
大家好,又见面了,我是你们的朋友全栈君。
大多数人都会对犯错感到不愉快。在我刚学钢琴不久时,我将要在观众面前进行我的第一场表演。我当时很紧张,把一个八度弹奏低了。我卡住了,直到别人指出我的错误后,我才得以继续弹奏。我当时非常尴尬。尽管犯错时很不愉快,但是我们能够从明显的错误中学到东西。你能猜到在我下次弹奏的时候会把这个八度弹对。相反,如果错误很不明显的话,我们的学习速度将会很慢。
理想情况下,我们希望神经网络能够快速地从错误中学习。这种想法现实么?为了回答这个问题,让我们看一个小例子。这个例子包含仅有一个输入的单个神经元:
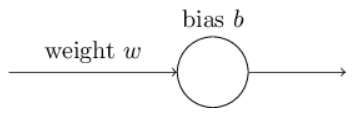

我们将要训练这个神经元去做一些极其简单的事:输入1,输出0。当然,这是一个非常容易的任务,我们可以不利用任何学习算法,通过手算就能找到合适的权重(weight)和偏置(bias)。尽管如此,事实证明利用梯度下降法(gradient descent)能够帮助我们去学习权重和偏置。那么我们就来看一下这个神经元是如何学习的。
为了更明确,我将为权重选定初始值0.6,为偏置选定初始值0.9。这是学习算法开始时一般的初始选择,我没有用到什么特殊的方式来选取这些初始值。神经元的第一次输出为0.82,在到达我们的期望值0之前,神经元还需要很多轮学习迭代。点击右下角的”Run”,我们来看一下神经元是如何学习来让输出结果接近0.0的(译者注:观看交互式动画请前往原作网页)。注意这不是预先录制好的动画,你的浏览器能够真正地去计算梯度,然后用梯度值去更新权重和偏置,然后显示结果。学习率为η=0.15,事实证明这个学习率足够慢以至于我们能够很好地观察到发生了什么,同时它也足够快以至于我们能够获得在几秒内获得大量的学习。代价函数就是我们在第一节里面提到的均方误差函数(quadratic cost function),CC。我将会在接下来给出代价函数的具体形式,这里没必要去深究它的定义。注意你能通过点击”Run”来多次运行这个动画。【这里我直接将录制的gif图片放上来】
