
大家好,又见面了,我是你们的朋友全栈君。 刚才终于完完全全、彻彻底底的搞明白了稀疏矩阵十字链表的存储方式的实现与该算法的思想。我觉得有必要把自己的思路记下来,一呢等自己将来忘记了可以回过头来看,二呢希望与我一样对该存储方式迷惑的朋友可以通过我的文章得到一点点的启示。现在进入正题。
我们知道稀疏矩阵的三元组存储方式的实现很简单,每个元素有三个域分别是i, j, e。代表了该非零元的行号、列号以及值。那么在十字链表的存储方式下,首先这三个域是肯定少不了的,不然在进行很多操作的时候都要自己使用计数器,很麻烦。而十字链表的形式大家可以理解成每一行是一个链表,而每一列又是一个链表。如图所示:
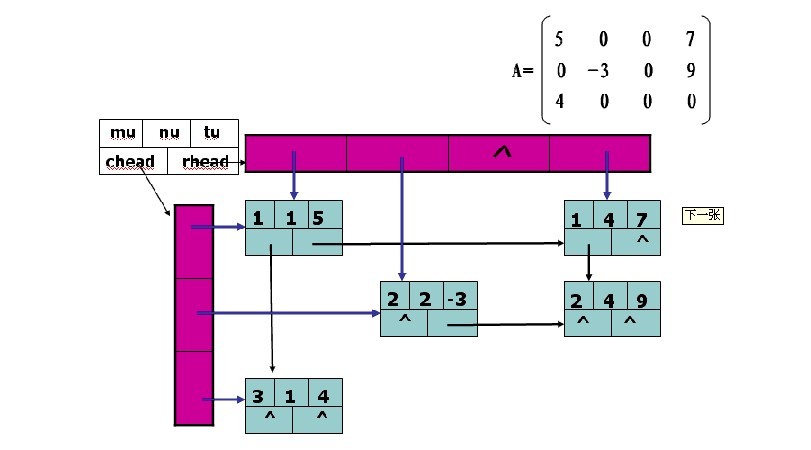

通过上面的图我们可以知道,每个结点不止要存放i, j, e。还要存放它横向的下一个结点的地址以及纵向的下一个结点的地址。形成一个类似十字形的链表的结构。那么每个结点的结构体定义也就呼之欲出了
typedef struct OLNode {
int i, j; //行号与列号
ElemType e; //值
struct OLNode *right, *down; //指针域
}OLNode, *OList;
这样我们对结点的插入与删除就要修改两个指针域。为了方便我们对结点的操作,我们要创建头指针或者头结点。至于到底是选择头指针呢还是头结点,请继续看下去..
我们想下要怎么创建头指针或者头结点,我们可以创建OLNode结构的结点形成一段连续的地址空间来指向某一行或者某一列中的结点(这是我最初的想法)
或者我们创建指针数组,数组元素中存放的地址就是某一行或者某一列的第一个结点的地址。来分析下两种方法
第一种方法会浪费大量的空间,而因为指针变量的空间都是4个字节,所以相对来说第二种节省空间。
毫无疑问我们选择第二种,也就是创建头指针。那么第二种我们用什么来实现?是数组还是动态内存分配?如果用数组我们要预先定义行和列的最大值,显然这不是一个好主意,而动态内存分配的方法我们可以在用户输入了行数与列数之后分配相应的一段地址连续的空间。更为灵活,所以我们选择动态内存分配。
typedef struct {
OLink *Rhead, *Chead;
int mu, nu, tu; // 稀疏矩阵的行数、列数和非零元个数
}CrossList;
注意Rhead与Chead的类型,它们是指向指针的指针,也就是说,它们是指向我们定义的OLNode结构的结点的指针的指针。这话有点绕,不过相信C学的不错的朋友都应该清楚。如果不清楚的请看这个帖子 http://topic.csdn.net/u/20110829/01/506b33e3-ebc9-4905-bf8d-d0c877f85c08.html
现在结构体已经定义好了,我们来想想下面应该干什么。首先需要用户输入稀疏矩阵的行数与列数以及非零元的个数。那么就需要定义一个CrossList的结构体变量来存储这些值。
int main(void)
{
CrossList M;
CreateSMatrix(&M);
} CreatSMatrix函数是我们今天要创建的函数,它用来建立稀疏矩阵并使用十字链表的方式存储矩阵。该函数的原型为int CreateSMatrix(CrossList *M);
当我们创建好了M就需要用户输入了,那么就要对用户的输入进行检查,看是否符合要求,首先mu, nu, tu都不能小于0,并且mu, nu不能等于0(我们这里假设行号与列号都是从1开始的,所以不能等于0),tu的值必须在0与mu * nu之间。
