
大家好,又见面了,我是你们的朋友全栈君。
pytorch之DataLoader
在训练神经网络时,最好是对一个batch的数据进行操作,同时还需要对数据进行shuffle和并行加速等。对此,PyTorch提供了DataLoader帮助实现这些功能。Dataset只负责数据的抽象,一次调用__getitem__只返回一个样本。
DataLoader的函数定义如下: DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, num_workers=0, collate_fn=default_collate, pin_memory=False, drop_last=False)
dataset:加载的数据集(Dataset对象)
batch_size:batch size
shuffle::是否将数据打乱
sampler: 样本抽样,后续会详细介绍
num_workers:使用多进程加载的进程数,0代表不使用多进程
collate_fn: 如何将多个样本数据拼接成一个batch,一般使用默认的拼接方式即可
pin_memory:是否将数据保存在pin memory区,pin memory中的数据转到GPU会快一些
drop_last:dataset中的数据个数可能不是batch_size的整数倍,drop_last为True会将多出来不足一个batch的数据丢弃
from torch.utils import data
import os
from PIL import Image
import torch as t
from torchvision import transforms as T
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
#定义transform1
normalize = T.Normalize(mean=[0.4, 0.4, 0.4], std=[0.2, 0.2, 0.2])
transform1 = T.Compose([
T.RandomResizedCrop(224),
T.RandomHorizontalFlip(),
T.ToTensor(),
normalize,
])

#实例化数据集dataset
dataset = ImageFolder('data1/dogcat_2/', transform=transform1)
#利用Dataloader函数加载
dataloader = DataLoader(dataset, batch_size=3, shuffle=True, num_workers=0, drop_last=False)
#取一个batch
dataiter = iter(dataloader)
imgs, labels = next(dataiter)
print(imgs.size()) # batch_size, channel, height, weighttorch.Size([3, 3, 224, 224])
print('*****')
for batch_datas, batch_labels in dataloader:
print(batch_datas.size(),batch_labels.size())

transform = T.Compose([
T.Resize(224), # 缩放图片(Image),保持长宽比不变,最短边为224像素
T.CenterCrop(224), # 从图片中间切出224*224的图片
T.ToTensor(), # 将图片(Image)转成Tensor,归一化至[0, 1]
T.Normalize(mean=[.5, .5, .5], std=[.5, .5, .5]) # 标准化至[-1, 1],规定均值和标准差
])
在数据处理中,有时会出现某个样本无法读取等问题,比如某张图片损坏。这时在__getitem__函数中将出现异常,此时最好的解决方案即是将出错的样本剔除。如果实在是遇到这种情况无法处理,则可以返回None对象,然后在Dataloader中实现自定义的collate_fn,将空对象过滤掉。但要注意,在这种情况下dataloader返回的batch数目会少于batch_size。
class DogCat(data.Dataset):
def __init__(self, root, transforms=None):
imgs = os.listdir(root)
self.imgs = [os.path.join(root, img) for img in imgs]
self.transforms=transforms
def __getitem__(self, index):
img_path = self.imgs[index]
label = 0 if 'dog' in img_path.split('/')[-1] else 1
data = Image.open(img_path)
if self.transforms:
data = self.transforms(data)
return data, label
def __len__(self):
return len(self.imgs)
class NewDogCat(DogCat): # 继承前面实现的DogCat数据集
def __getitem__(self, index):
try:
# 调用父类的获取函数,即 DogCat.__getitem__(self, index)
return super(NewDogCat,self).__getitem__(index)
except:
return None, None
from torch.utils.data.dataloader import default_collate # 导入默认的拼接方式
def my_collate_fn(batch):
'''
batch中每个元素形如(data, label)
'''
# 过滤为None的数据
batch = list(filter(lambda x:x[0] is not None, batch))
if len(batch) == 0: return t.Tensor()
return default_collate(batch) # 用默认方式拼接过滤后的batch数据
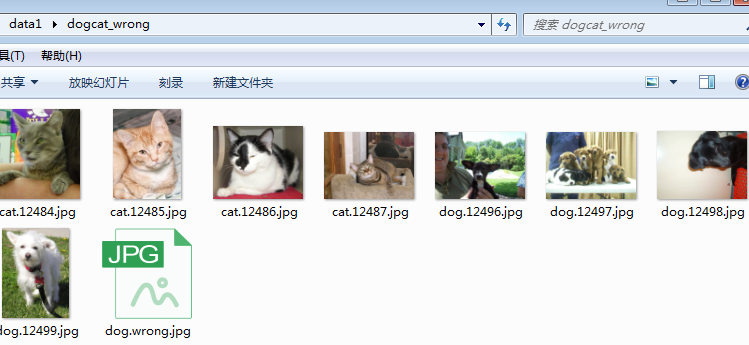
dataset = NewDogCat('data1/dogcat_wrong/', transforms=transform)
#print(dataset[5])
print('*************')
dataloader = DataLoader(dataset, 2, collate_fn=my_collate_fn,shuffle=True)
for batch_datas, batch_labels in dataloader:
print(batch_datas.size(),batch_labels.size())

来看一下上述batch_size的大小。其中第1个的batch_size为1,这是因为有一张图片损坏,导致其无法正常返回。而最后1个的batch_size也为1,这是因为共有9张(包括损坏的文件)图片,无法整除2(batch_size),因此最后一个batch的数据会少于batch_szie,可通过指定drop_last=True来丢弃最后一个不足batch_size的batch。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/138631.html原文链接:https://javaforall.net