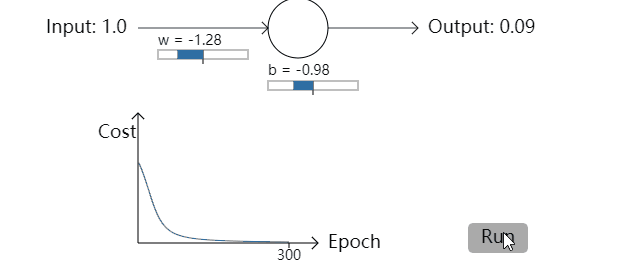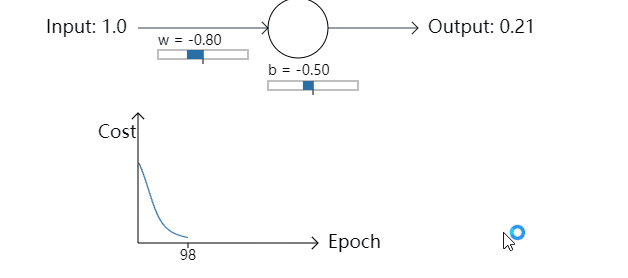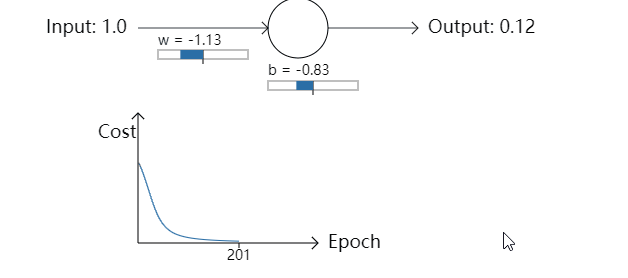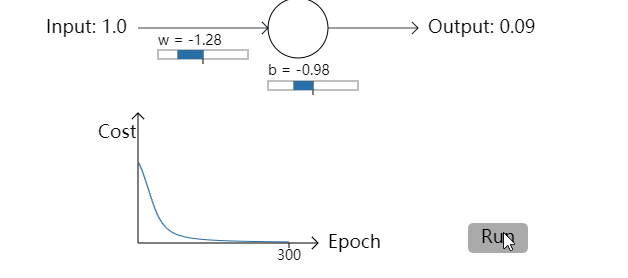
正如你所见,神经元能够迅速地学习权重和偏置来降低代价函数,并最后给出大概0.09左右的输出。虽然这不是我们期待的输出,0.0,但这个结果已经足够好了。假设我们把权重和偏置的初始值都选为2。在这种情况下,初始的输出是0.98,这是相当糟糕的结果。让我们看一下在这个例子中神经元是如何学习的。再次点击”Run”:
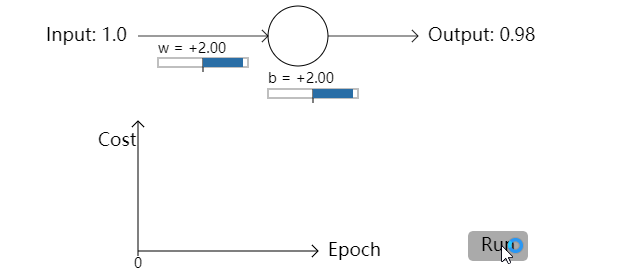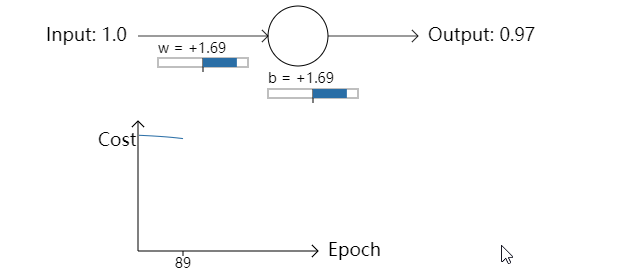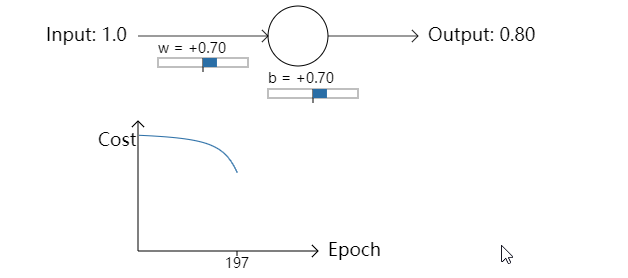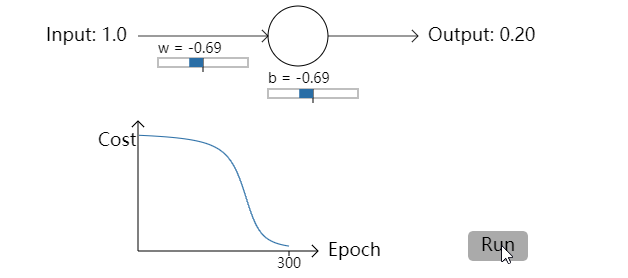
尽管在这个例子中用了相同的学习率(η=0.15),但是我们能看到学习一开始时进行地很缓慢。事实上,在前 150 轮左右的迭代过程中,权重和偏置并没有改变太多。接下来学习过程和我们第一个例子很接近,神经元的输出迅速地接近0.0。
当和人类的学习对比时,我们发现这种行为很奇怪。正如我在这一节开始所提到的那样,我们常常能够在错误很大的情况下能学习地更快。但是正如刚才所见,我们的人工神经元在错误很大的情况下学习遇到了很多问题。另外,事实证明这种行为不仅在这个简单的例子中出现,它也会在很多其他的神经网络结构中出现。为什么学习变慢了呢?我们能找到一种方法来避免这种情况么?
