
大家好,又见面了,我是你们的朋友全栈君。
自动编码器
三层网络结构:输入层,编码层(隐藏层),解码层。
训练结束后,网络可由两部分组成:1)输入层和中间层,用这个网络对信号进行压缩;2)中间层和输出层,用这个网络对压缩的信号进行还原。图像匹配就可以分别使用,首先将图片库使用第一部分网络得到降维后的向量,再讲自己的图片降维后与库向量进行匹配,找出向量距离最近的一张或几张图片,直接输出或还原为原图像再匹配。
该网络的目的是重构其输入,使其隐藏层学习到该输入的良好表征。其学习函数为 h(x)≈x h ( x ) ≈ x 。但如果输入完全等于输出,即 g(f(x))=x g ( f ( x ) ) = x ,该网络毫无意义。所以需要向自编码器强加一些约束,使它只能近似地复制。这些约束强制模型考虑输入数据的哪些部分需要被优先复制,因此它往往能学习到数据的有用特性。一般情况下,我们并不关心AE的输出是什么(毕竟与输入基本相等),我们所关注的是encoder,即编码器生成的东西,在训练之后,encoded可以认为已经承载了输入的主要内容。
自动编码器属于神经网络家族,但它们与PCA(主成分分析)紧密相关。尽管自动编码器与PCA很相似,但自动编码器比PCA灵活得多。在编码过程中,自动编码器既能表征线性变换,也能表征非线性变换;而PCA只能执行线性变换。
从不同的角度思考特征具有何种属性是好的特征,自动编码器分为四种类型:
(1)去燥自动编码器(DAE)(降噪)
(2)稀疏自动编码器(SAE,Sparse Autoencoder)(稀疏性,即高而稀疏的表达)
(3)变分自动编码器(VAE)(高斯分布)
(4)收缩自动编码器(CAE/contractive autoencoder)(对抗扰动)
去燥自编码器(DAE)
最基本的一种自动编码器,它会随机地部分采用受损的输入(就是将输入做噪声处理或某些像素置零处理)来解决恒等函数风险,使得自动编码器必须进行恢复或去燥。(处理过程为输入有噪声,目标函数为原图像)。损失函数为 L(x,g(f(x‘))) L ( x , g ( f ( x ‘ ) ) ) ,其中 x‘ x ‘ 是含噪声的输入。
这项技术可用于得到输入的良好表征。良好的表征是指可以从受损的输入(应该就是中间层encoder输出的那个较低维的)稳健地获得的表征,该表征可被用于恢复其对应的无噪声输入。
稀疏自编码器(SAE)
与常规的AE结构相似,只是隐藏层要比原输入要高维,且要让其稀疏,即大部分为0。其损失函数为: Jsparse(W,b)=J(W,b)+β∑s2j=1KL(ρ∥ρ⃗ j) J s p a r s e ( W , b ) = J ( W , b ) + β ∑ j = 1 s 2 K L ( ρ ‖ ρ → j ) ,其中 β β 是控制稀疏性的权重, ρ ρ 为平均激活度, ρ⃗ j ρ → j 为实际激活度。
变分自编码器(VAE)
与传统AE输出的隐藏层不同,其给隐藏层加了一个约束:迫使隐藏层产生满足高斯分布的变量,即均值趋于0,方差趋于1。
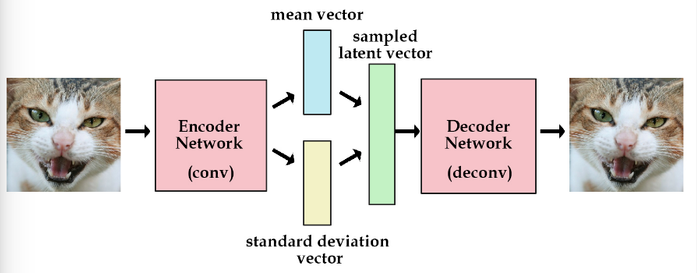

收缩自编码器(CAE)
收缩编码器学习的是一个在输入 x 变化小时目标也没太大变化的函数。其损失函数为 Jc=J(x,g(h))+λ∑i∥▽xhi∥2F J c = J ( x , g ( h ) ) + λ ∑ i ‖ ▽ x h i ‖ F 2 ,F范数的意义在于想要隐藏层的导数尽可能的小。
为什么自动编码器大多显示3层结构,训练多层时需要多次使用?
三层网络是单个自编码器所形成的网络,对于任何基于神经网络的编码器都是如此。如果需要多层的编码器,通过逐层训练的形式完成,这就是堆叠自动编码器。如果直接用多层的自动编码器,其本质就是在做深度学习的训练,可能会由于梯度爆炸或梯度消失导致难以训练的问题。而逐层训练可以直接使用前面已经能提取完好特征的网络,使得整个网络的初始化在一个合适的状态,便于收敛。但是,在2014年出现的Batch-Normalization技术【良好的初始化技术】比逐层训练有效的多。再后来,发现基于残差(ResNet)我们基本可以训练任意深度的网络。
自动编码器目前主要应用于 (1) 数据去噪 (2) 可视化降维 (3)特征提取
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/143959.html原文链接:https://javaforall.net


