
大家好,又见面了,我是你们的朋友全栈君。
这里主要说下该论文的hard mining过程:
先上图,如Figure2所示:

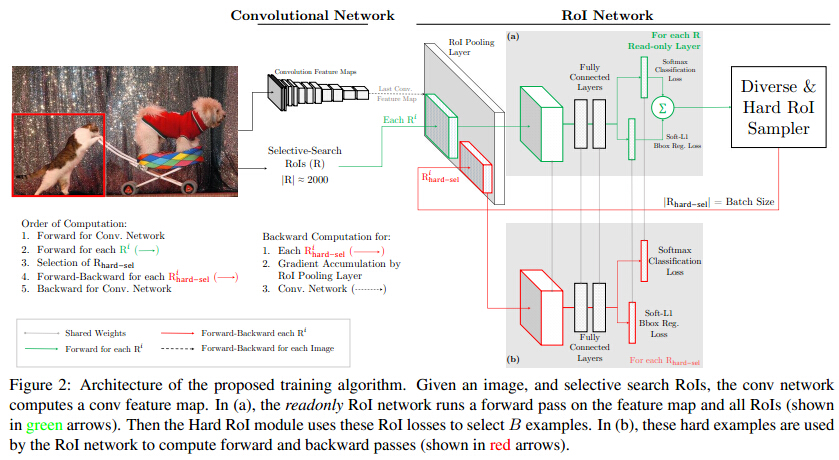
从图中可以看出,本文的亮点在于在每次迭代中,较少训练样本下,如何hard negative mining,来提升效果。
即针对Fast-RCNN框架,在每次minibatch(1张或者2张)训练时加入在线筛选hard region的策略,达到新的SoA。
需要注意的是,这个OHEM适合于batch size(images)较少,但每张image的examples很多的情况。
(thousands of candidate examples,这里的example可以理解为instance、region或者proposal)
这是一次ML经典算法bootstrapping在DL中的完美“嵌入”。
具体来说:
1 将Fast RCNN分成两个components:ConvNet和RoINet. ConvNet为共享的底层卷积层,RoINet为RoI Pooling后的层,包括全连接层;
2 对于每张输入图像,经前向传播,用ConvNet获得feature maps(这里为RoI Pooling层的输入);
3 将事先计算好的proposals,经RoI Pooling层投影到feature maps上,获取固定的特征输出作为全连接层的输入;
需要注意的是,论文说,为了减少显存以及后向传播的时间,这里的RoINet是有两个的,它们共享权重,
RoINet1是只读(只进行forward),RoINet2进行forward和backward:
a 将原图的所有props扔到RoINet1,计算它们的loss(这里有两个loss:cls和det);
b 根据loss从高到低排序,以及利用NMS,来选出前K个props(K由论文里的N和B参数决定)
为什么要用NMS? 显然对于那些高度overlap的props经RoI的投影后,
其在feature maps上的位置和大小是差不多一样的,容易导致loss double counting问题
c 将选出的K个props(可以理解成hard examples)扔到RoINet2,
这时的RoINet2和Fast RCNN的RoINet一样,计算K个props的loss,并回传梯度/残差给ConvNet,来更新整个网络
论文提及到可以用一种简单的方式来完成hard mining:
在原有的Fast-RCNN里的loss layer里面对所有的props计算其loss,根据loss对其进行排序,(这里可以选用NMS),选出K个hard examples(即props),
反向传播时,只对这K个props的梯度/残差回传,而其他的props的梯度/残差设为0即可。
由于这样做,容易导致显存显著增加,迭代时间增加,这对显卡容量少的童鞋来说,简直是噩梦。
为什么说是online?