为了搞清问题的来源,我们来考虑一下神经元的学习方式:通过计算代价函数的偏导和来改变权重和偏置。那么我们说「学习速度很慢」其实上是在说偏导很小。那么问题就转换为理解为何偏导很小。为了解释这个问题,我们先来计算一下偏导。回忆一下,我们使用了均方代价函数,即等式(6):

这里aa是输入x=1时神经元的输出,y=0是我们期待的输出。下面我们用权重和偏置来重写这个式子。回忆一下a=σ(z),这里z=wx+b。运用链式法则我们得到:

这里我已经替换了x=1,y=0。为了理解这些表达式的行为,我们要对右面的σ′(z)了解地更深入一点。回忆一下σ函数的形状。
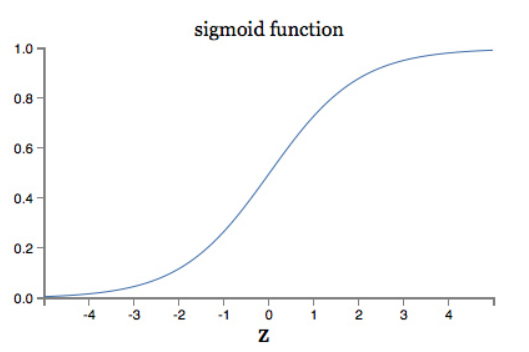
我们能够从图像看出当神经元输出接近1时,曲线变得非常平坦,因此σ′(z)就会变得非常小。等式(55)和等式(56)能告诉我们∂C/∂w和∂C/∂b会变得很小。这就是学习速度变慢的根源。另外,正如我们稍后所见到的那样,这种情况导致的速度下降不仅仅适应我们的示例神经元网络,它还适用于很多其他通用的神经元网络。
交叉熵代价函数简介
我们如何来避免这种减速呢?事实证明我们可以用不同的代价函数比如交叉熵(cross-entropy)代价函数来替代平方代价函数。为了理解交叉熵,我们暂时先不用管这个示例神经元模型。我们假设要训练一个拥有多个输入变量的神经元:输入x1,x2,…,权重w1,w2,…,偏置b:
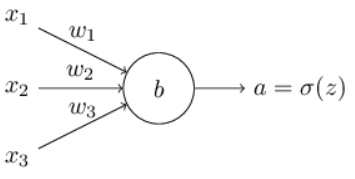
神经元的输出为a=σ(z),这里 。我们定义这个神经元的交叉熵代价函数为:
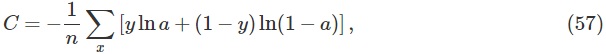
这里n是训练数据的个数,这个加和覆盖了所有的训练输入x,y是期望输出。
仅从等式(57)我们看不出为何能解决速度下降的问题。事实上,老实讲,这个甚至看不出这个式子为何能称之为代价函数!在了解它能避免学习减速之前,我们还是有必要解读交叉熵为何能作为代价函数。
交叉熵有两个特性能够合理地解释为何它能作为代价函数。首先,它是非负的,也就是说,C>0。为了说明这个,我们需要注意到:(a)等式(57)加和里的每一项都是负的,因为这些数是0到1之间的,它们的对数是负的;(b)整个式子的前面有一个负号。
其次,如果对于所有的训练输入x,这个神经元的实际输出值都能很接近我们期待的输出的话,那么交叉熵将会非常接近0。为了说明这个,假设有一些输入样例x得到的输出是y=0,a≈0。这些都是一些比较好的输出。我们会发现等式(57)的第一项将会消掉,因为y=0,与此同时,第二项−ln(1−a)≈0。同理,当y=1或a≈1时也如此分析。那么如果我们的实际输出接近期望输出的话代价函数的分布就会很低。
