
大家好,又见面了,我是你们的朋友全栈君。
1. 前言
这个项目是我2011年在杭州某家互联网公司实习时写的项目,当时坐下来感觉还不错,能够支持上百台服务器的集群需求,并且也支持简单的负载均衡策略,接下来,我来简单地介绍下JDistFS的实现目标,架构以及提供给上层用户使用的接口说明
2. JDistFS目标
1)支持C++/JAVA 语言的API借口
2)支持Linux/Windows 系统
3)支持集群,支持动态扩展,支持数据容量最大可达10TB
4)支持单文件最大2G
5)支持2种负载均衡策略
6) 支持单文件在2个节点存储,并且支持单节点容错功能
3. 系统的整体结构设计

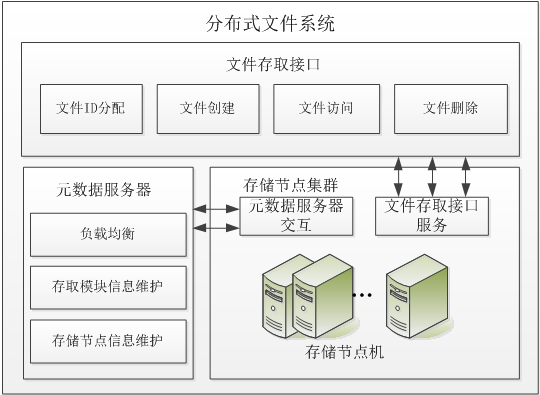
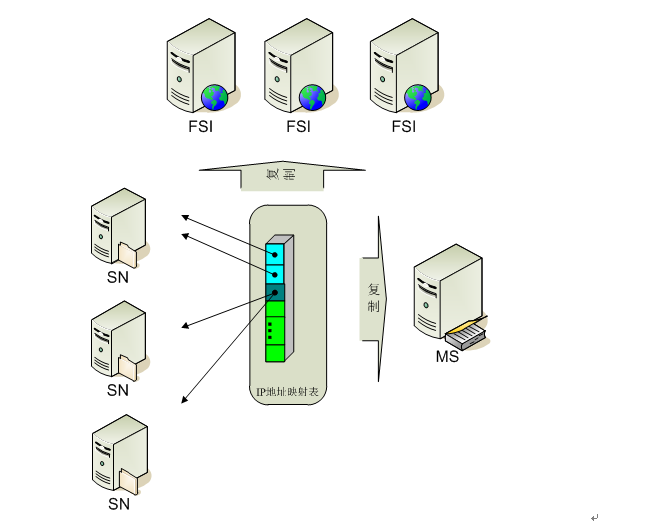
4. 系统的整体存储结构
在该结构中主要分为了两类节点:SN节点和MS节点,SN节点主要职责是存储数据,而MS节点的职责就是监控管理每个节点,而我们的FSI节点主要为用户提供访问本系统的接口,结构示意图如下:
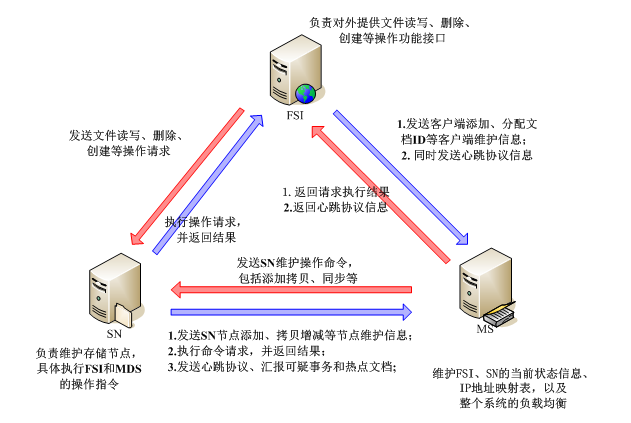
5. FSI、SN以及MS节点之间的消息走向如下图所示
6. 内外部接口的设计
1)整体的设计架构图如下所示
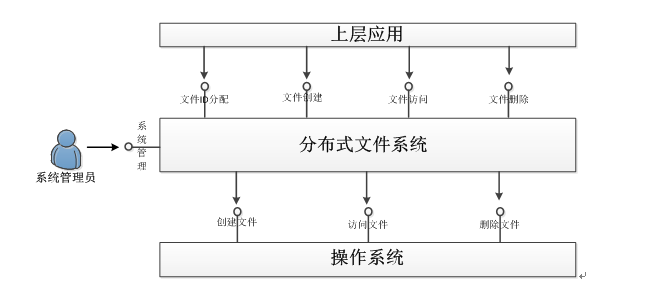
2)内外部接口调用流程图
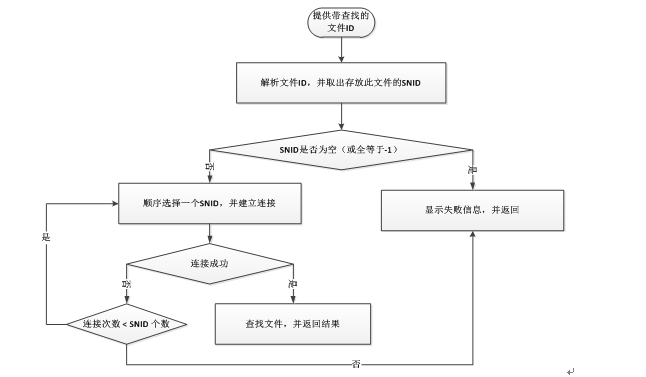
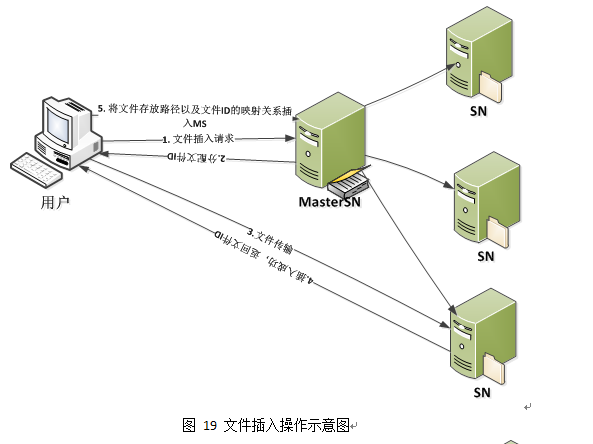
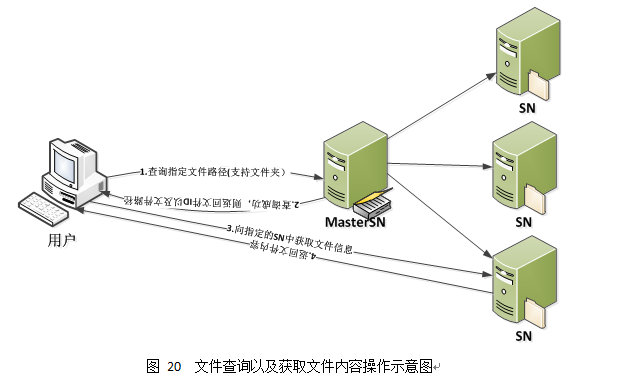
本文件ID设计结构主要是为了支持文件容错备份,通过对每一个插入到系统中的文件分配一个文件ID,其中包括了两个节点ID号,表示文件备份到了两个节点上,当用户通过指定的文件ID 进行查找文件时,系统首先对文件ID前两个字节进行解析,分析此文件存放的节点号(SNID),然后通过解析到的SNID,建立到此节点的链接,最后由节点通过查找本地存储文件目录,并将查找到的结果发给用户。