
大家好,又见面了,我是你们的朋友全栈君。


# Program Name: NSGA-II.py
# Description: This is a python implementation of Prof. Kalyanmoy Deb's popular NSGA-II algorithm
# Author: Haris Ali Khan
# Supervisor: Prof. Manoj Kumar Tiwari
"""
优化目标:
min(f1(x), f2(x))
f1(x) = -x^2
f2(X) = -(x-2)^2
s.t x~[-55, 55]
pop_size = 20
max_gen = 921
"""
#Importing required modules
import math
import random
import matplotlib.pyplot as plt
#First function to optimize
def function1(x):
value = -x**2
return value
#Second function to optimize
def function2(x):
value = -(x-2)**2
return value
#Function to find index of list
def index_of(a,list):
for i in range(0,len(list)):
if list[i] == a:
return i
return -1
#Function to sort by values
def sort_by_values(list1, values):
sorted_list = []
while(len(sorted_list)!=len(list1)):
if index_of(min(values),values) in list1:
sorted_list.append(index_of(min(values),values))
values[index_of(min(values),values)] = math.inf
return sorted_list
#Function to carry out NSGA-II's fast non dominated sort
def fast_non_dominated_sort(values1, values2):
S=[[] for i in range(0,len(values1))]
front = [[]]
n=[0 for i in range(0,len(values1))]
rank = [0 for i in range(0, len(values1))]
for p in range(0,len(values1)):
S[p]=[]
n[p]=0
for q in range(0, len(values1)):
if (values1[p] > values1[q] and values2[p] > values2[q]) or\
(values1[p] >= values1[q] and values2[p] > values2[q]) or\
(values1[p] > values1[q] and values2[p] >= values2[q]):
if q not in S[p]:
S[p].append(q)
elif (values1[q] > values1[p] and values2[q] > values2[p]) or\
(values1[q] >= values1[p] and values2[q] > values2[p]) or\
(values1[q] > values1[p] and values2[q] >= values2[p]):
n[p] = n[p] + 1
if n[p]==0:
rank[p] = 0
if p not in front[0]:
front[0].append(p)
i = 0
while(front[i] != []):
Q=[]
for p in front[i]:
for q in S[p]:
n[q] =n[q] - 1
if( n[q]==0):
rank[q]=i+1
if q not in Q:
Q.append(q)
i = i+1
front.append(Q)
del front[len(front)-1]
return front
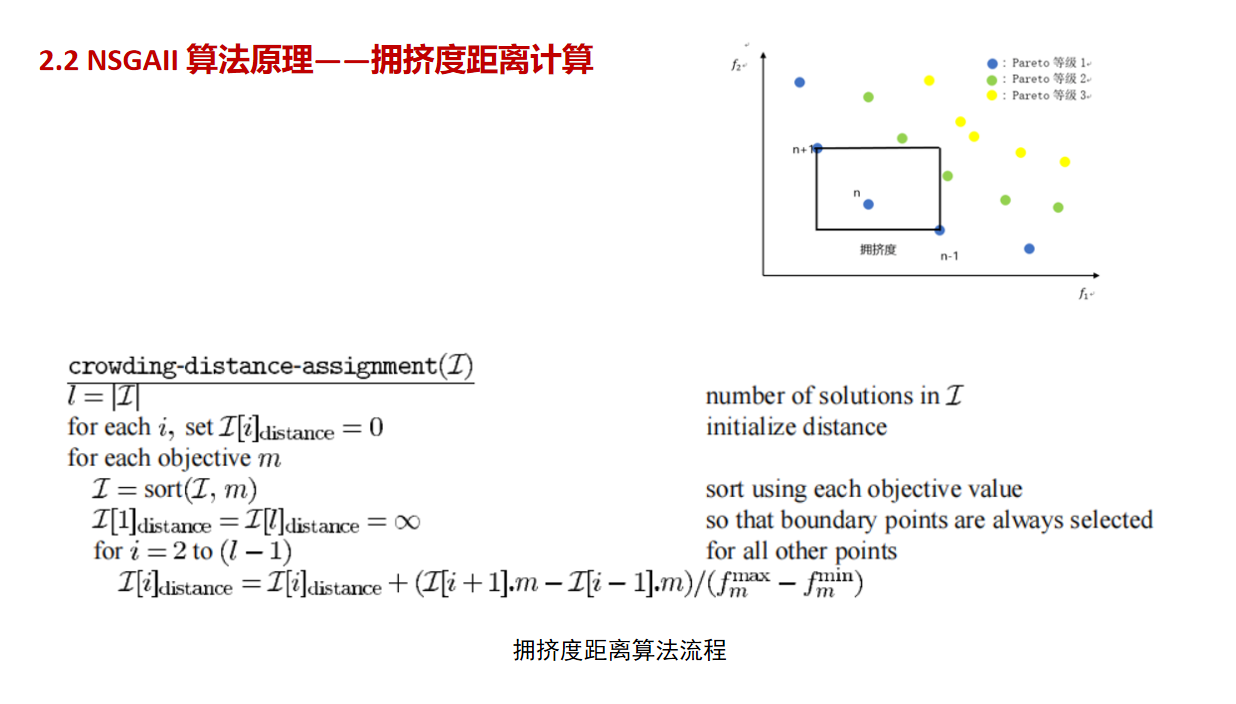
#Function to calculate crowding distance
def crowding_distance(values1, values2, front):
distance = [0 for i in range(0,len(front))]
sorted1 = sort_by_values(front, values1[:])
sorted2 = sort_by_values(front, values2[:])
distance[0] = 4444444444444444
distance[len(front) - 1] = 4444444444444444
for k in range(1,len(front)-1):
distance[k] = distance[k]+ (values1[sorted1[k+1]] - values2[sorted1[k-1]])/(max(values1)-min(values1))
for k in range(1,len(front)-1):
distance[k] = distance[k]+ (values1[sorted2[k+1]] - values2[sorted2[k-1]])/(max(values2)-min(values2))
return distance
#Function to carry out the crossover
def crossover(a,b):
r=random.random()
if r>0.5:
