
大家好,又见面了,我是你们的朋友全栈君。
摘要:
URLDecoder 和 URLEncoder 用于完成普通字符串 和 application/x-www-form-urlencoded MIME 字符串之间的相互转换。在本文中,我们以使用URLDecoder解决GET请求中文乱码问题为场景说明 URLDecoder/URLEncoder 的用法,并给出了 application/x-www-form-urlencoded MIME 字符串的编码规则。
一. URLDecoder/URLEncoder 使用场景概述
URLDecoder 和 URLEncoder 用于完成普通字符串 和 application/x-www-form-urlencoded MIME 字符串之间的相互转换。在介绍 application/x-www-form-urlencoded MIME 字符串之前,我们先考虑如下场景,如下图所示:


我们知道,在我们向客户端发起请求时,浏览器会根据请求URL生成相应的请求报文发送给服务器。在这个过程中,如果我们在浏览器中的地址栏中所输入的URL包含中文字符时,浏览器首先会将这些中文字符进行编码然后再发送给服务器。实际上,浏览器会将它们转换为 application/x-www-form-urlencoded MIME 字符串,如下图所示:
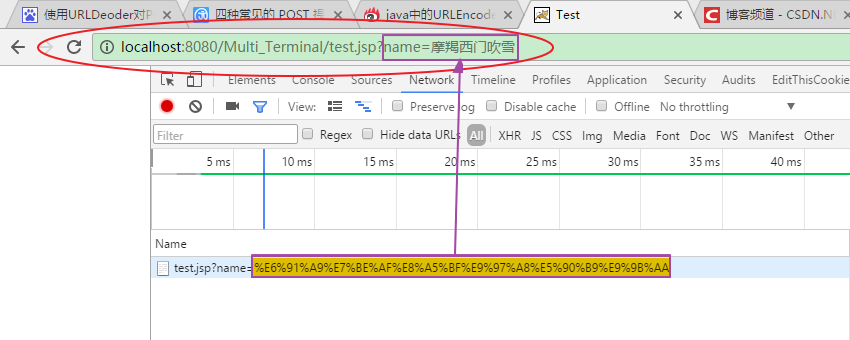
更确切的,当URL地址里包含非西欧字符的字符串时,浏览器都会将这些非西欧字符串转换成application/x-www-form-urlencoded MIME 字符串。在开发过程中,我们可能涉及将普通字符串和这种特殊字符串的相关转换,这就需要使用 URLDecoder 和 URLEncoder类进行实现,其中:
-
URLDecoder类包含一个decode(String s,String enc)静态方法,它可以将application/x-www-form-urlencoded MIME字符串转成普通字符串;
-
URLEncoder类包含一个encode(String s,String enc)静态方法,它可以将普通字符串转换成application/x-www-form-urlencoded MIME字符串。
下面程序示范了普通字符串转与 application/x-www-form-urlencoded MIME 字符串之间的转化。
public class URLDecoderTest {
public static void main(String[] args) throws Exception {
// 将application/x-www-form-urlencoded字符串转换成普通字符串
// 其中的字符串直接从上图所示窗口复制过来,chrome 默认用 UTF-8 字符集进行编码,所以也应该用对应的字符集解码
System.out.println("采用UTF-8字符集进行解码:");
String keyWord = URLDecoder.decode("%E5%A4%A9%E6%B4%A5%E5%A4%A7%E5%AD%A6+Rico", "UTF-8");
System.out.println(keyWord);
System.out.println("\n 采用GBK字符集进行解码:");
System.out.println(URLDecoder.decode("%E5%A4%A9%E6%B4%A5%E5%A4%A7%E5%AD%A6+Rico", "GBK"));
// 将普通字符串转换成application/x-www-form-urlencoded字符串
System.out.println("\n 采用utf-8字符集:");
String urlStr = URLEncoder.encode("天津大学", "utf-8");
System.out.println(urlStr);
System.out.println("\n 采用GBK字符集:");
