
大家好,又见面了,我是你们的朋友全栈君。
watch -n 0.1 -d nvidia-smi # 检查GPU利用率参数
解决办法:
1. dataloader设置参数
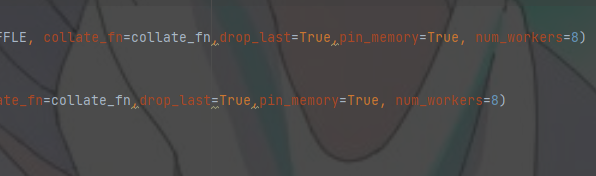

2.增大batchsize
3. 减少IO操作,比如tensorboard的写入和打印。
4. 换显卡
5. 性能分析
import time
import cProfile, pstats, profile
def add(x, y):
time.sleep(1)
value = x + y
return value
def sub(x, y):
time.sleep(1.5)
value = x - y
return value
class TestProfile:
def calc(self, x, y):
time.sleep(1)
add_result = add(x, y)
sub_result = sub(x, y)
print(f"{x} add {y} result is: {add_result}")
print(f"{x} sub {y} result is: {sub_result}")
if __name__ == '__main__':
obj = TestProfile()
# 要分析的函数。
# 原来调用该怎么写就写成相应的字符串形式就好了
be_analysed_function = "obj.calc(1,2)"
# 给此次监测命个名,随意起。
analysed_tag_name = "test_analysed"
# 使用c语言版的profile进行分析,好处是自身占用资源更少,对函数的耗时定位更准确
cProfile.run(be_analysed_function, analysed_tag_name)
# 使用python版的profile进行分析,格式都一样的。
# profile.run(be_analysed_function, analysed_tag_name)
# 对此次监测进行分析。
s = pstats.Stats(analysed_tag_name)
# 移除文件目录,减少打印输出
# s.strip_dirs()
# 排序。
# "time"表示按函数总耗时排序,python3.7后可用枚举变量pstat.SortKey来取排序项
s.sort_stats("time")
# 打印统计结果
# ncalls--函数被调用的次数
# tottime--此函数在所有调用中共耗费的时间秒数(不包括其调用的子函数耗费的时间)。分析耗时主要看这个。
# percall--此函数平均每次被调用耗时。分析耗时次要看这个
# cumtime--执行此函数及其调用子函数所占用的时间。
# percall--此函数平均每次调用每个子函数所用的时间。
s.print_stats()
# print_stats的结果并不显示谁调用的谁,比如是A调用的C还是B调用的C是不清楚的
# 要打印出函数的调用者,可使用print_callers()
# 结果中右边是被调用函数,左边是调用该函数的函数
# s.print_callers()https://blog.csdn.net/DD_PP_JJ/article/details/111829869
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/147477.html原文链接:https://javaforall.net

![JS 获取当前年份,月份[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