由于其中涉及到文件备份的内容,所以当对于一个文件进行查找时,可能会查找到多个结果,所以我们的查找原则是:如果查找到多个备份时,我们是顺序选择一个节点备份,并将其查找内容发给用户,否则继续查找,只要有一个节点有这个文件备份,就停止查找,返回结果。
文件查找操作流程图
文件上传流程图

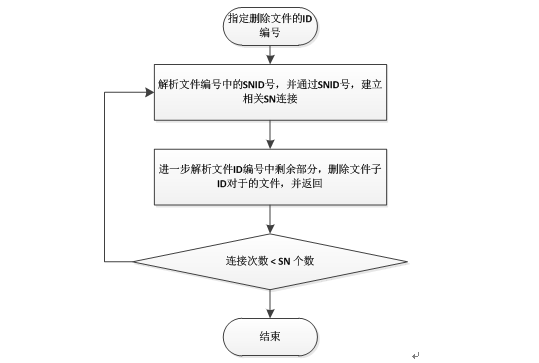
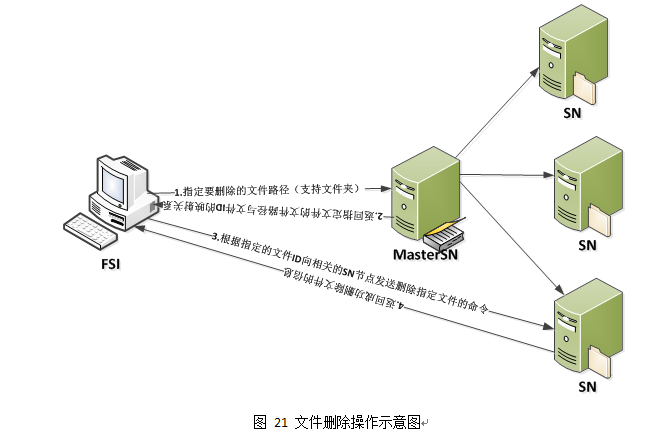
文件删除流程图
7.对大文件上传的支持流程图
分布式文件系统对大文件的支持主要是集中在对于文件分块的处理,本系统的对大文件支持也是通过将大文件进行分割成小的文件块,然后对每一个文件块进行处理(存储),主要的步骤如下所示:
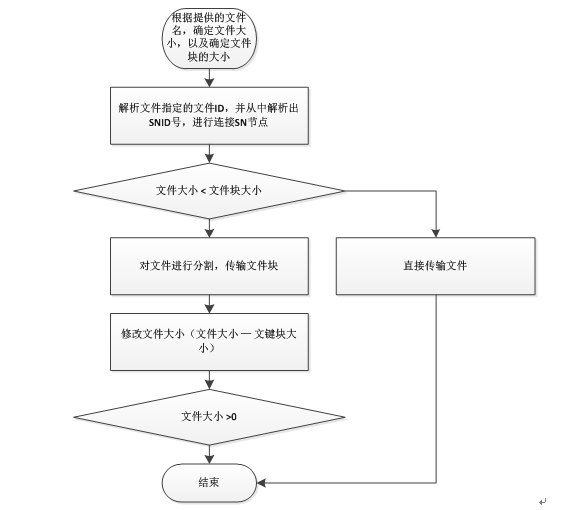
由于对于大文件传输时,为了提高传输的效率,我们首先通过文件大小来确定传输的文件是否是大文件,如果不是大文件我们按照常规的方法一次性传输,但是如果是大文件,我们首先将文件分割成一块块的文件块,并通过链表来连接,存放文件块的数据结构初步定为如下:
Typedefstruct FileNode
{
Elemtype* buffer;
Struct FileNode* next;
};
采用本结构的流程图如下所示:
8. 数据的迁徙功能
数据迁移的主要作用是为了防止某一个节点因为物理上的失效,导致数据节点的数量减少,从而影响了系统的性能,因此为了是系统的性能免受节点失效的影响,故采用数据迁移的思想,其主要的做法是将某一个失效的节点从系统中剔除,并且将一个新的节点加入系统中,并且将存储在原失效的节点上的文件,存储在新加入的节点上,这里主要是通过文件备份来完成,数据迁徙的工作的。其主要的流程图如下所示:
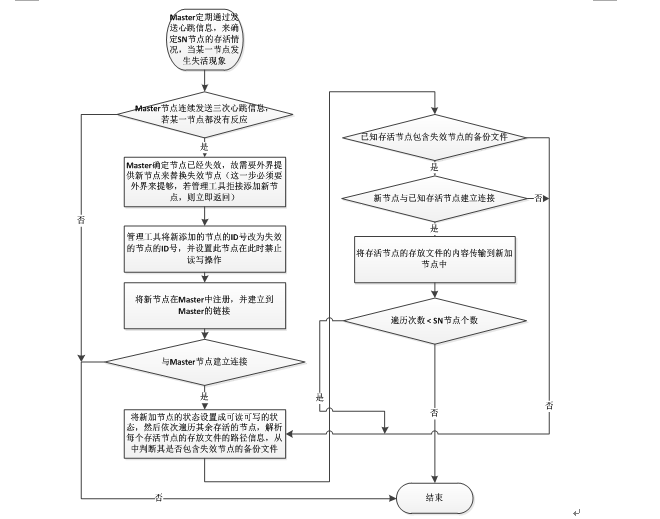
9.支持目录管理
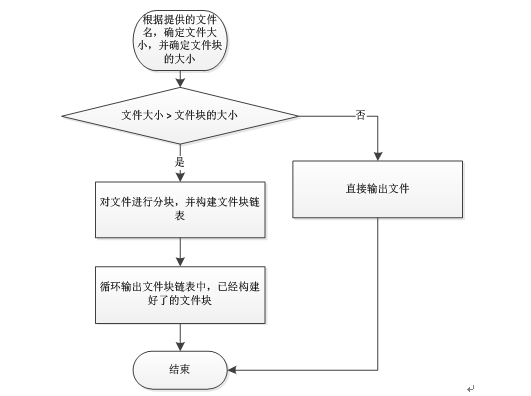
目录管理的主要功能是为了支持对分布式文件系统内存放文件的管理以及支持用户对文的查询功能,具体的查询流程图如下图所示