总结一下,交叉熵是正的,并且当所有输入,x,的输出都能接近期望输出,y,的话,交叉熵的值将会接近0。这两个特征在直觉上我们都会觉得它适合做代价函数。事实上,我们的均方代价函数也同时满足这两个特征。这对于交叉熵来说是一个好消息。而且交叉熵有另一个均方代价函数不具备的特征,它能够避免学习速率降低的情况。为了理解这个,我们需要计算一下交叉熵关于权重的偏导。我们用a=σ(z)代替等式(57),并且运用链式法则,得到:
【为了证明这个结论,我需要假设y的输出只能为0或者1。这种情况特别在分类问题,或者在计算布尔函数时出现。如果你想知道如果我们不做这个假设时会发生什么,请查看本节最后的练习。】
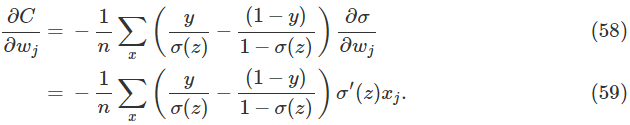
通分化简之后得到:
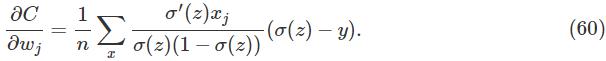
利用sigmoid函数的定义,,和一点代数知识我们就能得到。在下面的练习题中我会让你证明这个结论,但是现在我们就默认接受它。可以看到和这一项在上式中消除了,它被简化成:

这是一个非常优美的表达式。它告诉我们权重的学习速率可以被控制,也就是被输出结果的误差所控制。误差越大我们的神经元学习速率越大。这正是我们直觉上所期待的那样。另外它能避免学习减速,这是σ′(z)一项导致的。当我们使用交叉熵时,σ′(z)这一项会被抵消掉,因此我们不必担心它会变小。这种消除是交叉熵代价函数背后所带来的惊喜。实际上,这并不是一个惊喜。稍后我们会看到,我们特意选取了具有这种特性的函数。
同样,我们能够计算偏置的偏导。我在这里不详细介绍它了,你可以很容易证明:

同理,它也能够避免σ′(z)这一项带来的学习减速。
补充
在之后的学习过程中我们会发现,交叉熵的格式为:这和上面的不太一样。其实这个函数才是真正的交叉熵。
上面讲解的交叉熵代价函数是的一个变形。详解如下:
交叉熵损失函数应用在分类问题中时,不管是单分类还是多分类,类别的标签都只能是 0 或者 1。
交叉熵在单分类问题中的应用
这里的单类别是指,每一张图像样本只能有一个类别,比如只能是狗或只能是猫。交叉熵在单分类问题上基本是标配的方法
上式为一张样本的 计算方法。式中 代表着 种类别。举例如下,

交叉熵在多标签问题中的应用
这里的多类别是指,每一张图像样本可以有多个类别,比如同时包含一只猫和一只狗和单分类问题的标签不同,多分类的标签是n-hot。

值得注意的是,这里的Pred采用的是sigmoid函数计算。将每一个节点的输出归一化到[0,1]之间。所有Pred值的和也不再为1。换句话说,就是每一个Label都是独立分布的,相互之间没有影响。所以交叉熵在这里是单独对每一个节点进行计算,每一个节点只有两种可能值,所以是一个二项分布。前面说过对于二项分布这种特殊的分布,熵的计算可以进行简化。
同样的,交叉熵的计算也可以简化,即
注意,上式只是针对一个节点的计算公式。这一点一定要和单分类loss区分开来。
