
大家好,又见面了,我是你们的朋友全栈君。
无意中发现了一个巨牛的人工智能教程,忍不住分享一下给大家。教程不仅是零基础,通俗易懂,而且非常风趣幽默,像看小说一样!觉得太牛了,所以分享给大家。点这里可以跳转到教程。


之前的几篇关于性能监控平台搭建的文章,分别介绍了性能测试中的资源数据采集、存储及展示。今天一起来看下如何完成Locust性能数据的采集。
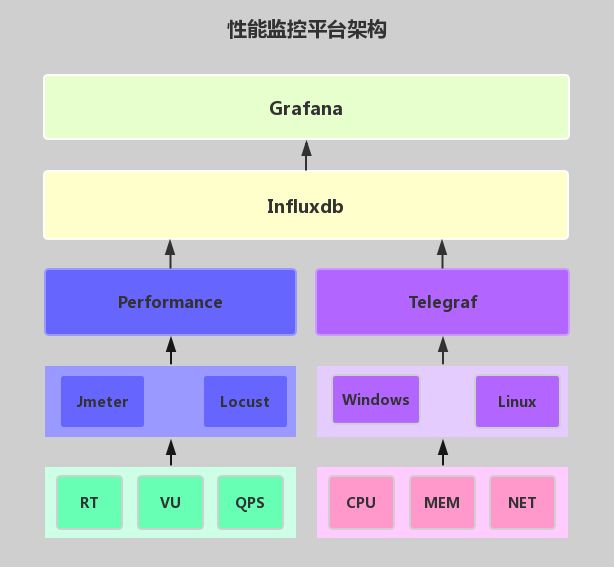
这是之前介绍过的性能监控平台的整体架构图,想要了解其它部分的搭建,可以查看相关文章《Telegraf安装与简易使用指南》、《InfluxDB安装与简易使用指南》、《Grafana安装与简易使用指南》
因为我们已经完成了资源数据的采集,以及监控数据的存储与展示,剩下的就是采集性能数据了。规划中我们需要支持采集JMeter和Locust工具的性能数据,今天先讲解如何采集Locust的性能数据。
问题概述
如果你使用过Locust,那么你一定知道Locust本身自带一个WEB服务,它提供了性能测试过程中的性能数据监控,并且也提供了一个图形的界面支持实时监控,完事了还可以下载csv格式的性能测试数据。
既然Locust已经有了性能数据的监控功能,为哈还要接入到性能监控平台呢?因为Locust里的数据没有主动持久化,一旦刷新就没有了;也不会自动保存历史数据;不能对数据进行定制化展示,不能在同一个平台中查看全部的性能数据。
为此我们要解决的就是把Locust性能工具中的性能数据实时的获取到并存储到Influxdb中,这样就完美的解决了Locust性能数据集成问题,让监控平台可以无缝的支持Locust工具。
获取Locust性能数据接口
既然要采集性能测试数据,那么首先要考虑的就是如何获取性能测试数据?是修改源码?还是开发插件?这些统统不要!因为Locust本身就已经有了性能数据监控服务,通过抓取Locust的WEB服务页面请求,很方便的就得到了Locust的性能监控数据。比如:
curl http://localhost:8089/stats/requests
该URL会返回当前性能测试到目前为止的性能测试数据的总结信息,所以这些我们需要的性能数据基本上Locust已经为我们打包好了,我们之前请求这个url就可以实时的获取到。
定时采集性能数据
数据获取的方式已经知道了,接下来考虑的就是在什么时候获取数据的问题。最简单粗暴的方式就是写一个定时任务去请求该URL,获取数据后直接存储到Influxdb即可。代码如下:
def get_locust_stats_by_web_api():
print("get_locust_stats")
try:
start_url = f'http://localhost:8089/stats/requests'
print(start_url)
return requests.get(start_url).json()
except Exception as e:
print(e)
而这样做的弊端则是定时任务与性能测试启停的一致性需要人为的控制,用户友好性不够。我们希望的是性能测试一开始它就自动开始采集性能数据,性能测试一结束它就停止采集性能数据,要做到对目前的性能测试操作尽量无侵入。
性能数据采集一致性
为了解决性能数据采集与性能测试之间的一致性问题,我们需要把代码集成到Locust性能测试脚本中,让它跟脚本绑定,这样一旦开始执行性能测试,就会触发性能数据采集的定时任务,从根本上解决了一致性问题。
no-web模式下获取性能数据
前面我们获取Locust性能测试数据时,是通过/stats/requests接口获取到的。这个接口是基于WEB模式下,一旦我们选择以no-web的方式启动Locust,那么这个接口就会失效了。
为了兼容no-web模式下也能正常采集到Locust的性能数据,可以直接把/stats/requests接口生成性能测试数据的代码直接COPY过来即可,所以获取Locust性能测试数据的方法需要改写成这样:
def get_locust_stats():
stats = []
for s in chain(sort_stats(runners.locust_runner.request_stats), [runners.locust_runner.stats.total]):
stats.append({
"method": s.method,
"name": s.name,
"num_requests": s.num_requests,
"num_failures": s.num_failures,
"avg_response_time": s.avg_response_time,
"min_response_time": s.min_response_time or 0,
"max_response_time": s.max_response_time,
"current_rps": s.current_rps,
"median_response_time": s.median_response_time,
"avg_content_length": s.avg_content_length,
})
errors = [e.to_dict() for e in six.itervalues(runners.locust_runner.errors)]