String urlStr2 = URLEncoder.encode("天津大学", "GBK");
System.out.println(urlStr2);
}
}/* Output: 采用UTF-8字符集进行解码: 天津大学 Rico 采用GBK字符集进行解码: 澶╂触澶у Rico 采用utf-8字符集: %E5%A4%A9%E6%B4%A5%E5%A4%A7%E5%AD%A6 采用GBK字符集: %CC%EC%BD%F2%B4%F3%D1%A7 *///:~特别地,仅包含西欧字符的普通字符串和application/x-www-form-urlencoded MIME字符串无须转换,而包含中文字符的普通字符串则需要转换,转换的方法是每个中文字符占2个字节,每个字节可以转换成2个十六进制的数字,所以每个中文字符将转换成“%XX%XX”的形式。当然,采用不同的字符集时,每个中文字符对应的字节数并不完全相同,所以使用URLEncoder和URLDecoder进行转换时也需要指定字符集。特别地,字符串应以同样的字符集进行编码和解码,否则会产生意想不到的结果,如上述程序示例所示。
二. 解决GET请求中文乱码问题
URLDecoder的一个应用场景就是解决GET请求的中文乱码问题,如下述代码所示:
<%@page import="java.net.URLDecoder"%>
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%>
<html>
<head>
<title>Test</title>
</head>
<body>
<% String param1 = request.getQueryString(); String param2 = URLDecoder.decode(param1, "utf-8"); out.print(param2.split("=")[1] + "<br>"); %>
</body>
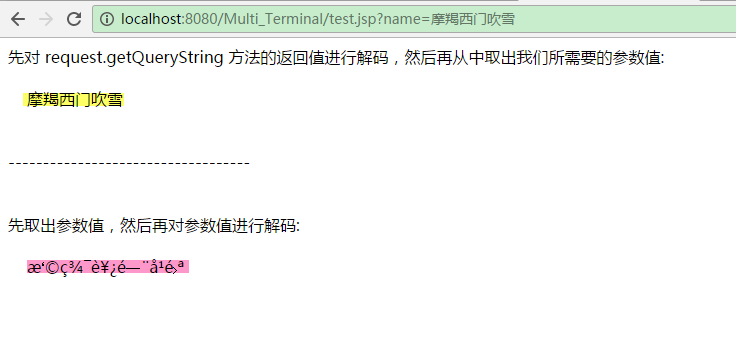
</html>特别需要注意的是,使用此方式对GET请求参数进行解码时,我们必须先对 request.getQueryString 方法的返回值(例如,“name=摩羯西门吹雪”)进行解码,然后再从中取出我们所需要的参数值。如果先取出参数值,然后再对参数值进行解码,则我们将得到乱码,如下图所示:
此外,对于包含中文字符的POST请求参数,我们只需在获取请求参数前通过以下代码语句进行转码即可:
request.setCharacterEncoding("utf-8");三. URLEncoder & URLDecoder
对 String 编码时,使用以下规则:
- 字母、数字和字符, “a” 到 “z”、”A” 到 “Z” 和 “0” 到 “9” 保持不变;
- 特殊字符 “.”、”-“、”*” 和 “_” 保持不变;
- 空格字符 ” ” 转换为一个加号 “+”。
除此之外,所有的其他字符都是不安全的。因此需要使用一些编码机制将它们转换为一个或多个字节,每个字节用一个包含 3 个字符的字符串 “%xy” 表示,其中 xy 为该字节的两位十六进制表示形式,推荐的编码机制是 UTF-8。例如,使用 UTF-8 编码机制,字符串 “The string ü@foo-bar” 将转换为 “The+string+%C3%BC%40foo-bar”,因为在 UTF-8 中,字符 ü 编码为两个字节,C3 (十六进制)和 BC (十六进制),字符 @ 编码为一个字节 40 (十六进制)。
关于 URLDecoder 类的使用,转换过程正好与 URLEncoder 类使用的过程相反,此不赘述。
关于JSP中文乱码更多的介绍,包括 页面乱码、参数乱码、表单乱码、源文件乱码 等知识,见我的另外两篇博客:《JSP中文乱码问题终极解决方案(上)》 和 《JSP中文乱码问题终极解决方案(下)》。
引用
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/150123.html原文链接:https://javaforall.net


