
大家好,又见面了,我是你们的朋友全栈君。
===========================================================
有现成的代码:https://github.com/Kongsea/FPN_TensorFlow
推荐根据该博客来学习:https://www.jianshu.com/p/324af87a11a6
https://blog.csdn.net/bi_diu1368/article/details/90812517
============================================================
纸上得来终觉浅,须知此事要coding!
ResNet+FPN实现
我们先说FPN的目的。
熟悉faster rcnn的人知道,faster rcnn利用的是vgg的最后的卷积特征,大小是7x7x512。而这造成了一个问题,经过多次卷积之后的特征通常拥有很大的感受野,它们比较适合用来检测大物体,或者说,它们在检测小物体任务上效果很差,所以像ssd和fpn这样的网络思想就是将前面和后面的的卷积层都拿出来,组成一个multisacle结果,既能检测大物体,又能检测小物体。
基于这个思想,fpn从ResNet 34层模型构造了一组新的特征,p2,p3,p4,p5,每一个p_ipi都是ResNet中不同卷积层融合的结果,这保证了他们拥有多尺度信息。他们拥有相同的维度,都是256。
构造的方式如下,先贴FPN:
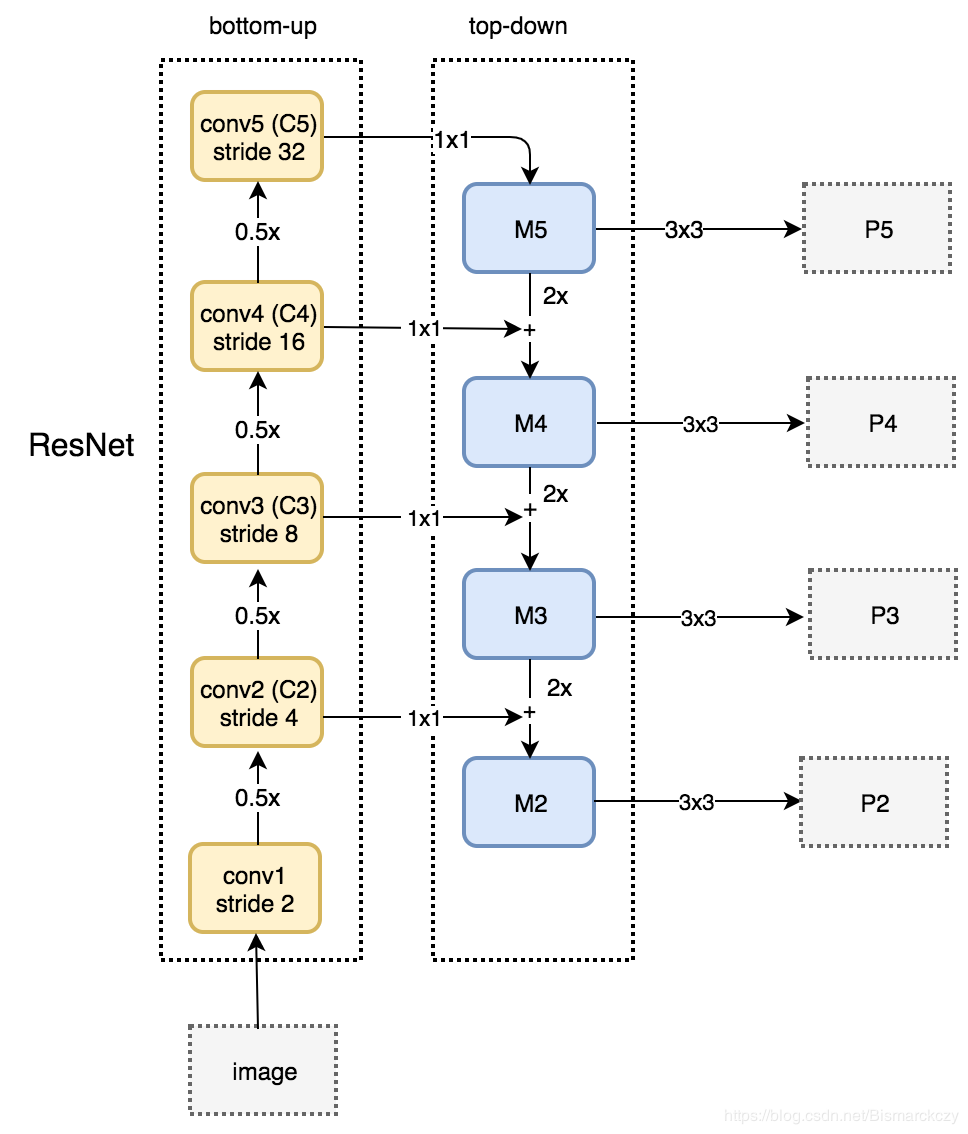

bottom-up就是简单的使用了ResNet34,主要是top-down中的思想。
在上文中我们提到c2-c5的大小和维度分别是56x56x64,28x28x128,14x14x256,7x7x512,所以在top-down中,先用了一个1x1x256的卷积将c5:7x7x512 变成了m5:7x7x256, 每一个m之后都接了一个3x3x256卷积用来消除不同层之间的混叠效果,其实也就是缓冲作用。
关于p4的构造,我们先将m5的feature map加倍,用简单的nearest neighbour upsamping方法就行,这样m5就变成了m5’:14x14x256,同时c4:14x14x256经过1x1x256得到c4’:14x14x256, 将m5’+c4’, element-wisely,就可以得到m4:14x14x256。
…
所以最后的p2-p5大小分别是
56x56x256。,28x28x256,14x14x256,7x7x256。
这只是FPN结构,具体的FPN网络就比较复杂了,也贴一个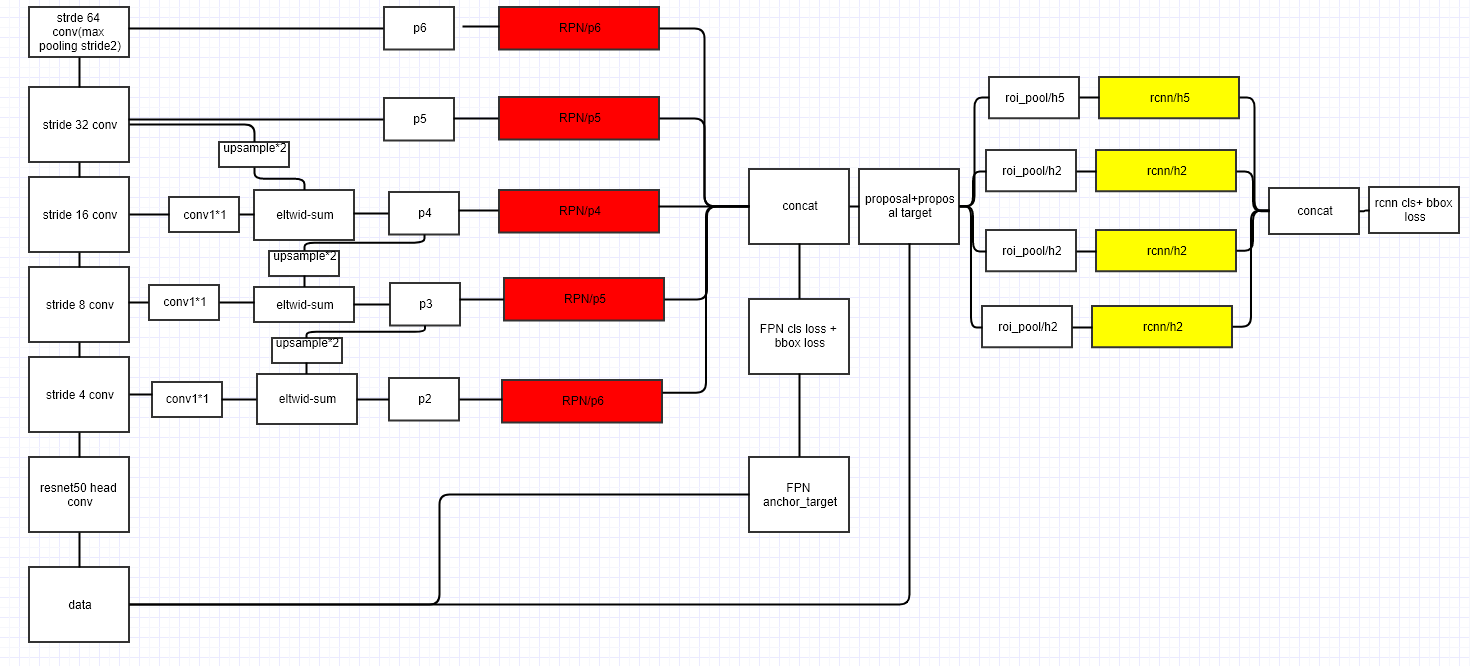
稍微讲一下FPN结构吧,用的原理就是图像处理中很简单但很重要的金字塔结构。以ResNet50为例,四层结构得到的特征图尺寸应为:(ResNet50可看我上一篇博客)
c1:torch.Size([1, 64, 56, 56])
c2:torch.Size([1, 256, 56, 56])
c3:torch.Size([1, 512, 28, 28])
