
大家好,又见面了,我是你们的朋友全栈君。
近期适配几款游戏的数据,因为重复量太大,因此写一个对数据进行处理的程序,下面是整个过程中接触到的一些东西。
以下内容转载自:https://www.cnblogs.com/1242118789lr/p/6885691.html。
fstream提供了三个类,用来实现c++对文件的操作(文件的创建、读、写)
ifstream — 从已有的文件读入
ofstream — 向文件写内容
fstream – 打开文件供读写
文件打开模式:
ios::in 只读
ios::out 只写
ios::app 从文件末尾开始写,防止丢失文件中原来就有的内容
ios::binary 二进制模式
ios::nocreate 打开一个文件时,如果文件不存在,不创建文件
ios::noreplace 打开一个文件时,如果文件不存在,创建该文件
ios::trunc 打开一个文件,然后清空内容
ios::ate 打开一个文件时,将位置移动到文件尾
文件指针位置在c++中的用法:
ios::beg 文件头
ios::end 文件尾
ios::cur 当前位置
举个例子:
file.seekg(0,ios::beg); //让文件指针定位到文件开头
file.seekg(0,ios::end); //让文件指针定位到文件末尾
file.seekg(10,ios::cur); //让文件指针从当前位置向文件末方向移动10个字节
file.seekg(-10,ios::cur); //让文件指针从当前位置向文件开始方向移动10个字节
file.seekg(10,ios::beg); //让文件指针定位到离文件开头10个字节的位置
注意:移动的单位是字节,而不是行。
常用的错误判断方法:
good() 如果文件打开成功
bad() 打开文件时发生错误
eof() 到达文件尾
下面给出一个例子,读取hello.txt文件中的字符串,写入out.txt中:
#include <vector>
#include <string>
#include <fstream>
#include <iostream>
using namespace std;
int main()
{
ifstream myfile("G:\\C++ project\\Read\\hello.txt");
ofstream outfile("G:\\C++ project\\Read\\out.txt", ios::app);
string temp;
if (!myfile.is_open())
{
cout << "未成功打开文件" << endl;
}
while(getline(myfile,temp))
{
outfile << temp;
outfile << endl;
}
myfile.close();
outfile.close();
return 0;
}
其中getline的功能如下:
上述代码读取的是string类型的数据,那么对于int型数据该怎么办呢,其实道理差不多,下面举例说明:
#include<iostream>
#include <string>
#include <vector>
#include <fstream> //文件流库函数
using namespace std;
int cost[10][10];
int main()
{
int v, w, weight;
ifstream infile; //输入流
ofstream outfile; //输出流
infile.open("G:\\C++ project\\Read\\data.txt", ios::in);
if(!infile.is_open ())
cout << "Open file failure" << endl;
while (!infile.eof()) // 若未到文件结束一直循环
{
infile >> v >> w >> weight;
cost[v][w] = weight;
cost[w][v] = weight;
}
infile.close(); //关闭文件
outfile.open("G:\\C++ project\\Read\\result.txt", ios::app); //每次写都定位的文件结尾,不会丢失原来的内容,用out则会丢失原来的内容
if(!outfile.is_open ())
cout << "Open file failure" << endl;
for (int i = 0; i != 10; ++i)
{
for (int j = 0; j != 10; ++j)
{
outfile << i << "\t" << j << "\t" << cost[i][j] << endl; //在result.txt中写入结果
}
}
outfile.close();
return 0;
while (1);
}上述代码的功能是读取data.txt文件的数据,注意,此时要求data.txt文件中的数据是三个一行,每个数据用空格隔开,之所以这样做,是因为在许多项目中,比如某为的算法比赛中,根据图的数据构建图的邻接矩阵或者邻接表时,数据都是这样安排的,在上面的代码中v和w代表顶点标号,weight代表边<v,w>的权值,上述代码的功能就是构建由data.txt文件描述的图的邻近矩阵。
data.txt文件的数据如下:

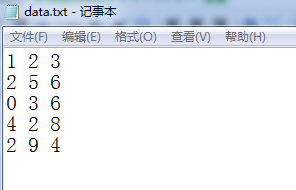
程序运行后,result.txt文件的内容如下:
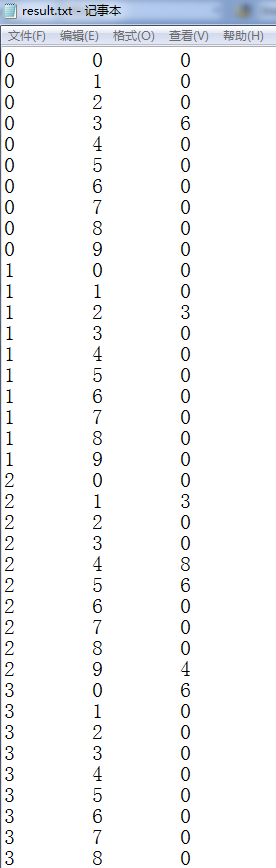
因为数据太长只给出一部分
事实上,要求data.txt文件中的数据都是如此排列的要求有点高,如果data.txt文件中有的行有两个数据,有的行有三个数据,有的行有4个数据,上述方法就行不通了,其实改一下上面的代码就可以了,重要的是你要明白什么时候读取的那一行有几个数据,下面举例说明:
