
大家好,又见面了,我是你们的朋友全栈君。
一、前言
在以前的博客中小编介绍过mysql的执行流程,索引优化等。正好前一段时间项目有一个新的需求,就重新调研了一下mysql的全文索引,并对mysql的全文索引进行了压测,看看性能怎么样。以判断是否使用。——可想而知,性能不是很好。 下面小编就向大家再说说mysql的全文检索。
更多请看:
二、什么是全文检索
全文索引
在前面的几篇博客中,小编提到过,mysql中常用的表的引擎有MyIsam 和 Innodb, 其中,默认存储引擎InnoDB,MYSQL5.6以前是不支持全文索引,新版本MYSQL5.6的InnoDB支持全文索引。MyIsam是支持索引的,但是不支持事务。只有字段的数据类型为 char、varchar、text 及其系列才可以建全文索引。
随着Mysql的升级,我们使用众多的还是Innodb。
要说清楚全文索引,可以举一个例子,比如现在有一个字段,内容是 德玛西亚万岁,这个时候有以下的需求:
1.查询带有 德玛 的内容
2.查询带有 万岁 的内容
3.查询带有 德玛西亚 的内容
按照我们大体的思路来,我们会使用 select * from table where content like '%XXXX%'来查询。使用like的缺点是,如果不是前缀索引,索引会失效。所以如果根据不同的内容来查的时候,自然很难命中索引。这样全文检索就登场。
mysql会自动为我们切词,从MySQL 5.7.6开始,MySQL内置了ngram全文解析器,用来支持中文、日文、韩文分词。性能怎么样呢?我们在后面进行测试。
ngram全文解析器
ngram就是一段文字里面连续的n个字的序列。ngram全文解析器能够对文本进行分词,每个单词是连续的n个字的序列。例如,用ngram全文解析器对“生日快乐”进行分词:
n=1: '生', '日', '快', '乐'
n=2: '生日', '日快', '快乐'
n=3: '生日快', '日快乐'
n=4: '生日快乐'
MySQL 中使用全局变量ngram_token_size来配置ngram中n的大小,它的取值范围是1到10,默认值是2。通常ngram_token_size设置为要查询的单词的最小字数。如果需要搜索单字,就要把ngram_token_size设置为1。在默认值是2的情况下,搜索单字是得不到任何结果的。因为中文单词最少是两个汉字,推荐使用默认值2。
全局变量ngram_token_size的两种设置方法:
1、启动mysqld命令时
mysqld --ngram_token_size=2
2、修改MySQL配置文件
[mysqld]
ngram_token_size=2
创建全文索引
1、创建表的同时创建全文索引
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR (200),
body TEXT,
FULLTEXT (title, body) WITH PARSER ngram
) ENGINE = INNODB;
2、通过 alter table 的方式来添加
ALTER TABLE articles ADD FULLTEXT INDEX ft_index (title,body) WITH PARSER ngram;
3、直接通过create index的方式
CREATE FULLTEXT INDEX ft_index ON articles (title,body) WITH PARSER ngram;
全文检索模式
常用的全文检索模式有两种:
1、自然语言模式(NATURAL LANGUAGE MODE) ,
自然语言模式是MySQL 默认的全文检索模式。自然语言模式不能使用操作符,不能指定关键词必须出现或者必须不能出现等复杂查询。
2、BOOLEAN模式(BOOLEAN MODE)
BOOLEAN模式可以使用操作符,可以支持指定关键词必须出现或者必须不能出现或者关键词的权重高还是低等复杂查询。
示例
