
大家好,又见面了,我是你们的朋友全栈君。
整理的答案 后面继续更新:
(1)spark运行流程、源码架构
https://blog.csdn.net/sghuu/article/details/103547937
(2)Hbase主键设计、hbase为何这么快?
主键设计:
1.生成随机数、hash、散列值
2.字符串反转
3.字符串拼接
hbase为何快:https://blog.csdn.net/sghuu/article/details/102955969
(3)Hbase读写流程,数据compact流程
hbase读写流程:
https://blog.csdn.net/sghuu/article/details/102708098
数据compact流程;
https://blog.csdn.net/sghuu/article/details/102956773
(4)Hadoop mapreduce流程
https://blog.csdn.net/sghuu/article/details/98985583
(5)Spark standalone模型、yarn架构模型(画出来架构图)
https://blog.csdn.net/sghuu/article/details/103547937
(6)Spark算子(map、flatmap、reducebykey和reduce、groupbykey和reducebykey、join、distinct)原理
(7)Spark stage的切分、task资源分配、任务调度、master计算资源分配
spark的stage的切分是根据宽依赖划分,最起码有一个ResultStage,从后往前每遇见一个宽依赖则会切分出一个ShuffleMapStage。
task的时stage的子集,根据并行度(分区数)来衡量,分区数是多少就有多少个task
spark的任务调度分为stage级别的调度和Task级别的调度
详细介绍切分流程和任务调度:
(8)Sparksql自定义函数、怎么创建dateframe
(9)Sparkstreaming项目多久一个批次数据
(10)Kafka复制机制、分区多副本机制
https://blog.csdn.net/tryll/article/details/86627696
(11)Hdfs读写流程,数据checkpoint流程
读流程:
https://blog.csdn.net/sghuu/article/details/98127600
写数据流程:
https://blog.csdn.net/sghuu/article/details/98122393
checkpoint流程:
https://blog.csdn.net/sghuu/article/details/98196539
(12)Sparkshuffle和hadoopshuffle原理、对比
(13)Hivesql怎么转化为MapReduce任务
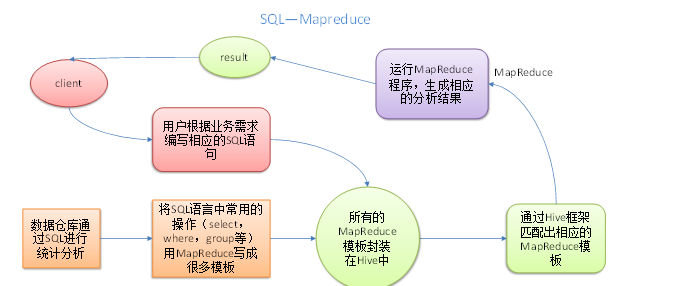

(14)Spark调优
spark的四个方面调优
(15)Spark数据倾斜解决方案
spark数据倾斜的6种解决
https://blog.csdn.net/sghuu/article/details/103710145
(16)Yarn工作流程、组成架构
https://blog.csdn.net/sghuu/article/details/102959135
(17)Zookeeper首领选取、节点类型、zookeeper实现原理
(18)hbase的ha,zookeeper在其中的作用
(19)spark的内存管理机制,spark1.6前后对比分析
(21)spark rdd、dataframe、dataset区别
(22)spark里面有哪些参数可以设置,有什么用
(23)hashpartitioner与rangePartitioner的实现
(24)spark有哪几种join
(25)spark jdbc(mysql)读取并发度优化
(26)Spark join算子可以用什么替代
(27)HBase region切分后数据是怎么分的
(28)项目集群结构(spark和hadoop集群)
(29)spark streaming是怎么跟kafka交互的,具体代码怎么写的,程序执行流程是怎样的,这个过程中怎么确保数据不丢(直连和receiver方式)
(30)kafka如何保证高吞吐的,kafka零拷贝,具体怎么做的
(31)hdfs的容错机制
(32)zookeeper怎么保证原子性,怎么实现分布式锁
(33)kafka存储模型与网络模型
(34)Zookeeper脑裂问题
Scala
(1)隐式转换
(2)柯理化
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/138440.html原文链接:https://javaforall.net