c4:torch.Size([1, 1024, 14, 14])
c5:torch.Size([1, 2048, 7, 7])
之后对c1-c5进行处理。我们的目标是输出四种特征图,其尺寸不同,但深度都为256。
P2:torch.Size([1, 256, 56, 56])
P3:torch.Size([1, 256, 28, 28])
P4:torch.Size([1, 256, 14, 14])
P5:torch.Size([1, 256, 7, 7])
具体做法是:
1.将c5降到256,经过33的卷积处理输出P5.
2.c5上采样后与经过11降维处理过的c4相加,再经3*3卷积处理,得到P4。
以此类推…
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, stride=stride, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class FPN(nn.Module):
def __init__(self, block, layers):
super(FPN, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
# Bottom-up layers
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
# Top layer
self.toplayer = nn.Conv2d(2048, 256, kernel_size=1, stride=1, padding=0) # Reduce channels
# Smooth layers
self.smooth1 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.smooth2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.smooth3 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
# Lateral layers
self.latlayer1 = nn.Conv2d(1024, 256, kernel_size=1, stride=1, padding=0)
self.latlayer2 = nn.Conv2d( 512, 256, kernel_size=1, stride=1, padding=0)
self.latlayer3 = nn.Conv2d( 256, 256, kernel_size=1, stride=1, padding=0)
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.in_planes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_planes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.in_planes, planes, stride, downsample))