假设data.txt文件中的数据如下:
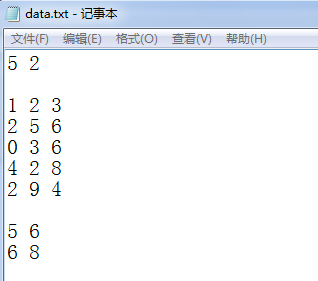
每行的数据都不一样多
第一行的数据表示,每行有三个数据的有5行,且在前面,每行有两个的数据的有两行,在后面,除第一行外,后面的才是正真的数据,因此读取这些数据的代码如下:
#include<iostream>
#include <string>
#include <vector>
#include <fstream> //文件流库函数
using namespace std;
int cost[10][10];
int main()
{
int Num_3,Num_2;
int v, w, weight;
ifstream infile; //输入流
ofstream outfile; //输出流
infile.open("G:\\C++ project\\Read\\data.txt", ios::in);
if(!infile.is_open ())
cout << "Open file failure" << endl;
infile >> Num_3 >>Num_2 ; //先读取第一行
while (0 != Num_3 ) // 读取3个数据的
{
infile >> v >> w >> weight;
cost[v][w] = weight;
cost[w][v] = weight;
Num_3--;
}
while (0 != Num_2) // 读取3个数据的
{
infile >> v >> w;
cost[v][w] = 100;
cost[w][v] = 100;
Num_2--;
}
infile.close(); //关闭文件
outfile.open("G:\\C++ project\\Read\\result.txt", ios::out); //每次写都定位的文件结尾,不会丢失原来的内容,用out则会丢失原来的内容
if(!outfile.is_open ())
cout << "Open file failure" << endl;
for (int i = 0; i != 10; ++i)
{
for (int j = 0; j != 10; ++j)
{
outfile << i << "\t" << j << "\t" << cost[i][j] << endl; //在result.txt中写入结果
}
}
outfile.close();
return 0;
while (1);
}为方便检验,我们把那些没有指明权值的边(即对应data.txt文件中那些每行只有两个数据的)的权值设为100,上述代码执行结果如下:
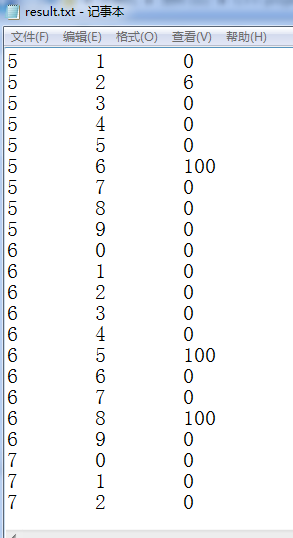
结果显示,读取正确。
注意:上面的代码之所以运行成立,是因为每行之间空几行好像并没有影响,比如上面的data.txt中,第一行与第二行之间空1行或者2行都没有关系。
二、string流
string头文件定义了三个类型来支持内存IO,istringstream向string读取数据,ostringstream从string写数据,stringstream既可从string读取数据也可向string写数据,就像string是一个IO流一样。
1、istringstream的用法,例子如下:
#include <string>
#include <sstream> //使用istringstream所需要的头文件
#include <iostream>
using namespace std;
int main()
{
string str = "Hello word! I am Lee";
istringstream is(str); //将is绑定到str
string s;
while (is >> s)
{
cout << s << endl;
}
return 0;
}上述代码运行结果如下:
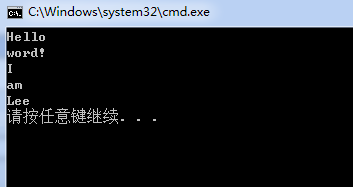
这相当于把一个句子拆分成单词,联系到前文提到的从文件中读取string的方法,如果读取到的string对象为一个句子,包含很多单词,那么我们就可以运用这种方法把string对象拆分开来。
2、ostringstream的用法
ostringstream同样是由一个string对象构造而来,ostringstream类向一个string插入字符。
#include <string>
#include <sstream> //使用ostringstream所需要的头文件
#include <iostream>
using namespace std;
int main()
{
ostringstream ostr;
// ostr.str("abc");//如果构造的时候设置了字符串参数,那么增长操作的时候不会从结尾开始增加,而是修改原有数据,超出的部分增长
ostr.put('d');
ostr.put('e');
ostr<<"fg";
string gstr = ostr.str();
cout<<gstr << endl;
return 0;
} 运行结果如下:
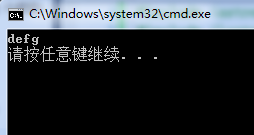
在上例代码中,我们通过put()或者左移操作符可以不断向ostr插入单个字符或者是字符串,通过str()函数返回增长过后的完整字符串数据,但值 得注意的一点是,当构造的时候对象内已经存在字符串数据的时候,那么增长操作的时候不会从结尾开始增加,而是修改原有数据,超出的部分增长。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/137002.html原文链接:https://javaforall.net

![【CSS使用技巧】[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
