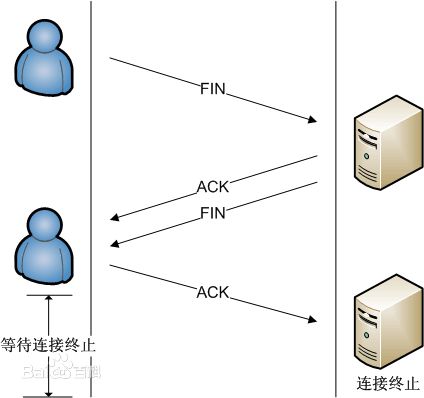
tcp四次拜拜的过程:
(1) 某个应用进程首先调用close,称该端执行“主动关闭”(active close)。该端的TCP于是发送一个FIN分节,表示数据发送完毕。
(2) 接收到这个FIN的对端执行 “被动关闭”(passive close),这个FIN由TCP确认。
注意:FIN的接收也作为一个文件结束符(end-of-file)传递给接收端应用进程,放在已排队等候该应用进程接收的任何其他数据之后,因为,FIN的接收意味着接收端应用进程在相应连接上再无额外数据可接收。
(3) 一段时间后,接收到这个文件结束符的应用进程将调用close关闭它的套接字。这导致它的TCP也发送一个FIN。
(4) 接收这个最终FIN的原发送端TCP(即执行主动关闭的那一端)确认这个FIN。
关于tcp状态转换图建议看下http://www.cnblogs.com/qlee/archive/2011/07/12/2104089.html这篇文章。
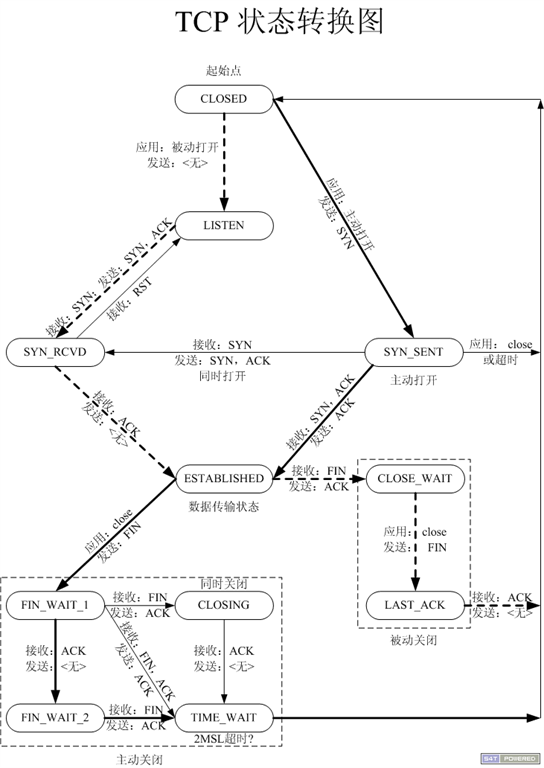
重点说下time_wait、fin_wait_1、fin_wait_2这三个状态:
time_wait状态表示收到了对方的FIN报文,并发送出了ACK报文,就等2MSL后即可回到CLOSED可用状态了。如果FIN_WAIT_1状态下,收到了对方同时带 FIN标志和ACK标志的报文时,可以直接进入到TIME_WAIT状态,而无须经过FIN_WAIT_2状态。
FIN_WAIT_1: 这个状态要好好解释一下,其实FIN_WAIT_1和FIN_WAIT_2状态的真正含义都是表示等待对方的FIN报文。而这两种状态的区别 是:FIN_WAIT_1状态实际上是当SOCKET在ESTABLISHED状态时,它想主动关闭连接,向对方发送了FIN报文,此时该SOCKET即 进入到FIN_WAIT_1状态。而当对方回应ACK报文后,则进入到FIN_WAIT_2状态,当然在实际的正常情况下,无论对方何种情况下,都应该马 上回应ACK报文,所以FIN_WAIT_1状态一般是比较难见到的,而FIN_WAIT_2状态还有时常常可以用netstat看到。
FIN_WAIT_2:上面已经详细解释了这种状态,实际上FIN_WAIT_2状态下的SOCKET,表示半连接,也即有一方要求close连接,但另外还告诉对方,我暂时还有点数据需要传送给你,稍后再关闭连接。
清楚原理后,我们就知道优化方式了。
方法一、加快time_wait状态回收
此部分可以通过调整内核参数完成
vi /etc/sysctl.conf
#表示开启重用,即允许将time_wait socket用于新的tcp连接。默认是关闭的
net.ipv4.tcp_tw_reuse = 1
#表示开启time_wait的快速回收
net.ipv4.tcp_tw_recycle = 1
#表示如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间,默认是60
net.ipv4.tcp_fin_timeout = 10方法二、建立长连接(推荐)
短连接的方式在请求量大的时候需要频繁的进行连接的建立和回收。
长连接节省了三次握手的时间,但是比较占用服务器资源。如果每个用户建立一个长连接,那么很快就到系统瓶颈。这时候可以采用长连接复用技术。以nginx+tomcat为例。
nginx配置
nginx利用tomcat实现长连接复用keepalive_timeout与tomcat配置保持一致
upstream mysdc {
# server 127.0.0.1:8081;
#最大失败次数 3 次 超时 10s 8080 优先 4:3
server 127.0.0.1:8080 max_fails=3 fail_timeout=10s weight=5;
server 127.0.0.1:8081 max_fails=3 fail_timeout=10s weight=3;
# server 127.0.0.1:8081 backup;
# http://nginx.org/en/docs/http/ngx_http_upstream_module.html#keepalive
# 连接到上游服务器的最大并发空闲keepalive长连接数(默认是未设置,建议与Tomcat Connector中的maxKeepAliveRequests值一样)
# 当这个数被超过时,使用"最近最少使用算法(LUR)"来淘汰并关闭连接。
keepalive 8000;
}
keepalive_timeout 120s 120s;tomcat配置maxKeepAliveRequests表示每个长连接支撑多少请求,keepAliveTimeout超时时间120s
<Connector executor="tomcatThreadPool" port="8080" protocol="org.apache.coyote.http11.Http11NioProtocol" processorCache="-1" maxHttpHeaderSize="8192" maxThreads="5000" minSpareThreads="500" acceptorThreadCount="32" connectionTimeout="120000" keepAliveTimeout="120000" maxKeepAliveRequests="100" redirectPort="8443" URIEncoding="UTF-8" enableLookups="false" acceptCount="5000" disableUploadTimeout="true" />发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/132724.html原文链接:https://javaforall.net