int CreateSMatrix(CrossList *M)
{
int i, j, m, n, t;
int k, flag;
ElemType e;
OLNode *p, *q;
if (M->Rhead)
DestroySMatrix(M);
do {
flag = 1;
printf("输入需要创建的矩阵的行数、列数以及非零元的个数");
scanf("%d%d%d", &m, &n, &t);
if (m<0 || n<0 || t<0 || t>m*n)
flag = 0;
}while (!flag);
M->mu = m;
M->nu = n;
M->tu = t;
...................................
return 1;
}
当用户输入了正确的值以后,我们要创建头指针的数组
//创建行链表头数组
M->Rhead = (OLink *)malloc((m+1) * sizeof(OLink));
if(!M->Rhead)
exit(-1);
//创建列链表头数组
M->Chead = (OLink *)malloc((n+1) * sizeof(OLink));
if(!(M->Chead))
exit(-1);
这里m+1与n+1是为了后面操作的方便使得它们的下标从1开始。注意我们创建时候的强制转换的类型。OLink * , 首先它是指针类型。我们连续创建了m+1个,每一个都指向OLink类型的变量,所以它里面存放的就应该是一个指向OLNode类型的指针的地址。
创建完以后必须初始化,因为我们后面的插入就其中一个判断条件就是它们的值为NULL,也就是该行或者该列中没有结点
for(k=1;k<=m;k++) // 初始化行头指针向量;各行链表为空链表
M->Rhead[k]=NULL;
for(k=1;k<=n;k++) // 初始化列头指针向量;各列链表为空链表
M->Chead[k]=NULL;现在我们就可以进行结点的输入了,显而易见的要输入的结点个数刚才已经存放到了t变量中,那么我们要创建t个结点。这就是一个大的循环
而每创建一个结点我们都要修改它的两个指针域以及链表头数组。那么我们可以分开两次来修改,第一次修改行的指针域,第二次修改列的指针域。
do {
flag = 1;
printf("输入第%d个结点行号、列号以及值", k);
scanf("%d%d%d", &i, &j, &e);
if (i<=0 || j<=0)
flag = 0;
}while (!flag);
p = (OLink) malloc (sizeof(OLNode));
if (NULL == p)
exit(-1);
p->i = i;
p->j = j;
p->e = e;
当用户输入一系列正确的值,并且我们也创建了一个OLNode类型的结点之后我们要讲它插入到某一行中。首先要确定插入在哪一行?我们输入的时候已经输入了行号i,那么我们自然要插入到i行中,那么应该怎样去插入?分两种情况
1、当这一行中没有结点的时候,那么我们直接插入
2、当这一行中有结点的时候我们插入到正确的位置
逐个来分析:
怎么判定一行中有没有结点? 记得我们前面对Rhead的初始化吗? 所有的元素的值都为NULL,所以我们的判断条件就是 NULL==M->Rhead[i].