# Truncate the total number of stats and errors displayed since a large number of rows will cause the app
# to render extremely slowly. Aggregate stats should be preserved.
report = {
"stats": stats[:500], "errors": errors[:500]}
if stats:
report["total_rps"] = stats[len(stats) - 1]["current_rps"]
report["fail_ratio"] = runners.locust_runner.stats.total.fail_ratio
report[
"current_response_time_percentile_95"] = runners.locust_runner.stats.total.get_current_response_time_percentile(
0.95)
report[
"current_response_time_percentile_50"] = runners.locust_runner.stats.total.get_current_response_time_percentile(
0.5)
is_distributed = isinstance(runners.locust_runner, MasterLocustRunner)
if is_distributed:
slaves = []
for slave in runners.locust_runner.clients.values():
slaves.append({
"id": slave.id, "state": slave.state, "user_count": slave.user_count})
report["slaves"] = slaves
report["state"] = runners.locust_runner.state
report["user_count"] = runners.locust_runner.user_count
return report
slave模式下不进行数据采集
同样的Locust还有分布式模式,一旦采用该模式之后Locust性能脚本会在master和各slave节点都会执行,但是很明显我们不希望接收到多次重复的性能采集数据,所以需要保证只有在master上的性能脚本才会进行性能数据采集。
def monitor(project_name):
print("start monitoring")
slave = isinstance(runners.locust_runner, SlaveLocustRunner)
if slave: # 判断是否为slave
print('is slave, will not rerun')
return
try:
rep = get_locust_stats()
if rep['state'] == 'running':
host = get_locust_host()
save_to_db(project_name, host, rep)
print(f'is_slave: {slave}, host: {host}, project_name: {project_name}')
else:
print('it is not running now')
except Exception as e:
print(e)
timer = threading.Timer(interval, monitor, args=[project_name]) # 定时任务
timer.start()
封装
当然,我们也不希望把这么多的性能数据采集的代码直接写在Locust的性能测试脚本中,即不美观也不容易管理。所以需要把这些采集数据的代码统一封装到一个独立文件中,并对外提供一个调用入口,只要简单引入即可。调用代码如下:
from locust import HttpLocust, TaskSet, task, events
from locust2db import start # 引入性能采集模块
start('locust_monitoring') # 调用性能采集模块
class WebsiteTasks(TaskSet):
def on_start(self):
self.client.get("/login")
@task
def index(self):
self.client.get("/")
class WebsiteUser(HttpLocust):
task_set = WebsiteTasks
host = 'https://www.testqa.cn'
min_wait = 1000
max_wait = 1000
好啦!!!关于Locust性能测试数据的采集实现方法和关键代码已经介绍完了。如果想获取完整代码请关注TestQA公众号,回复locust2db即可。

发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/144047.html原文链接:https://javaforall.net