交叉熵代价函数对权重求导的证明
交叉熵代价函数的定义:
代价函数 对 求偏导
其中 来自,根据 定义
所以
根据 的定义,
把 带入 可得
其向量形式是
对偏置用同样的方法可得
练习
- 证明。
- 让我们回到之前的例子中来,一块研究一下如果我们使用交叉熵代价函数而不是均方误差会发生些什么。我们先从均方误差表现好的情况开始:权重为0.6,偏置为0.9。按下”Run”去观察一下我们使用交叉熵代价函数会发生什么:
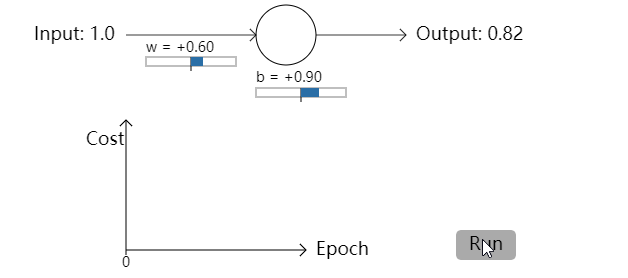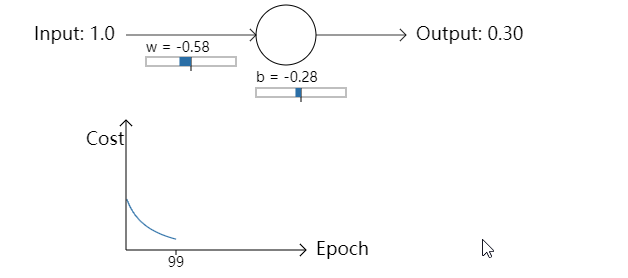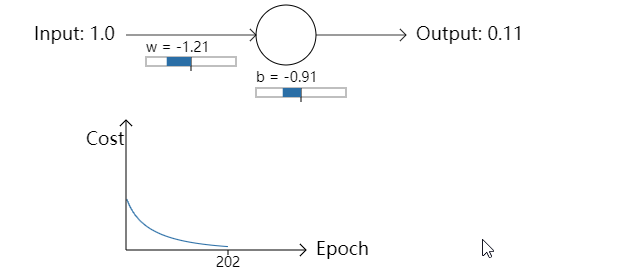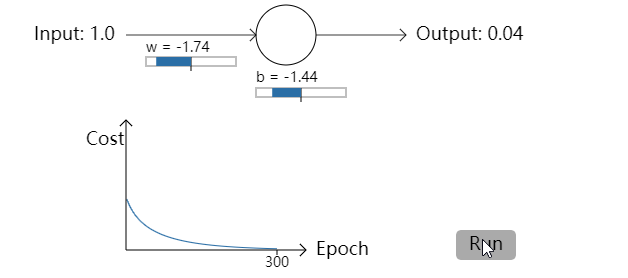
不出所料,神经元在这种情况下和之前使用均方误差时一样好。那么现在我们就要看一下之前均方误差表现较差的情况(点这里进行对比):权重和偏置都设置成2.0:
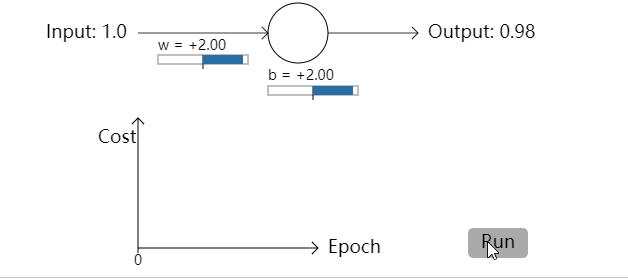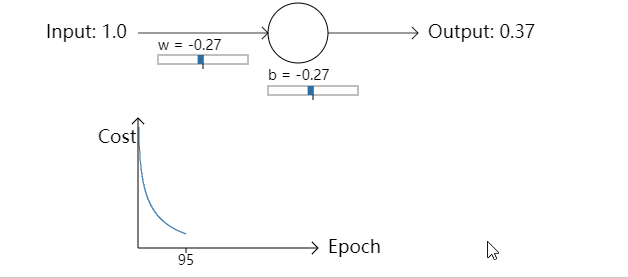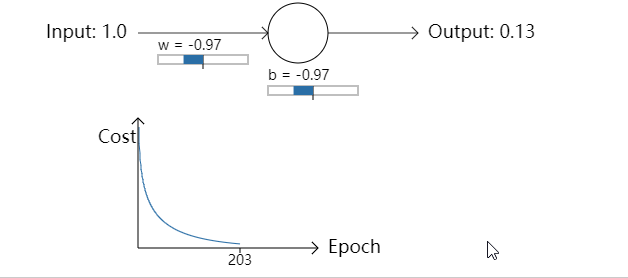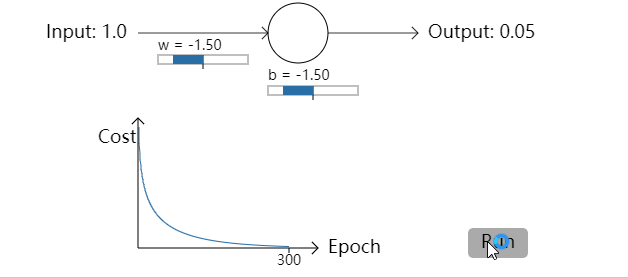
成功了!这次神经元学习速度很快。如果你细心观察你会发现代价函数曲线在初始的时候比使用均方误差时更陡峭。这意味着即使我们初始的条件很糟糕,交叉熵函数也能尽可能地降低学习速度减慢的可能性。
我并没有指明这些例子中用到的学习速率。在使用均方误差的时候,我选取 η=0.15。那么我们应该在新的例子中用相同的学习速率么?事实上,代价函数发生改变之后我们不能很精确的定义什么是「相同」的学习速率。这就像对比苹果和橘子一样。对于这两种代价函数我都实验过一些不同的学习速率。如果你仍然好奇,那么事实是这样的:我在新的例子中选取η=0.005。
你可能会反对学习速率的改变,因为这会让上面的例子变得没有意义。如果我们随意选取学习速率那么谁还会在意神经元学习地有多快呢?这种反对偏离了重点。这个例子的重点不是在说学习速度的绝对值。它是在说明学习速度是如何变化的。当我们使用均方误差代价函数时,如果选取一个错的离谱的开始,那么学习速度会明显降低;而我们使用交叉熵时,这种情况下学习速度并没有降低。这根本不取决于我们的学习速率是如何设定的。
我们已经研究过交叉熵用于单个神经元的情况。事实上,这很容易推广到多层神经网络上。我们假设y=y1,y2,…是我们期望的输出,例如,在神经元的最后一层,,…是真实的输出。那么我们可以定义交叉熵:
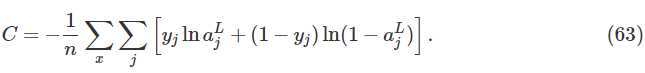
