
大家好,又见面了,我是你们的朋友全栈君。
InnoDB数据引擎使用B+树构造索引结构,其中的索引类型依据参与检索的字段不同可以分为主索引和非主索引;依据B+树叶子节点上真实数据的组织情况又可以分为聚族索引和非聚族索引。每一个索引B+树结构都会有一个独立的存储区域来存放,并且在需要进行检索时将这个结构加载到内存区域。真实情况是InnoDB引擎会加载索引B+树结构到内存的Buffer Pool区域。
聚簇索引(聚集索引)
聚簇索引指的是这样的数据组织结构:索引B+树的每个叶子节点直接对应了真实的Data Page。并且B+树所有的叶子节点在最底层共同描述了一个可以直接进行行数据顺序扫描的Data Page结构。如下图所示:
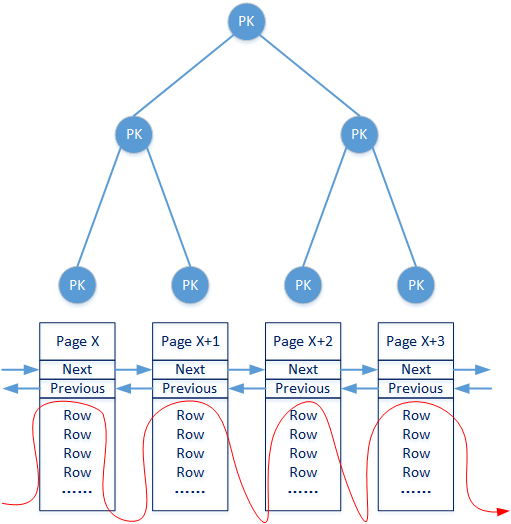

InnoDB引擎在组织索引和数据时,就是通过聚簇索引检索具体Data Page。而聚簇索引B+树的非叶子节点一般由数据表中的主键负责构造(当然也可能不是主键,这个后文会进行说明)。
主索引(主键索引/一级索引)
基于InnoDB引擎工作的每一张数据表都需要有一个主索引,这是因为上一段文字中提到的InnoDB引擎需要使用聚簇索引查找到具体的Data Page,而工作在InnoDB引擎下的数据表有且只有主索引采用聚簇索引的方式组织数据。也就是说主索引B+树的叶子节点都对应了真实的Data Page信息。
主索引在数据表的索引列表中使用PRIMARY关键字进行标识,一般来说是数据表的主键字段(也有可能是复合主键)。如果开发人员删除了InnoDB引擎中某张数据表的主索引,那么这个数据表将自行寻找一个非空且带有唯一约束的字段作为主索引。如果还是没有找到那样的字段**,InnoDB引擎将使用一个隐含字段作为主索引(ROWID)**。
B+树的构造特性在这里就得到了充分利用,因为只需要将主索引B+树的非叶子节点加载到内存中。当检索请求需要读取某一个具体的Data Page时,再从磁盘上进行读取。还记得在之前的文章中提到的预读操作吗?B+树最底层叶子节点组成的链表结构,让InnoDB引擎能够轻松进行临近的Data Page的读取——如果参数设定了需要那样做的话。
非聚簇索引(非聚集索引)
非聚族索引首先也是一颗B+树,只是非聚簇索引的叶子节点不再关联具体的Data Page信息,而是关联另一个索引值。InnoDB引擎下工作的每一个数据表虽然都只有一个聚簇索引,那就是它的主索引。但是每一张数据表可以有多个非聚簇索引,而后者的叶子节点全部存储着对应的数据主键信息(或者其它可以在聚簇索引中进行检索的关键值)。
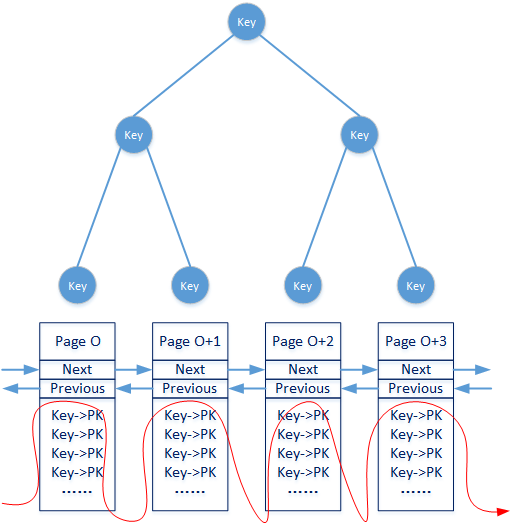
注意上图所示的B+树的叶子节点不再关联具体的Data Page信息,而只是关联了构成聚簇索引非叶子结点的主键信息。
非主索引(辅助索引/二级索引)
数据表索引列表中除去主索引以外的其它索引都称为非主索引。非主索引都是使用非聚簇索引方式组织数据,也就是说它们实际上是对聚簇索引进行检索的数据结构依据。
例如当开发人员创建了一个以字段A作为索引的非聚簇索引结构,并且在SQL中使用字段A作为查询条件执行检索时。InnoDB会首先使用非聚簇索引检索出对应的主键信息,然后再通过主索引检索这个主键对应的数据。
