
大家好,又见面了,我是你们的朋友全栈君。
一、 sklearn.linear_model.LinearRegression 线性回归
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html
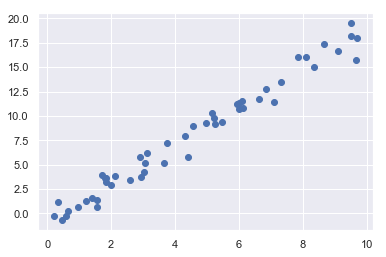
首先,要创建一组数据,随机选取一组x数据,然后计算出它在2x-1这条线附近对应的数据,画出其散点图:
# 演示简单的线性回归
import matplotlib.pyplot as plt
import numpy as np
rng = np.random.RandomState(42)
x = 10 * rng.rand(50)
y = 2 * x - 1 + rng.randn(50) # 在 2x-1上下附近的x对应的值
plt.scatter(x, y)

接下来,就按照步骤一步步实现:
1、选择模型类:
在这个例子中,我们想要计算一个简单的线性回归模型,可以直接导入线性回归模型类:
from sklearn.linear_model import LinearRegression
2、选择模型超参数
在上一步选择好模型类之后,还有许多的参数需要配置。比如下面的:
- 拟合偏移量(直线的截距)
- 对模型进行归一化处理
- 对特征进行预处理以提高模型灵活性
- 在模型中使用哪两种正则化类型
- 使用多少模型组件
对于这个线性回归实例,可以实例化 LinearRegression 类并用 fit_intercept 超参数设置是否想要拟合直线的截距。
>>>model = LinearRegression(fit_intercept=True) # fit_intercept为 True 要计算此模型的截距
>>>model
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None,
normalize=False)
可以看到model 的参数配置
3、将数据整理成特征矩阵和目标数组
根据Scikit-Learn的数据表示方法,它需要二维特征矩阵和一维目标数组。现在,我们已经有了长度为 n_samples 的目标数组,但还需要将数据 x 整理成 [n_samples, n_features] 的形式。 np.newaxis 是插入新维度。
>>>X = x[:, np.newaxis] # 将 x 数据整理成 [n_samples, n_features] 的形式
>>>X.shape
(50, 1)
4、用模型拟合数据
model.fit(X, y) # fit 拟合后的结果存在model属性中
所有通过fit方法获得的模型参数都带一条下划线。
>>>model.coef_ # 拟合的直线斜率
array([1.9776566])
>>>model.intercept_ # 拟合的直线截距
-0.9033107255311164
可以发现,拟合出来的直线斜率和截距和前面样本数据定义(斜率2,截距-1)非常接近。
5、预测新数据的标签
模型训练出来以后,有监督学习的主要任务变成了对不属于训练集的新数据进行预测。用 predict() 方法进行预测。“新数据”是特征矩阵的 x 的坐标值,我么需要用模型预测出目标数组的 y 轴坐标:
xfit = np.linspace(-1, 11) # 产生新数据,是特征矩阵的 x 的坐标值
将这些 x 值转换成[n_samples, n_features] 的特征矩阵形式,
Xfit = xfit[:, np.newaxis] # 将数据转变为[n_samples, n_features] 的形式
yfit = model.predict(Xfit) # 用模型预测目标数组的 y 轴坐标
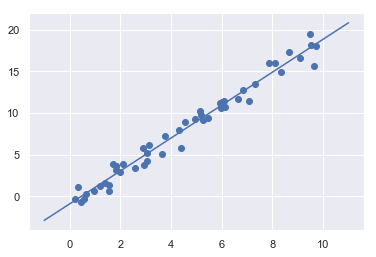
然后,把原始数据和拟合结果都可视化出来:
plt.scatter(x, y)
plt.plot(xfit, yfit)
二、鸢尾花数据分类
问题示例:如何为鸢尾花数据集建立模型,先用一部分数据进行训练,再用模型预测出其他样本的标签?
