
大家好,又见面了,我是你们的朋友全栈君。
一 安装显卡驱动:
直接在系统软件更新中选择安装:
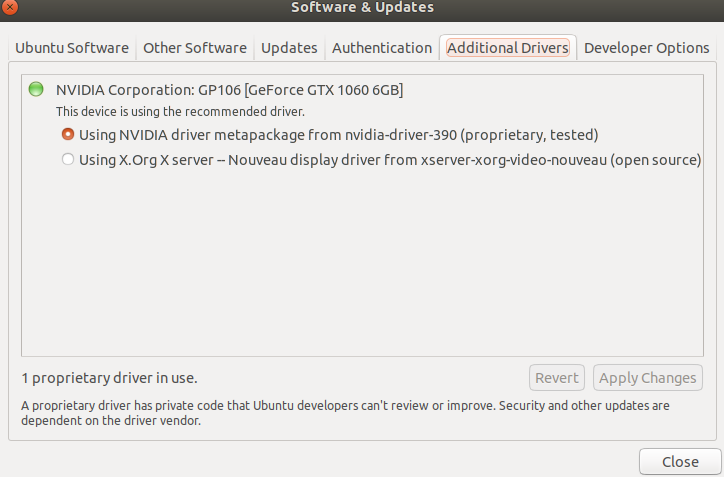

或者选择PPA源安装,参照:https://blog.csdn.net/new_delete_/article/details/81544438
输入命令测试是否安装成功:
nvidia-smi二、安装CUDA
1、安装gcc-6 g++-6(由于CUDA 9.0仅支持GCC 6.0及以下版本,而Ubuntu 18.04预装GCC版本为7.3)
sudo apt-get install gcc-6 g++-6
2、修改gcc、g++ 默认版本
cd /usr/bin
sudo rm gcc
sudo ln -s gcc-6 gcc
sudo rm g++
sudo ln -s g++-6 g++3 去官网下载CUDA9.0 地址:https://developer.nvidia.com/cuda-toolkit-archive
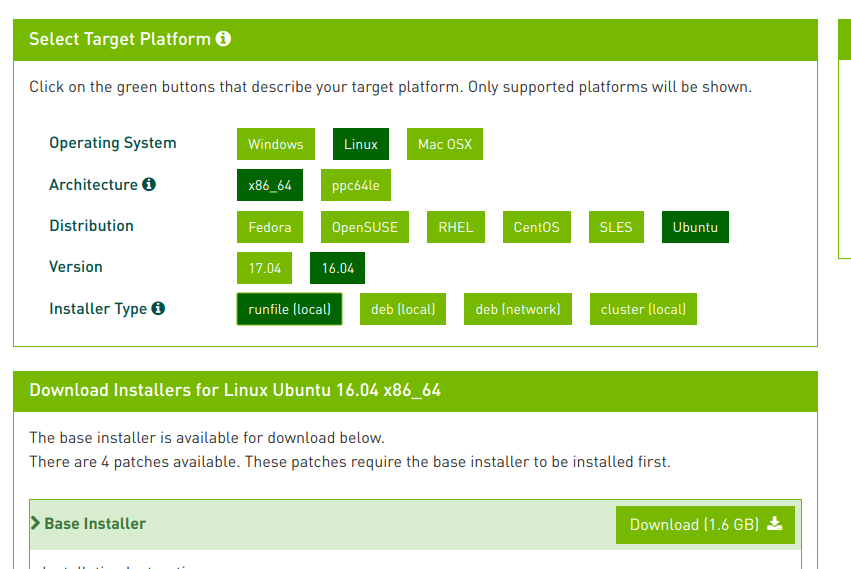
3、安装:
sudo chmod +x cuda_9.0.176_384.81_linux.run
sudo ./cuda_9.0.176_384.81_linux.run 如果已经安装驱动,就不要再选择安装驱动了
4、添加环境变量:
打开~/.bashrc
sudo gedit ~/.bashrc在文件末尾添加以下命令:
export CUDA_HOME=/usr/local/cuda
export PATH=$PATH:$CUDA_HOME/bin
export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}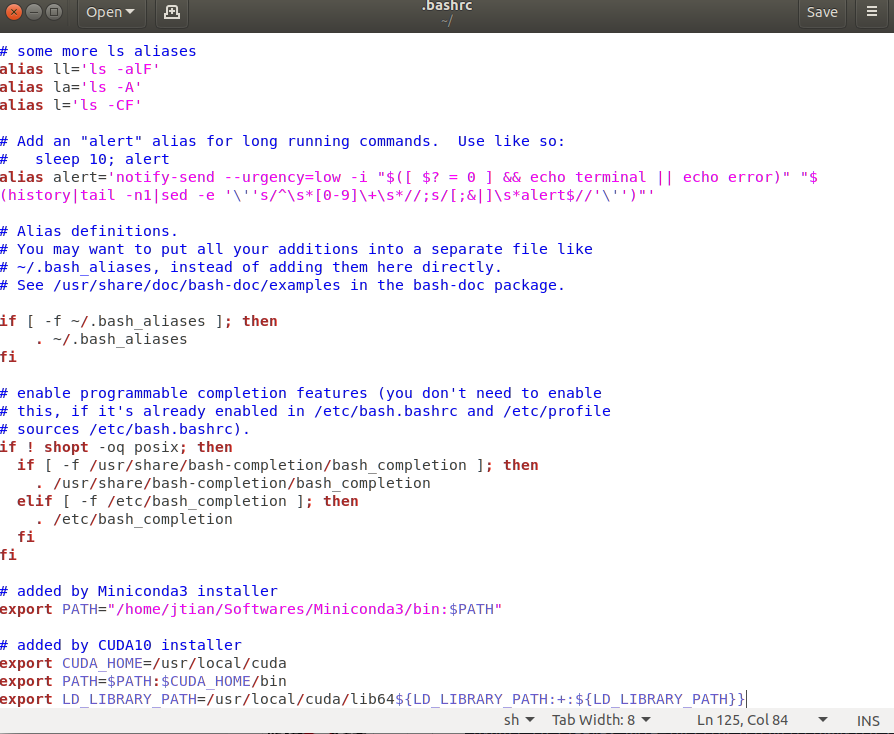
5、测试是否安装成功:
nvcc -V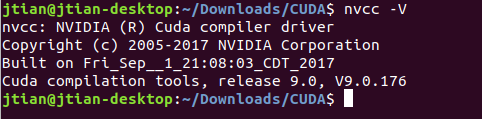
三、 安装CUDNN
在官网下载相应的版本(deb包):地址:https://developer.nvidia.com/rdp/cudnn-download(需要注册登陆)
2、安装cudnn的deb包
sudo dpkg -i libcudnn7_7.4.1.5-1+cuda9.0_amd64.deb
完成
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/143820.html原文链接:https://javaforall.net