复合索引:
单一索引是指索引列为一列的情况,即新建索引的语句只实施在一列上; 用户可以在多个列上建立索引,这种索引叫做复合索引(组合索引);
复合索引在数据库操作期间所需的开销更小,可以代替多个单一索引; 同时有两个概念叫做窄索引和宽索引,窄索引是指索引列为1-2列的索引,宽索引也就是索引列超过2列的索引;
设计索引的一个重要原则就是能用窄索引不用宽索引,因为窄索引往往比组合索引更有效;
使用: 创建索引 create index idx1 on table1(col1,col2,col3) 查询 select * from table1 where col1= A and col2= B and col3 = C
这时候查询优化器,不在扫描表了,而是直接的从索引中拿数据,因为索引中有这些数据,这叫覆盖式查询,这样的查询速度非常快;
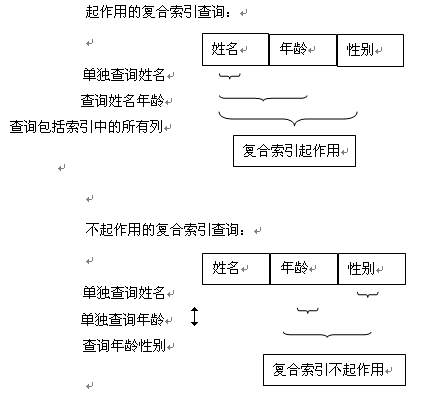
注意事项: 1、对于复合索引,在查询使用时,最好将条件顺序按找索引的顺序,这样效率最高; select * from table1 where col1=A AND col2=B AND col3=D
如果使用 where col2=B AND col1=A 或者 where col2=B 将不会使用索引
2、何时是用复合索引 根据where条件建索引是极其重要的一个原则; 注意不要过多用索引,否则对表更新的效率有很大的影响,因为在操作表的时候要化大量时间花在创建索引中
3、复合索引会替代单一索引么 如果索引满足窄索引的情况下可以建立复合索引,这样可以节约空间和时间
备注: 对一张表来说,如果有一个复合索引 on (col1,col2),就没有必要同时建立一个单索引 on col1; 如果查询条件需要,可以在已有单索引 on col1的情况下,
添加复合索引on (col1,col2),对于效率有一定的提高 同时建立多字段(包含5、6个字段)的复合索引没有特别多的好处,
相对而言,建立多个窄字段(仅包含一个,或顶多2个字段)的索引可以达到更好的效率和灵活性
CREATE TABLE tbl_camera_info (
`cameraId` varchar(64) NOT NULL COMMENT '镜头唯一编号,统一监控平台',
`cameraName` varchar(128) NOT NULL COMMENT '镜头名称',
`clientId` varchar(64) NOT NULL COMMENT '所属客户编号',
`clientName` varchar(128) DEFAULT NULL COMMENT '所属客户名称',
`lastTime` dateTime NOT NULL COMMENT '最后修改时间',
PRIMARY KEY (`cameraId`,`clientId`)
)ENGINE INNODB DEFAULT CHARSET=utf8 COMMENT='镜头设备信息总表';
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/137723.html原文链接:https://javaforall.net