现在我们来解决第二个问题。
怎么去找到要插入的正确位置。当行中有结点的时候我们无非就是插入到某个结点之前或者之后。那么我们再回到前面,在我们定义Rhead的时候就说过,某一行的表头指针指向的就是该行中第一个结点的地址。我们假设该行中已经有了一个结点我们称它为A结点,如果要插在A结点之前那么A结点的列号必定是大于我们输入的结点(我们称它为P结点)的列号的。我们的插入操作就要修改头指针与p结点的right域。就像链表中的插入。那么当该行中没有结点的时候我们怎么去插入?同样是修改头指针让它指向我们的P结点,同样要修改P结点的right域。看,我们可以利用if语句来实现这两种条件的判断。那么就有了下面的代码!
if(NULL==M->Rhead[i] || M->Rhead[i]->j>j)
{
// p插在该行的第一个结点处
// M->Rhead[i]始终指向该行的第一个结点 p->right = M->Rhead[i];
M->Rhead[i] = p;
}
现在我们再想一下怎么去插入到某一个结点的后面? 我们新创建的P结点要插入到现有的A结点的后面,那么P的列号必定是大于A的列号,那么我们只要找到第一个大于比P的列号大的结点B,然后插入到B结点之前!如果现有的结点没有一个结点列号是大于P结点的列号的,那么我们就应该插入到最后一个结点之后!所以我们首先要寻找符合条件的位置进行插入
for(q=M->Rhead[i]; q->right && q->right->j < j; q=q->right)
;
p->right=q->right; // 完成行插入
q->right=p;
这样就插入完成了,至于列的指针域的修改和这个类似!现在贴出所有代码
int CreateSMatrix(CrossList *M)
{
int i, j, m, n, t;
int k, flag;
ElemType e;
OLNode *p, *q;
if (M->Rhead)
DestroySMatrix(M); do {
flag = 1;
printf("输入需要创建的矩阵的行数、列数以及非零元的个数");
scanf("%d%d%d", &m, &n, &t);
if (m<0 || n<0 || t<0 || t>m*n)
flag = 0;
}while (!flag);
M->mu = m;
M->nu = n;
M->tu = t;
//创建行链表头数组
M->Rhead = (OLink *)malloc((m+1) * sizeof(OLink));
if(!M->Rhead)
exit(-1);
//创建列链表头数组
M->Chead = (OLink *)malloc((n+1) * sizeof(OLink));
if(!(M->Chead))
exit(-1);
for(k=1;k<=m;k++) // 初始化行头指针向量;各行链表为空链表
M->Rhead[k]=NULL;
for(k=1;k<=n;k++) // 初始化列头指针向量;各列链表为空链表
M->Chead[k]=NULL;
//输入各个结点
for (k=1; k<=t; ++k)
{
do {
flag = 1;
printf("输入第%d个结点行号、列号以及值", k);
scanf("%d%d%d", &i, &j, &e);
if (i<=0 || j<=0)
flag = 0;
}while (!flag); p = (OLink) malloc (sizeof(OLNode));
if (NULL == p)
exit(-1);
p->i = i;
p->j = j;
p->e = e;
if(NULL==M->Rhead[i] || M->Rhead[i]->j>j)
{
// p插在该行的第一个结点处
// M->Rhead[i]始终指向它的下一个结点
p->right = M->Rhead[i];
M->Rhead[i] = p;
}
else // 寻查在行表中的插入位置
{
//从该行的行链表头开始,直到找到
for(q=M->Rhead[i]; q->right && q->right->j < j; q=q->right)
;
p->right=q->right; // 完成行插入
q->right=p;
} if(NULL==M->Chead[j] || M->Chead[j]->i>i)
{
p->down = M->Chead[j];
M->Chead[j] = p;
}
else // 寻查在列表中的插入位置
{
//从该列的列链表头开始,直到找到
for(q=M->Chead[j]; q->down && q->down->i < i; q=q->down)
;
p->down=q->down; // 完成行插入
q->down=p;
}
} return 1;
}
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/150308.html原文链接:https://javaforall.net