return mutation((a+b)/2) else: return mutation((a-b)/2) #Function to carry out the mutation operator def mutation(solution): mutation_prob = random.random() if mutation_prob <1: solution = min_x+(max_x-min_x)*random.random() return solution #Main program starts here pop_size = 20 max_gen = 921 #Initialization min_x=-55 max_x=55 # 随机生成初始种群 solution=[min_x+(max_x-min_x)*random.random() for i in range(0,pop_size)] gen_no=0 while(gen_no<max_gen): # 自适应度计算 function1_values = [function1(solution[i])for i in range(0,pop_size)] function2_values = [function2(solution[i])for i in range(0,pop_size)] # pareto等级 non_dominated_sorted_solution = fast_non_dominated_sort(function1_values[:],function2_values[:]) print("The best front for Generation number ",gen_no, " is") for valuez in non_dominated_sorted_solution[0]: print(round(solution[valuez],3),end=" ") print("\n") # 拥挤度距离计算 crowding_distance_values = [] for i in range(0,len(non_dominated_sorted_solution)):
crowding_distance_values.append(crowding_distance(function1_values[:],function2_values[:],non_dominated_sorted_solution[i][:]))
solution2 = solution[:] # P+Q
#Generating offsprings
while(len(solution2)!=2*pop_size):
a1 = random.randint(0,pop_size-1)
b1 = random.randint(0,pop_size-1)
# 交叉变异
solution2.append(crossover(solution[a1],solution[b1]))
# 计算 P+Q种群的适应度
function1_values2 = [function1(solution2[i])for i in range(0,2*pop_size)]
function2_values2 = [function2(solution2[i])for i in range(0,2*pop_size)]
# 非支配排序
non_dominated_sorted_solution2 = fast_non_dominated_sort(function1_values2[:],function2_values2[:])
# 拥挤度距离计算
crowding_distance_values2=[]
for i in range(0,len(non_dominated_sorted_solution2)):
crowding_distance_values2.append(crowding_distance(function1_values2[:],function2_values2[:],non_dominated_sorted_solution2[i][:]))
# 得到下一代种群P1
new_solution = [] # index
for i in range(0,len(non_dominated_sorted_solution2)):
non_dominated_sorted_solution2_1 = [index_of(non_dominated_sorted_solution2[i][j],non_dominated_sorted_solution2[i]) for j in range(0,len(non_dominated_sorted_solution2[i]))]
front22 = sort_by_values(non_dominated_sorted_solution2_1[:], crowding_distance_values2[i][:])
front = [non_dominated_sorted_solution2[i][front22[j]] for j in range(0,len(non_dominated_sorted_solution2[i]))]
front.reverse()
for value in front:
new_solution.append(value)
if(len(new_solution)==pop_size):
break
if (len(new_solution) == pop_size):
break
solution = [solution2[i] for i in new_solution]
gen_no = gen_no + 1
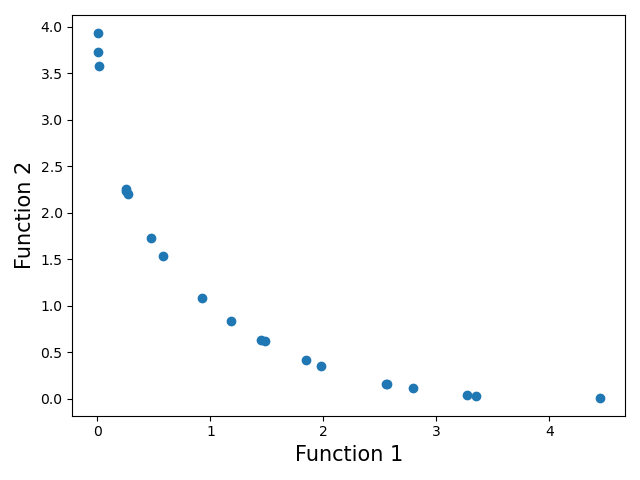
#Lets plot the final front now
function1 = [i * -1 for i in function1_values]
function2 = [j * -1 for j in function2_values]
plt.xlabel('Function 1', fontsize=15)
plt.ylabel('Function 2', fontsize=15)
plt.scatter(function1, function2)
plt.show()

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/144707.html原文链接:https://javaforall.net