下面使用高斯朴素贝叶斯方法完成任务。由于需要用模型之前没有接触过的数据评估它的训练效果,因此得先将数据分割成训练集和测试集。可以借助 train_test_split 函数分割很方便:
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html
from sklearn.model_selection import train_test_split
xtrain, xtest, ytrain, ytest = train_test_split(x_iris,
y_iris, random_state=1) # 对数据进行分类
from sklearn.naive_bayes import GaussianNB
model = GaussianNB() # 初始化模型
model.fit(xtrain, ytrain) # 用模型拟合数据
y_model = model.predict(xtest) # 对新数据进行预测
from sklearn.metrics import accuracy_score
accuracy_score(ytest, y_model) # 输出模型预测准确率
0.9736842105263158
理清楚一下上面程序的过程:
- 把数据集分类成 xtrain, xtest, ytrain, ytest
- 用训练集数据 xtrain, ytrain 来进行拟合
- 根据拟合的结果来对 xtest 数据进行预测
- 得出预测结果 y_model 和原来结果 y_test 的准确率
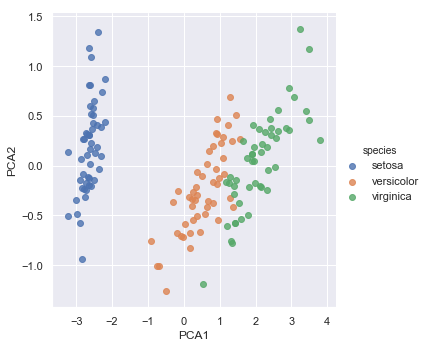
三、鸢尾花数据降维
PCA: https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html
PCA.fit_transform : https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html#sklearn.decomposition.PCA.fit_transform
sns.lmplot() : https://seaborn.pydata.org/generated/seaborn.lmplot.html
from sklearn.decomposition import PCA
model = PCA(n_components=2) # 设置超参数,初始化模型
model.fit(x_iris) # 拟合数据,这里不用y变量
x_2d = model.transform(x_iris) # 将数据转化成二维
iris['PCA1'] = x_2d[:, 0]
iris['PCA2'] = x_2d[:, 1]
sns.lmplot('PCA1', 'PCA2', hue='species', data=iris, fit_reg=False)
四、鸢尾花数据分类
对鸢尾花数据进行聚类。聚类算法是对没有任何标签的数据集进行分组。
GaussianMixture: https://scikit-learn.org/stable/modules/generated/sklearn.mixture.GaussianMixture.html
from sklearn.mixture import GaussianMixture
model = GaussianMixture(n_components=3, covariance_type='full')
model.fit(x_iris)
y_gmm = model.predict(x_iris)
iris['cluster'] = y_gmm
sns.lmplot('PCA1', 'PCA2', hue='species', data=iris, col='cluster', fit_reg=False)
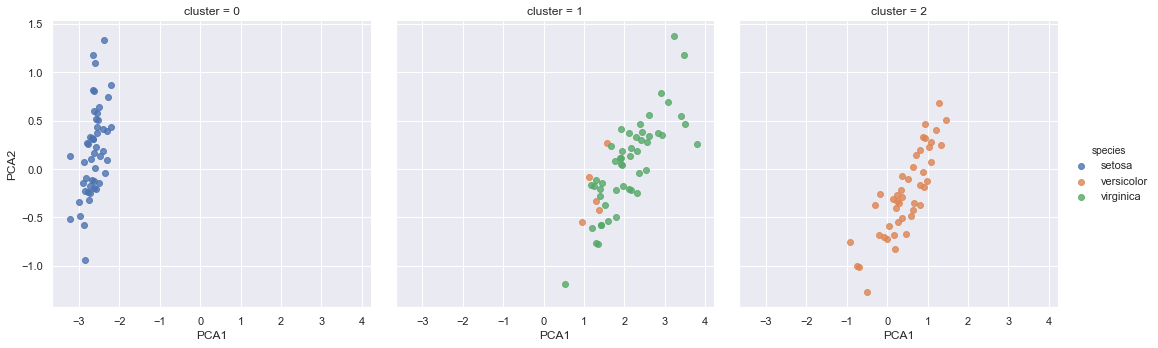
可以看出,第二幅图中的花的颜色还有一点混淆。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/140456.html原文链接:https://javaforall.net


