
大家好,又见面了,我是你们的朋友全栈君。
FM和FFM模型是最近几年提出的模型,凭借其在数据量比较大并且特征稀疏的情况下,仍然能够得到优秀的性能和效果的特性,屡次在各大公司举办的CTR预估比赛中获得不错的战绩。美团点评技术团队在搭建DSP的过程中,探索并使用了FM和FFM模型进行CTR和CVR预估,并且取得了不错的效果。本文旨在把我们对FM和FFM原理的探索和应用的经验介绍给有兴趣的读者。
文章参考:
【1】
1. FFM模型原理
假设一个广告分类的问题,根据用户和广告位相关的特征,预测用户是否点击了广告。源数据如下:


“Clicked?”是label,Country、Day、Ad_type是特征。由于三种特征都是categorical类型的,需要经过独热编码(One-Hot Encoding)转换成数值型特征。

“Day=26/11/15”、“Day=1/7/14”、“Day=19/2/15”这三个特征都是代表日期的,可以放到同一个field中。同理,商品的末级品类编码生成了550个特征,这550个特征都是说明商品所属的品类,因此它们也可以放到同一个field中。简单来说,同一个categorical特征经过One-Hot编码生成的数值特征都可以放到同一个field,包括用户性别、职业、品类偏好等。在FFM中,每一维特征 xi,针对其它特征的每一种field fj,都会学习一个隐向量 vi,fj。因此,隐向量不仅与特征相关,也与field相关。也就是说,“Day=26/11/15”这个特征与“Country”特征和“Ad_type”特征进行关联的时候使用不同的隐向量,这与“Country”和“Ad_type”的内在差异相符,也是FFM中“field-aware”的由来。
假设样本的 n 个特征属于 f 个field,那么FFM的二次项有 nf个隐向量。而在FM模型中,每一维特征的隐向量只有一个,即二次项有n个隐向量。FM可以看作FFM的特例,是把所有特征都归属到一个field时的FFM模型。根据FFM的field敏感特性,可以导出其模型方程。
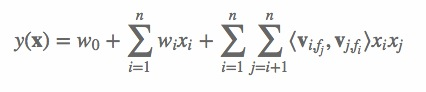
其中,fj 是第 j 个特征所属的field。如果隐向量的长度为 k,那么FFM的二次参数有 nfk 个,远多于FM模型的 nk 个。此外,由于隐向量与field相关,FFM二次项并不能够化简,其预测复杂度是 O(kn2)。
下面以一个例子简单说明FFM的特征组合方式,输入记录如下:

这条记录可以编码成5个特征,其中“Genre=Comedy”和“Genre=Drama”属于同一个field,“Price”是数值型,不用One-Hot编码转换。为了方便说明FFM的样本格式,我们将所有的特征和对应的field映射成整数编号。
 那么,FFM的组合特征有10项,如下图所示:
那么,FFM的组合特征有10项,如下图所示:

其中,红色是field编号,蓝色是特征编号,绿色是此样本的特征取值。二次项的系数是通过与特征field相关的隐向量点积得到的,二次项共有 n(n−1)/2 个。
注意:
① FM和FFM模型的二次项的个数都是 n(n−1)/2 个,区别在于FM模型中二次项存在重复使用的隐向量,而FFM模型没有,这正是由于FFM的域的概念的存在
② FM模型的参数量为nk,FFM模型的参数量为nfk个
③ FM模型的时间复杂度可以优化为线性的,而FFM模型为nfk(最坏时,即当所有特征都是独自一个域时,为n^2k)
2. FFM模型实现
Yu-Chin Juan实现了一个C++版的FFM模型,源码可从Github下载。这个版本的FFM省略了常数项和一次项,模型方程如下:
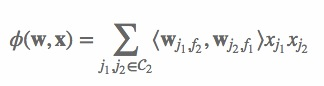
其中,C2 是非零特征的二元组合,j1 是特征,属于field f1,wj1,f2 是特征 j1 对field f2 的隐向量。此FFM模型采用logistic loss作为损失函数,和L2惩罚项,因此只能用于二元分类问题。
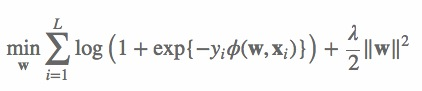
其中,yi∈{−1,1} 是第 i 个样本的label,L 是训练样本数量,λ 是惩罚项系数。模型采用SGD优化,优化流程如下:
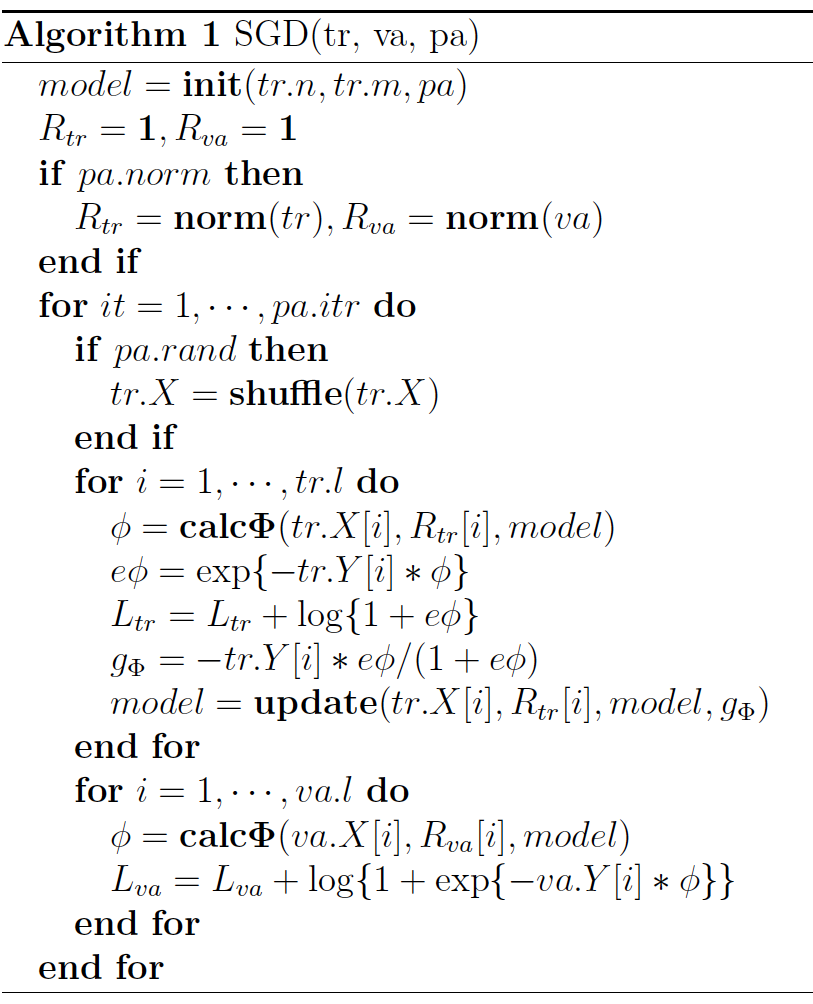
3. FFM模型应用
在DSP的场景中,FFM主要用来预估站内的CTR和CVR,即一个用户对一个商品的潜在点击率和点击后的转化率。
CTR和CVR预估模型都是在线下训练,然后用于线上预测。两个模型采用的特征大同小异,主要有三类:用户相关的特征、商品相关的特征、以及用户-商品匹配特征。用户相关的特征包括年龄、性别、职业、兴趣、品类偏好、浏览/购买品类等基本信息,以及用户近期点击量、购买量、消费额等统计信息。商品相关的特征包括所属品类、销量、价格、评分、历史CTR/CVR等信息。用户-商品匹配特征主要有浏览/购买品类匹配、浏览/购买商家匹配、兴趣偏好匹配等几个维度。
为了使用FFM方法,所有的特征必须转换成“field_id:feat_id:value”格式,field_id代表特征所属field的编号,feat_id是特征编号,value是特征的值。数值型的特征比较容易处理,只需分配单独的field编号,如用户评论得分、商品的历史CTR/CVR等。categorical特征需要经过One-Hot编码成数值型,编码产生的所有特征同属于一个field,而特征的值只能是0或1,如用户的性别、年龄段,商品的品类id等。除此之外,还有第三类特征,如用户浏览/购买品类,有多个品类id且用一个数值衡量用户浏览或购买每个品类商品的数量。这类特征按照categorical特征处理,不同的只是特征的值不是0或1,而是代表用户浏览或购买数量的数值。按前述方法得到field_id之后,再对转换后特征顺序编号,得到feat_id,特征的值也可以按照之前的方法获得。
CTR、CVR预估样本的类别是按不同方式获取的。CTR预估的正样本是站内点击的用户-商品记录,负样本是展现但未点击的记录;CVR预估的正样本是站内支付(发生转化)的用户-商品记录,负样本是点击但未支付的记录。构建出样本数据后,采用FFM训练预估模型,并测试模型的性能。

由于模型是按天训练的,每天的性能指标可能会有些波动,但变化幅度不是很大。这个表的结果说明,站内CTR/CVR预估模型是非常有效的。
在训练FFM的过程中,有许多小细节值得特别关注。
第一,样本归一化。FFM默认是进行样本数据的归一化,即 pa.norm 为真;若此参数设置为假,很容易造成数据inf溢出,进而引起梯度计算的nan错误。因此,样本层面的数据是推荐进行归一化的。
第二,特征归一化。CTR/CVR模型采用了多种类型的源特征,包括数值型和categorical类型等。但是,categorical类编码后的特征取值只有0或1,较大的数值型特征会造成样本归一化后categorical类生成特征的值非常小,没有区分性。例如,一条用户-商品记录,用户为“男”性,商品的销量是5000个(假设其它特征的值为零),那么归一化后特征“sex=male”(性别为男)的值略小于0.0002,而“volume”(销量)的值近似为1。特征“sex=male”在这个样本中的作用几乎可以忽略不计,这是相当不合理的。因此,将源数值型特征的值归一化到 [0,1] 是非常必要的。
第三,省略零值特征。从FFM模型的表达式可以看出,零值特征对模型完全没有贡献。包含零值特征的一次项和组合项均为零,对于训练模型参数或者目标值预估是没有作用的。因此,可以省去零值特征,提高FFM模型训练和预测的速度,这也是稀疏样本采用FFM的显著优势。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/134206.html原文链接:https://javaforall.net


