
大家好,又见面了,我是你们的朋友全栈君。
一、随机森林算法的基本思想
随机森林的出现主要是为了解单一决策树可能出现的很大误差和overfitting的问题。这个算法的核心思想就是将多个不同的决策树进行组合,利用这种组合降低单一决策树有可能带来的片面性和判断不准确性。用我们常说的话来形容这个思想就是“三个臭皮匠赛过诸葛亮”。
具体来讲,随机森林是用随机的方式建立一个森林,这个随机性表述的含义我们接下来会讲。随机森林是由很多的决策树组成,但每一棵决策树之间是没有关联的。在得到森林之后,当对一个新的样本进行判断或预测的时候,让森林中的每一棵决策树分别进行判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。
二、随机森林算法的构建过程
随机森林的构建需要有决策树的基础,不懂的童鞋需要先了解决策树算法的构建过程。对于随机森林来讲,核心的问题是如何利用一个数据集构建多个决策树,这个需要利用的就是随机的思想。在构建随机森林时需要利用两个方面的随机性选取:数据的随机性选取和待选特征的随机选取。
2.1、数据的随机选取
首先,从原始的数据集中采取有放回的抽样,构造子数据集,子数据集的数据量是和原始数据集相同的。不同子数据集的元素可以重复,同一个子数据集中的元素也可以重复。第二,利用子数据集来构建子决策树,将这个数据放到每个子决策树中,每个子决策树输出一个结果。最后,如果有了新的数据需要通过随机森林得到分类结果,就可以通过对子决策树的判断结果的投票,得到随机森林的输出结果了。利用下面的例子来说明随机森林的数据集的选取和判断.
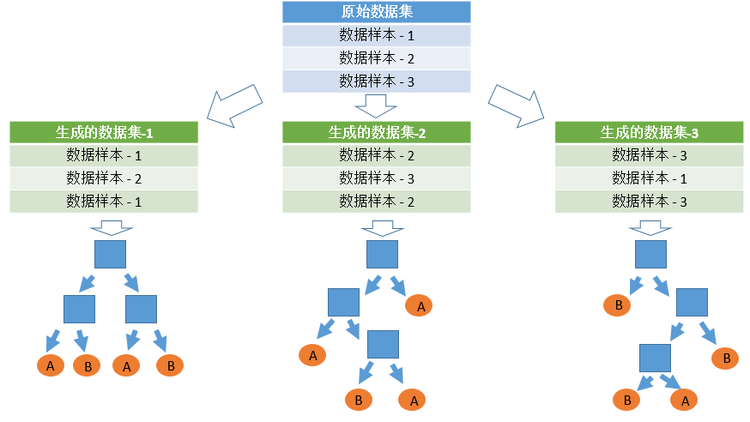

上图有一个原始数据集,利用原始数据集我们根据数据随机选取的方法生成三个新的数据集,然后利用这三个子数据集进行决策树判断。假设随机森林中就有这么3棵子决策树,2棵子树的分类结果是A类,1棵子树的分类结果是B类,那么根据投票原则随机森林的分类结果就是A类。
2.2、待选特征的随机选取
与数据集的随机选取类似,随机森林中的子树的每一个分裂过程并未用到所有的待选特征,而是从所有的待选特征中随机选取一定的特征,之后再在随机选取的特征中选取最优的特征。这样能够使得随机森林中的决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。以下图为例来说明随机选取待选特征的方法。
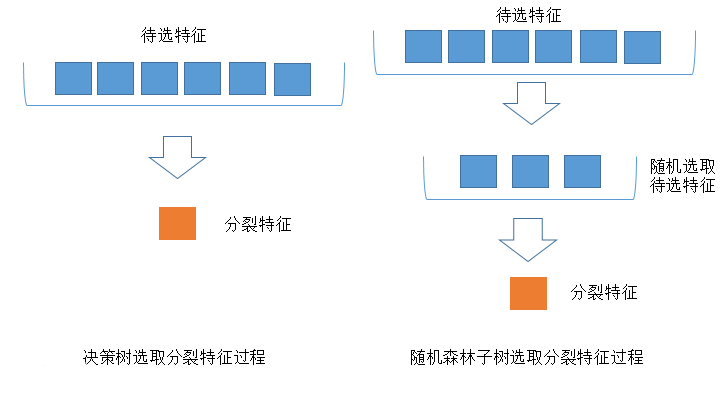
在上图中,蓝色的方块代表所有可以被选择的特征,也就是目前的待选特征。黄色的方块是分裂特征。左边是一棵决策树的特征选取过程,通过在待选特征中选取最优的分裂特征(利用决策树的ID3算法,C4.5算法,CART算法等等),完成分裂。右边是一个随机森林中的子树的特征选取过程。
三、随机森林算法的优缺点
3.1、随机森林的优点
a. 在数据集上表现良好,两个随机性的引入,使得随机森林不容易陷入过拟合;
b. 在当前的很多数据集上,相对其他算法有着很大的优势,两个随机性的引入,使得随机森林具有很好的抗噪声能力;
c. 它能够处理很高维度(feature很多)的数据,并且不用做特征选择,对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无需规范化;
d. 可生成一个Proximities=(pij)矩阵,用于度量样本之间的相似性: pij=aij/N, aij表示样本i和j出现在随机森林中同一个叶子结点的次数,N随机森林中树的颗数;
e. 在创建随机森林的时候,对generlization error使用的是无偏估计;
f. 训练速度快,可以得到变量重要性排序(两种:基于OOB误分率的增加量和基于分裂时的GINI下降量;
g. 在训练过程中,能够检测到feature间的互相影响;
h. 容易做成并行化方法;
i. 实现比较简单。
3.2、随机森林的缺点
a. 在某些噪音比较大的样本集上,RF模型容易陷入过拟合。
b. 取值划分比较多的特征容易对RF的决策产生更大的影响,从而影响拟合的模型的效果。
四、随机森林算法的应用范围
随机森林主要应用于回归和分类。本文主要探讨基于随机森林的分类问题。随机森林和使用决策树作为基本分类器的(bagging)有些类似。以决策树为基本模型的bagging在每次bootstrap放回抽样之后,产生一棵决策树,抽多少样本就生成多少棵树,在生成这些树的时候没有进行更多的干预。而随机森林也是进行bootstrap抽样,但它与bagging的区别是:在生成每棵树的时候,每个节点变量都仅仅在随机选出的少数变量中产生。因此,不但样本是随机的,连每个节点变量(Features)的产生都是随机的。
许多研究表明,组合分类器比单一分类器的分类效果好,随机森林(random forest)是一种利用多个分类树对数据进行判别与分类的方法,它在对数据进行分类的同时,还可以给出各个变量(基因)的重要性评分,评估各个变量在分类中所起的作用。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/142652.html原文链接:https://javaforall.net


