
大家好,又见面了,我是你们的朋友全栈君。
近日,有热心市民就 “Java内存模型 ” 提出质疑: 线程是否会把所有需要操作的数据全加载到内存

根据《我是憨包》可以看出,当事人蛋蛋(化名)目前情绪稳定,并且似乎已经意识到问题所在
是的,聪明的蛋蛋已经找到了答案(答案后面再说)
此事件发生后,群内大佬高度重视,立即召开线上会议,成立Java内存模型专家小组作出响应,要求组织迅速,妥善处理,迅速查清问题根源,立即组织开展在线答疑,进一步做好指导工作,防止同样问题再次出现,阻挠兄弟们拿到心仪offer
一想到很多朋友还没搞懂Java内存模型,我就饭吃不饱觉睡不着,就连看到黑丝也无动于衷
于是
又花了几天时间 又花了几根头发,来尝试帮大家理解一波~
关于Java内存模型,能扯好多好多、能聊好远好远,但是不要慌,我们整理下问题先:
- 什么是Java内存模型?
- 为什么会有Java内存模型?
- Java内存模型引发了什么问题?
- 线程是否会把所有需要操作的数据全加载到内存?
据当事人陈述:
线程在操作数据时,会从主内存中拷贝一份数据副本到自己的工作内存,操作完再写回主内存,那如果这个数据超级大,也会拷贝到工作内存中吗?
要想弄清这个问题,我们必须先研究下什么是Java内存模型
很多同学会把 Java内存模型 和 JVM内存模型 搞混,这是两种截然不同的东西
Java内存模型:全称Java Memory Model,简称JMM,是一种虚拟机规范,下面会详细讲;
JVM内存模型:全称Java Virtual Machine,简称JVM,也是一种虚拟机规范,关于jvm本文不会展开讲;
如果想开发一款能运行Java程序的虚拟机,就必须遵循这两个规范(当然需要遵循的规范远不止这两种),只有这样,java程序才能在你的虚拟机上开开心心的run,我们最最最最常见的hotspot vm就遵循了这些规范;
Java内存模型的由来

说来话长

我长话短说吧
问题起源
这牵涉到CPU厂商和内存厂商的发展史。。。
我们鸡道,cpu在执行指令的时候,经常需要操作内存中的数据
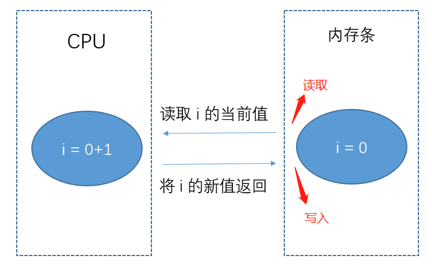
为了方便理解,我举个栗子,拿 i = i + 1来讲
cpu先要从内存中读取到 i 当前的值,进行 +1 ,再将计算结果写回内存
最开始一切安好,但随着技术的发展,cpu执行效率远远超过了内存的读写效率,所以出现了一个现象
cpu执行 +1 操作耗时很短,假设只需要1ms,而从内存中读取 i ,再写回内存,耗时很长,假设是10ms
cpu明明只需要1ms,活生生被内存拖到11ms,这哪儿顶得住啊
于是,机智的cpu厂想了个办法
解决办法
这个办法在《深入理解Java虚拟机》书中也有提到

简单来说就在cpu和内存中间加一层 高速缓存,也就是我们平时说的L1、L2、L3缓存,这一块缓存一般比较小,但嗷嗷快,你懂我意思吧
注意:知识点来了,一定要把cpu的高速缓存和内存条的内存区分开
这是内存条的内存(系统属性中可以查看)

这是cpu的高速缓存(任务管理器-性能一栏可以查看到)

