
大家好,又见面了,我是你们的朋友全栈君。
BN原理、作用:


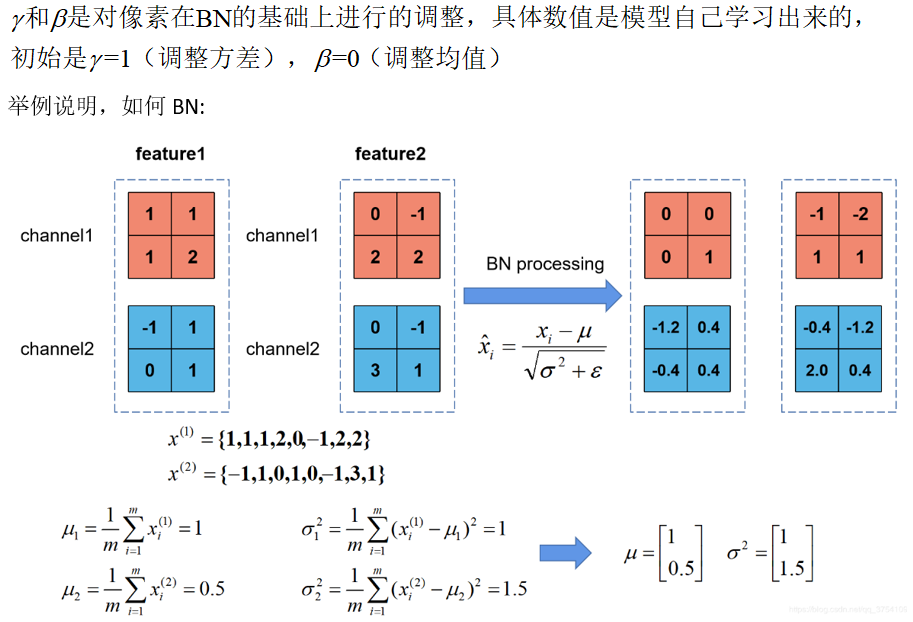
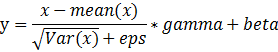
函数参数讲解:
BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
1.num_features:一般输入参数为batch_sizenum_featuresheight*width,即为其中特征的数量,即为输入BN层的通道数;
2.eps:分母中添加的一个值,目的是为了计算的稳定性,默认为:1e-5,避免分母为0;
3.momentum:一个用于运行过程中均值和方差的一个估计参数(我的理解是一个稳定系数,类似于SGD中的momentum的系数);
4.affine:当设为true时,会给定可以学习的系数矩阵gamma和beta
一般来说pytorch中的模型都是继承nn.Module类的,都有一个属性trainning指定是否是训练状态,训练状态与否将会影响到某些层的参数是否是固定的,比如BN层或者Dropout层。通常用model.train()指定当前模型model为训练状态,model.eval()指定当前模型为测试状态。
同时,BN的API中有几个参数需要比较关心的,一个是affine指定是否需要仿射,还有个是track_running_stats指定是否跟踪当前batch的统计特性。容易出现问题也正好是这三个参数:trainning,affine,track_running_stats。
其中的affine指定是否需要仿射,也就是是否需要上面算式的第四个,如果affine=False则γ=1,β=0,并且不能学习被更新。一般都会设置成affine=True。
trainning和track_running_stats,track_running_stats=True表示跟踪整个训练过程中的batch的统计特性,得到方差和均值,而不只是仅仅依赖与当前输入的batch的统计特性。相反的,如果track_running_stats=False那么就只是计算当前输入的batch的统计特性中的均值和方差了。当在推理阶段的时候,如果track_running_stats=False,此时如果batch_size比较小,那么其统计特性就会和全局统计特性有着较大偏差,可能导致糟糕的效果。
如果BatchNorm2d的参数track_running_stats设置False,那么加载预训练后每次模型测试测试集的结果时都不一样;track_running_stats设置为True时,每次得到的结果都一样。
running_mean和running_var参数是根据输入的batch的统计特性计算的,严格来说不算是“学习”到的参数,不过对于整个计算是很重要的。BN层中的running_mean和running_var的更新是在forward操作中进行的,而不是在optimizer.step()中进行的,因此如果处于训练中泰,就算不进行手动step(),BN的统计特性也会变化。
model.train() #处于训练状态
for data , label in self.dataloader:
pred =model(data) #在这里会更新model中的BN统计特性参数,running_mean,running_var
loss=self.loss(pred,label)
#就算不进行下列三行,BN的统计特性参数也会变化
opt.zero_grad()
loss.backward()
opt.step()
这个时候,要用model.eval()转到测试阶段,才能固定住running_mean和running_var,有时候如果是先预训练模型然后加载模型,重新跑测试数据的时候,结果不同,有一点性能上的损失,这个时候基本上是training和track_running_stats设置的不对。
如果使用两个模型进行联合训练,为了收敛更容易控制,先预训练好模型model_A,并且model_A内还有若干BN层,后续需要将model_A作为一个inference推理模型和model_B联合训练,此时希望model_A中的BN的统计特性量running_mean和running_var不会乱变化,因此就需要将model_A.eval()设置到测试模型,否则在trainning模式下,就算是不去更新模型的参数,其BN都会变化,这将导致和预期不同的结果。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/132951.html原文链接:https://javaforall.net