这其实和我们的等式(57)相同,只不过这里面的是求所有神经元的输出。我不会再一次精确地求偏导了,但是容易看出用式表达式(63)也可以避免多层神经网络中学习速度下降的情况。如果你感兴趣,你可以在下面的问题中求一下偏导。
什么情况下我们要用交叉熵函数取代均方误差函数呢?事实上,如果输出神经元是sigmoid神经元的话,交叉熵都是更好的选择。为了理解这个,假定我们随机初始化权重和偏置。那么可能会发生这种情况,初始的选择会的到误差很大的输出,比如我们想得到0时,它却输出1,或者相反的情况。如果我们用均方误差,学习速度会明显降低。这种情况不会停止学习,因为权重还会通过其他训练数据学习,但这显然不是我们想要的。
练习
-
交叉熵带来的一个问题就是很难记住表达式中y和a的位置。我们很容易记不清正确的表达式是
还是。当y=0或1时,如果使用了第二个表达式会发生什么呢?这个问题会发生在第一个表达式上吗?请说明你的理由。 -
在本节开始讨论单个神经元时,我曾声称如果所有的训练数据都有σ(z)≈y,那么交叉熵会变得非常小。这个假设依赖于y既非0也非1。这对于分类问题是正确的,但是对于其他问题(比如回归问题)y的取值可能在0和1之间。证明当所有的训练数据σ(z)=y时,交叉熵仍然是最小化的。当交叉熵有下面形式时:
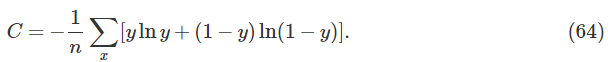
的值有时被称作二进制熵(binary entropy)。
问题
- 多层神经网络
在上一章介绍这个概念的时候,我们利用均方误差代价函数得到输出层对权重求偏导有:
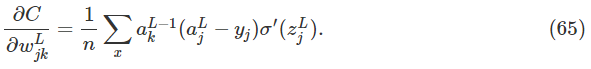
其中)会导致当输出明显出错的时候学习速度下降。对于交叉熵,我们的输出误差对于每一个单个训练数据x有

用这个表达式可以证明输出层对权重的偏导为
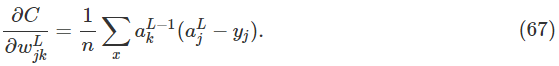
这样这一项就消掉了,因此交叉熵代价函数能够避免速度下降,这不仅仅对一个单个神经元成立,对于多层神经元也是成立的。简单变形一下也能得到偏置也具有相同的形式。
- 当我们的输出层是线性神经元(linear neurons)的时候使用均方误差
假设我们有一个多层神经网络。假设最后一层的所有神经元都是线性神经元(linear neurons)意味着我们不用sigmoid作为激活函数,输出仅仅是。如果我们用均方误差函数时,输出误差对于每个训练输入x为

和我们之前的问题类似,利用这个表达式我们在输出层对权重和偏置求导有

这就意味着如果输出神经元是线性神经元的话就不会产生速度下降的问题。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/135314.html原文链接:https://javaforall.net