所以现在操作流程变成了:
cpu会事先将需要用到的数据从主内存中复制一份到高速缓存,cpu在执行计算操作时,依次从L1、L2、L3级缓存中查找,如果有需要的数据,直接操作,计算结束后再flush到主内存中;如果没有,再去主内存中查找
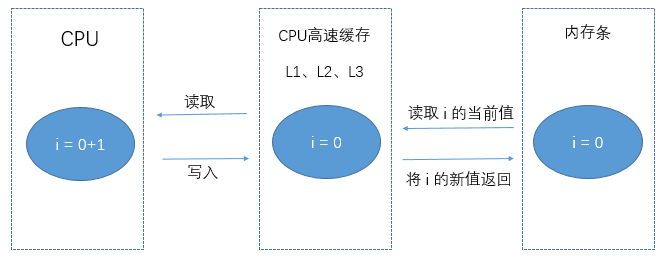
cpu被内存拉低效率的问题得以解决
时间又过了很久。。。
cpu厂商推出了多核处理器,又引出了另一个问题: 线程安全
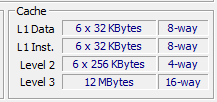
多核处理器的每个核心都有自己的高速缓存(每个cpu架构都不同,要具体看cpu厂商怎么做,目前市面上的cpu一般都是L1、L2独立,L3共享)
上面可以看到我cpu的L1缓存是384k,这384k并不是六个核共享,而是 6 * 32 * 2,如下图
现在,架构变成了

(这个图是简化版,实际的架构图比这复杂得多,那些细节我懒的画了)
所以,现在问题来了,如果不同核心上的线程同时操作同一个数据,会出现什么问题?
我们假设一下
核心a有个线程t1,核心b有个线程t2
开始计算前,内存中 i 的值是0,两线程对应高速缓存中 i 的值也都是0
某一时刻,两线程同时执行 i + 1
t1执行完 i = 1,吭呲吭呲写回内存,此时内存中 i 的值已经由0变为了1
t2执行完 i 也 = 1,也吭呲吭呲把i = 1写回内存,这就把t1写回的新 i 值覆盖了
本来 i 经过两次+1应该等于2,实际结果却等于1,懂我意思吗,大多数并发编程中的数据异常问题都是这么来的
所以,并发编程中,只要涉及到写的操作,我们都应该保证同步,从而得到可靠的最终数据
到这里,我们可以总结下什么内存模型
什么是Java内存模型
由上面的架构图可见,线程需要
上面说了,Java内存模型就是一种协议;线程要操作数据,需要先从主内存中读取到工作内存,操作完再写回主内存,看起来简单,但这之间有很多底层技术细节,比如:
什么时候读取?
又什么时候写入?
多个线程共同读写时又该如何调配?
所以问题来了,一台服务器上的cpu和内存可能是由不同厂商提供的,如果它们的底层实现细节对不上,那怎么保证程序能够正常运行?不可能每次设计产品时都把所有厂商拉一起开个会吧,所以,为了方便,为了统一,有了Java内存模型,它被用来 规范不同硬件和操作系统在内存读写底层实现上的差异;
只有屏蔽这些差异,Java才能实现 一次编译、处处运行
又回到最初的起点、记忆中你青涩的脸~
现在公布答案
说到这儿,再扯一嘴cpu更底层的冷知识
指令重排
并发编程中,除了Java内存模型带来的线程安全问题,cpu、虚拟机自身也存在类似问题
- 关于cpu:为了从分利用cpu,实际执行指令时会做优化
- 关于虚拟机:在HotSpot vm中,为了提升执行效率,JIT(即时编译)模式也会做指令优化
指令重排在大部分场景下确实能提升效率,但有些操作对代码执行顺序是强依赖的,此时我们需要关闭指令重排,相信很多朋友已经猜到了
没错,就是volatile
关于volatile,想要彻底理解,也得扯很多很多,此处就不扯了,改天单独写一篇
举个例来说明什么指令重排,及如何防范:

这个伪代码取自《深入理解Java虚拟机》:
其中描述的场景是开发中常见配置读取过程,只是我们在处理配置文件时一般不会出现并发,所以没有察觉这会有问题。
试想一下,如果定义initialized变量时没有使用volatile修饰,就可能会由于指令重排序的优化,导致位于线程A中最后一条代码“initialized=true”被提前执行(这里虽然使用Java作为伪代码,但所指的重排序优化是机器级的优化操作,提前执行是指这条语句对应的汇编代码被提前执行),这样在线程B中使用配置信息的代码就可能出现错误,而volatile关键字则可以避免此类情况的发生
ok我话说完
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/135213.html原文链接:https://javaforall.net