10. 对文件相关操作的示意图
11.总结
该项目主要实现了对文件的基本操作并且在此基础上实现了文件的迁徙功能,整个架构在基本能够实现其所指定的目标,目前这个项目的代码仍在优化当中,优化的主要的方向是提高整个集群的扩展性,使其能够支持更多的SN节点的加入,另外一点就是优化负载均衡算法,目前的负载均衡算法是一种随机算法,性能不是稳定,预计接下来的版本将会支持更大的FSI连接数以及整体的吞吐量。
附:
表1 分布式文件系统外部接口
|
序号 |
接口名称 |
提供方 |
调用方 |
接口功能说明 |
|
1 |
Long AddFile(String filename,String destDirectory,Boolean isCache) |
FSI |
上层(应用层) |
本函数主要是用于向文件系统中插入文件,其中filename是要插入文件的名称,destDirectory是文件插入的目标目录,isCache标记是否采用缓存机制;如果插入成功则返回ID,否则返回-1. |
|
2 |
Void AddDirecotry(String SourceDirectory,String destDirectory) |
FSI |
上层(应用 层) |
本函数主要是用于向文件系统中插入整个文件夹下的所有文件,其中SourceDirectory是要插入文件系统中的文件夹,destDirectory是插入的目的地文件夹. |
|
3 |
Long AddBuffer(Byte[] buffer, int bufferlen ) |
FSI |
上层(应用层) |
本函数提供将某一缓存块的内容,直接插入系统中,参数buffer 为要插入系统中的缓冲区,bufferlen为其长度;如果插入成功返回 文件ID,否则返回 -1 |
|
4 |
HashMap<String,String> GetFileList(String filePath) |
FSI |
上层(应用层) |
本函数主要是用于返回文件按系统中存放在filePath目录下的所有文件名,返回文件名与文件ID的映射关系 |
|
5 |