论文的任务是region-based object detection,其examples是对props来说的,即使每次迭代的图像数为1,它的props还是会很多,即使hard mining后
为什么要hard mining:
1 减少fg和bg的ratio,而且不需要人为设计这个ratio;
2 加速收敛,减少显存需要这些硬件的条件依赖;
3 hard mining已经证实了是一种booststrapping的方式, 尤其当数据集较大而且较难的时候;
4 eliminates several heuristics and hyperparameters in common use by automatically selecting hard examples, thus simplifying training。
放宽了定义negative example的bg_lo threshold,即从[0.1, 0.5)变化到[0, 0.5)。
取消了正负样本在mini-batch里的ratio(原Fast-RCNN的ratio为1:3)
===
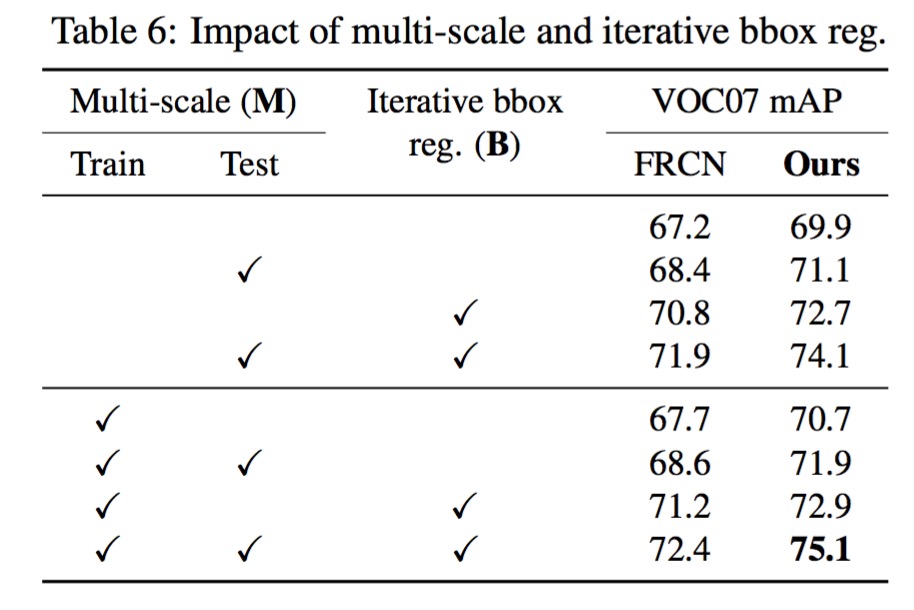
除了OHEM外,在训练过程中,论文用到了multi-scale的train&test、iterative bounding box regression这两种策略。具体参考fast-rcnn和sppnet这两篇论文。
===
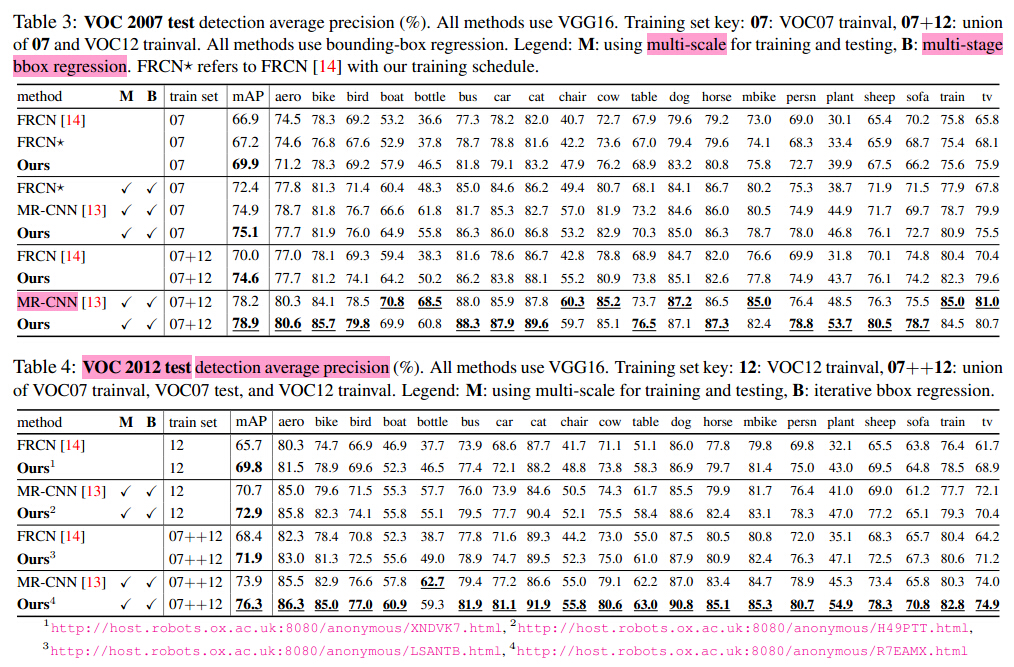
还是看效果说话,效果屌屌的。
参考:
https://blog.csdn.net/u012905422/article/details/52760669
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/139951.html原文链接:https://javaforall.net

![如何解决 VirtualBox 在安装 VB Guest additions(安装增强功能)时遇到的问题[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
