
大家好,又见面了,我是你们的朋友全栈君。
开源改变世界,拥抱开源,拥抱未来
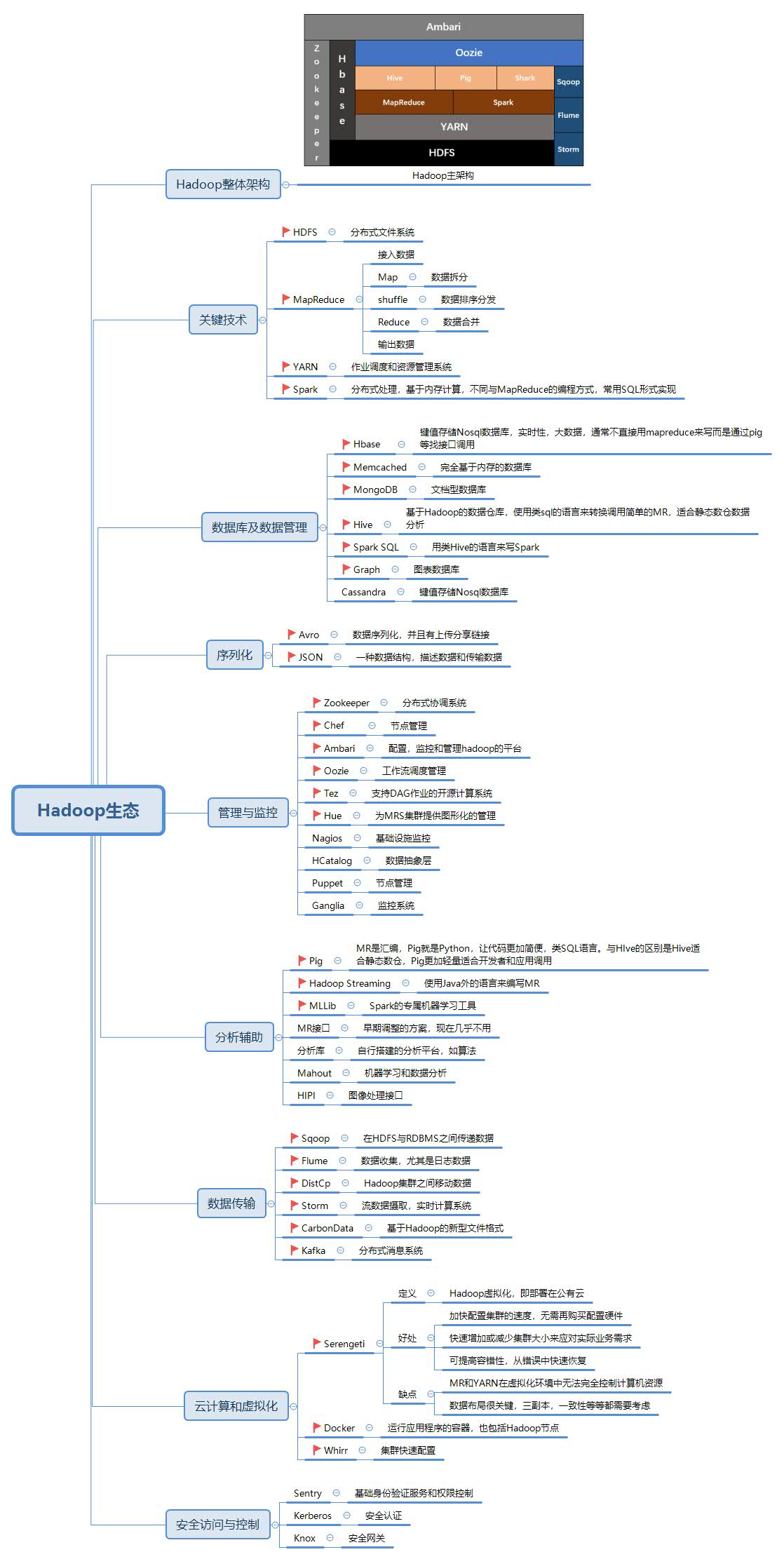
Hadoop生态系统组件介绍,掌握吹x大法,走到哪里都不怕


| 功能模块 | 产品名称 | 产品简述 |
|---|---|---|
| 关键技术 | HDFS | 分布式文件系统 |
| MapReduce | 数据处理编程:map(数据拆分),shuffle(数据排序分发),reduce(数据合并) | |
| YARN | 资源管理系统 | |
| Spark | 基于内存计算,完全不同与MapReduce的编程方式,常用SQL形式实现 | |
|
数据库及 数据管理 |
Cassandra | 键值存储Nosql数据库 |
| Hbase | 键值存储Nosql数据库,通常不直接用mapreduce来写而是通过pig等找接口调用 | |
| Memcached | 完全基于内存的数据库 | |
| MongoDB | 文档型数据库 | |
| Hive | 不是每个人都会写MR,所以需要写SQL来转换调用MR,即HiveSQL | |
| Spark SQL | 用类Hive的语言来写Spark | |
| Graph | 图表数据库 | |
| 序列化 | Avro | 数据序列化,并且有上传分享链接 |
| JSON | 一种数据结构,描述数据和传输数据 | |
| 管理与监控 | Zookeeper | 分布式协调系统 |
| Chef | 节点管理 | |
| Puppet | 节点管理 | |
| Nagios | 基础设施监控 | |
| Ambari | 配置,监控和管理hadoop的平台 | |
| HCatalog | 数据抽象层 | |
| Oozie | 工作流调度管理 | |
| Ganglia | 监控系统 | |
| 分析辅助 | MR接口 | 早期调整的方案,现在几乎不用 |
| 分析库 | 自行搭建的分析平台,如算法 | |
| Pig | MR是汇编,Pig就是Python,让代码更加简便,类SQL语言。与HIve的区别是Hive适合静态数仓,Pig更加轻量适合开发者和应用调用 | |
| Hadoop Streaming | 使用Java外的语言来编写MR | |
| Mahout | 机器学习和数据分析 | |
| MLLib | Spark的专属机器学习工具 | |
| HIPI | 图像处理接口 | |
| 数据传输 | Sqoop | 在HDFS与RDBMS之间传递数据 |
| Flume | 数据收集,尤其是日志数据 | |
| DistCp | Hadoop集群之间移动数据 | |
| Storm | 流数据摄取 | |
|
云计算与 虚拟化 |
Serengeti | Hadoop虚拟化,即部署在公有云,好处是加快配置集群的速度,无需再购买配置硬件;快速增加或减少集群大小来应对实际业务需求;可提高容错性,从错误中快速恢复。缺点是MR和YARN在虚拟化环境中无法完全控制计算机资源;数据布局很关键,三副本,一致性等等都需要考虑 |
| Docker | 运行应用程序的容器,也包括Hadoop节点 | |
| Whirr | 集群快速配置 | |
|
安全访问与 控制 |
Sentry | 基础身份验证服务和权限控制 |
| Kerberos | 安全认证 | |
| Knox | 安全网关 |
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/144581.html原文链接:https://javaforall.net