Vector<String> getRootDirectory() |
FSI |
上层(应用层) |
本函数主要是用于返回文件系统中所有存放文件的根目录. |
|
6 |
Vector<String> find(String filename) |
FSI |
上层(应用层) |
本函数主要是用于文件的查找,返回查找到的指定文件路径名。 |
|
7 |
Void GetFile(String filePath,String absoluteSavePath) |
FSI |
上层(应用层) |
本函数的主要是用于通过指定文件系统中的文件的路径,并将其下载到本地指定目录中,其中filePath为要下载的目标文件路径(支持文件夹),absouteSavePath为本地存放路径。 |
|
8 |
Boolean Delete(String filePath) |
FSI |
上层(应用层) |
本函数主要是用于删除文件系统中指定的文件(支持删除整个文件夹内容),其中filePath为要删除的文件路径;删除成功则返回true,失败则返回false。 |
|
9 |
Byte[] GetBuffer(long id ) |
FSI |
上层(应用层) |
本函数提供通过指定文件ID,从系统中返回文件内容,并将其内容存放一个缓冲区,并返回 |
|
10 |
Void CopyFile(int deadSnId ,int newSnId) |
FSI |
上层(应用层) |
本函数提供数据迁移功能,通过指定两个节点ID(一个为关掉的节点ID,一个为新加入的节点ID),将关掉的节点ID,文件内容复原到新加入的节点中;参数deadSnId为已经关掉的节点,newSnId为deadSnId节点内容的备份节点 |
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/136476.html原文链接:https://javaforall.net

![电源设计LDO和DCDC[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