self.in_planes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.in_planes, planes))
return nn.Sequential(*layers)
def _upsample_add(self, x, y):
_,_,H,W = y.size()
return F.interpolate(x, size=(H,W), mode='bilinear',align_corners=True) + y
def forward(self, x):
# Bottom-up
c1 = F.relu(self.bn1(self.conv1(x)))
c1 = F.max_pool2d(c1, kernel_size=3, stride=2, padding=1)
#print(f'c1:{c1.shape}')
c2 = self.layer1(c1)
#print(f'c2:{c2.shape}')
c3 = self.layer2(c2)
#print(f'c3:{c3.shape}')
c4 = self.layer3(c3)
#print(f'c4:{c4.shape}')
c5 = self.layer4(c4)
#print(f'c5:{c5.shape}')
# Top-down
p5 = self.toplayer(c5)
#print(f'p5:{p5.shape}')
p4 = self._upsample_add(p5, self.latlayer1(c4))
#print(f'latlayer1(c4):{self.latlayer1(c4).shape}, p4:{p4.shape}')
p3 = self._upsample_add(p4, self.latlayer2(c3))
#print(f'latlayer1(c3):{self.latlayer2(c3).shape}, p3:{p3.shape}')
p2 = self._upsample_add(p3, self.latlayer3(c2))
#print(f'latlayer1(c2):{self.latlayer3(c2).shape}, p2:{p2.shape}')
# Smooth
p4 = self.smooth1(p4)
p3 = self.smooth2(p3)
p2 = self.smooth3(p2)
return p2, p3, p4, p5
def FPN101():
# return FPN(Bottleneck, [2,4,23,3])
return FPN(Bottleneck, [3,4,6,3])
def test():
net = FPN101()
fms = net(Variable(torch.randn(1,3,224,224)))
for fm in fms:
print(fm.size())
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/136601.html原文链接:https://javaforall.net


