
大家好,又见面了,我是你们的朋友全栈君。
背景:
公司做数据仓库时,管理自己多张表时,需要使用数仓元数据管理系统进行管理。
一、Atlas简介
Atlas 是一个可伸缩且功能丰富、开源的元数据管理系统,深度对接了 Hadoop 大数据组件。
atlas 本身从技术上来说,就是一个典型的 JAVA WEB 系统,其整体结构图如下所示:
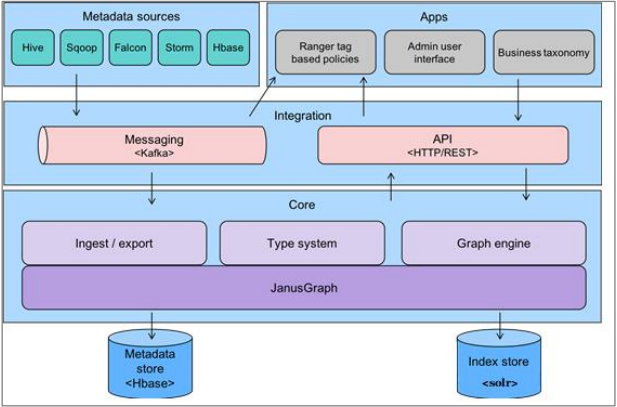

janusGraph (底层存储) :依赖于 hbase 和 solr
core (核心功能层): 相当于 javaee 里面的 service 层
integration(对外提供服务):相当于 javaee 里面的 controller 层
二、Atlas安装
1、下载源码包,并上传到linux,解压
tar -zxf apache-atlas-2.0.0-sources.tar.gz -C /opt/app/
2、执行 maven 编译打包
[root@h4 ~]# cd apache-atlas-sources-2.0.0/
[root@h4 apache-atlas-sources-2.0.0]# export MAVEN_OPTS="-Xms2g -Xmx2g"
[root@h4 apache-atlas-sources-2.0.0]# mvn clean -DskipTests package -Pdist,embedded-hbase-solr
3、Atlas 安装配置
若是之前安装了zookeeper,kafka,hbase直接启动就行
4、安装solr
[root@h3 solr]# bin/solr start -c -z h1:2181,h2:2181,h3:2181 -p 8984 -force
初始化 solr 中的索引数据
${SOLR}/bin/solr create -c vertex_index -shards 1 -replicationFactor 1 -force
${SOLR}/bin/solr create -c edge_index -shards 1 -replicationFactor 1 -force
${SOLR}/bin/solr create -c fulltext_index -shards 1 -replicationFactor 1 -force
5、配置及启动 atlas
上传 atlas 编译好之后的安装包
sftp> put d:/apache-atlas-bin-2.0.0.tar.gz /root/
修改配置文件
vi atlas-env.sh
export JAVA_HOME=/opt/app/jdk1.8.0_191/
export MANAGE_LOCAL_HBASE=false (如果要使用内嵌的 zk 和 hbase,则改为 true)
export MANAGE_LOCAL_SOLR=false (如果要是用内嵌的 solr,则改为 true)
export HBASE_CONF_DIR=/opt/apps/hbase-2.0.6/conf
vi atlas-application.properties
# Hbase 地址配置
atlas.graph.storage.hostname=doitedu01:2181,doitedu02:2181,doitedu03:2181
(如果使用内嵌 hbase,则填写 localhost:2181)
# Solr 地址配置
#Solr http mode properties
atlas.graph.index.search.solr.mode=http
atlas.graph.index.search.solr.http-urls=http://h3:8984/solr(solr 服务地址)
# Kafka 地址配置
atlas.notification.embedded=false (如果要使用内嵌的 kafka,则改为 true)
atlas.kafka.zookeeper.connect=doitedu01:2181,doitedu02:2181,doitedu03:2181
atlas.kafka.bootstrap.servers=doitedu01:9092,doitedu02:9092,doitedu03:9092
######### Server Properties #########
atlas.rest.address=http://doitedu01:21000
启动 atlas
[root@h3 apache-atlas-2.0.0]#
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/140168.html原文链接:https://javaforall.net