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('一路 一带' IN NATURAL LANGUAGE MODE);
// 不指定模式,默认使用自然语言模式
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('一路 一带');
上面的示例返回结果会自动按照相关性排序,相关性高的在前面。相关性的值是一个非负浮点数,0表示无相关性。
// 获取相关性的值
SELECT id,title,
MATCH (title,body) AGAINST ('手机' IN NATURAL LANGUAGE MODE) AS score
FROM articles
ORDER BY score DESC;


// 获取匹配结果记录数
SELECT COUNT(*) FROM articles
WHERE MATCH (title,body)
AGAINST ('一路 一带' IN NATURAL LANGUAGE MODE);
可以使用BOOLEAN模式执行高级查询。
// 必须包含"腾讯"
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('+腾讯' IN BOOLEAN MODE);
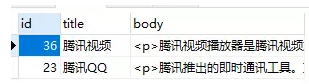
// 必须包含"腾讯",但是不能包含"通讯工具"
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('+腾讯 -通讯工具' IN BOOLEAN MODE);

下面的例子演示了BOOLEAN模式下运算符的使用方式:
'apple banana'
无操作符,表示或,要么包含apple,要么包含banana
'+apple +juice'
必须同时包含两个词
'+apple macintosh'
必须包含apple,但是如果也包含macintosh的话,相关性会更高。
'+apple -macintosh'
必须包含apple,同时不能包含macintosh。
'+apple ~macintosh'
必须包含apple,但是如果也包含macintosh的话,相关性要比不包含macintosh的记录低。
'+apple +(>juice <pie)'
查询必须包含apple和juice或者apple和pie的记录,但是apple juice的相关性要比apple pie高。
'apple*'
查询包含以apple开头的单词的记录,如apple、apples、applet。
'"some words"'
使用双引号把要搜素的词括起来,效果类似于like '%some words%',
例如“some words of wisdom”会被匹配到,而“some noise words”就不会被匹配。
注意
-
只能在类型为CHAR、VARCHAR或者TEXT的字段上创建全文索引。
-
全文索引只支持InnoDB和MyISAM引擎。
-
MATCH (columnName) AGAINST (‘keywords’)。MATCH()函数使用的字段名,必须要与创建全文索引时指定的字段名一致。如上面的示例,MATCH (title,body)使用的字段名与全文索引ft_articles(title,body)定义的字段名一致。如果要对title或者body字段分别进行查询,就需要在title和body字段上分别创建新的全文索引。
-
MATCH()函数使用的字段名只能是同一个表的字段,因为全文索引不能够跨多个表进行检索。
-
如果要导入大数据集,使用先导入数据再在表上创建全文索引的方式要比先在表上创建全文索引再导入数据的方式快很多,所以全文索引是很影响TPS的。
三、压测
mysql全文索引查询 直接查询
单表50w数据, 查三个字段 title subtitle body
5个并发
服务器
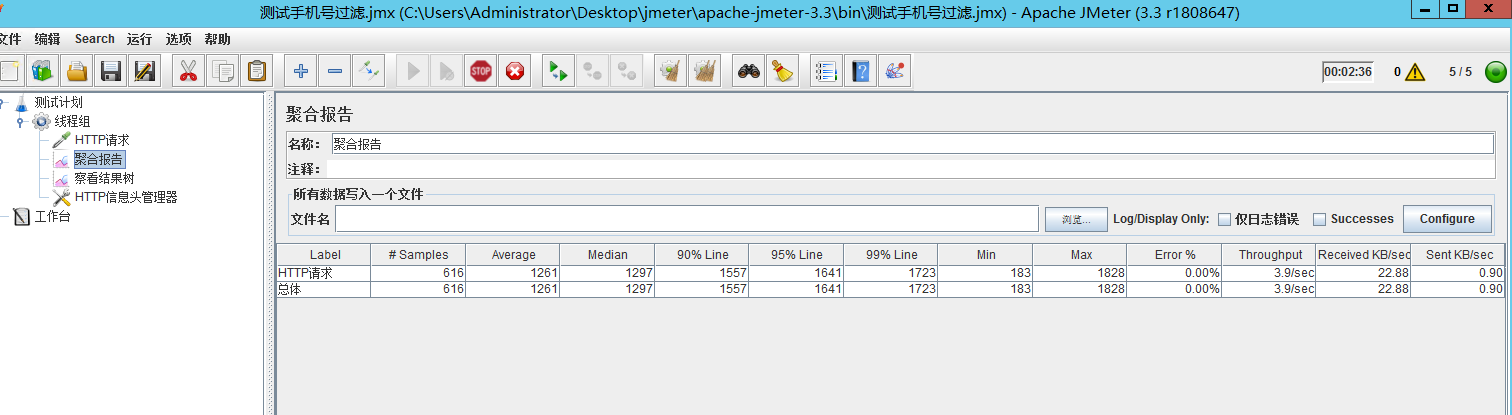
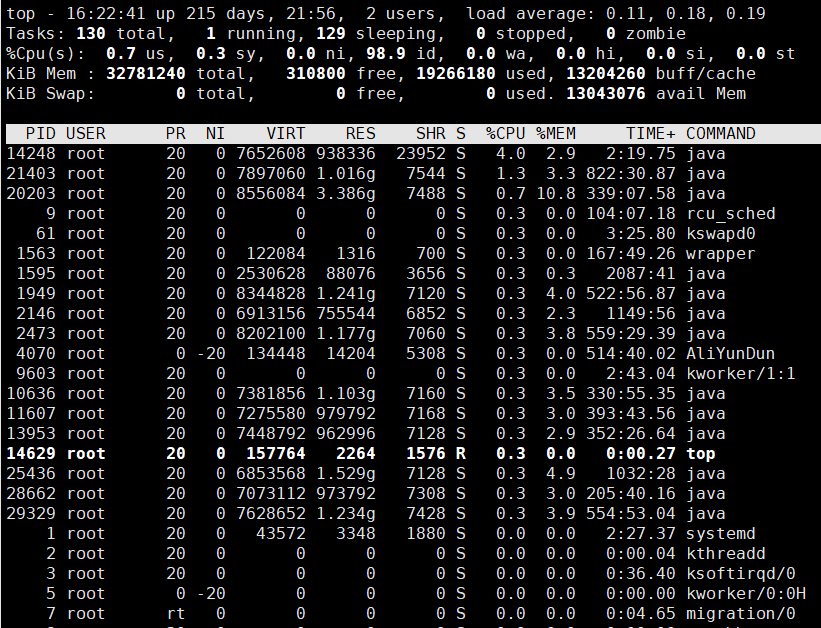
Rds
cpu一直飙升
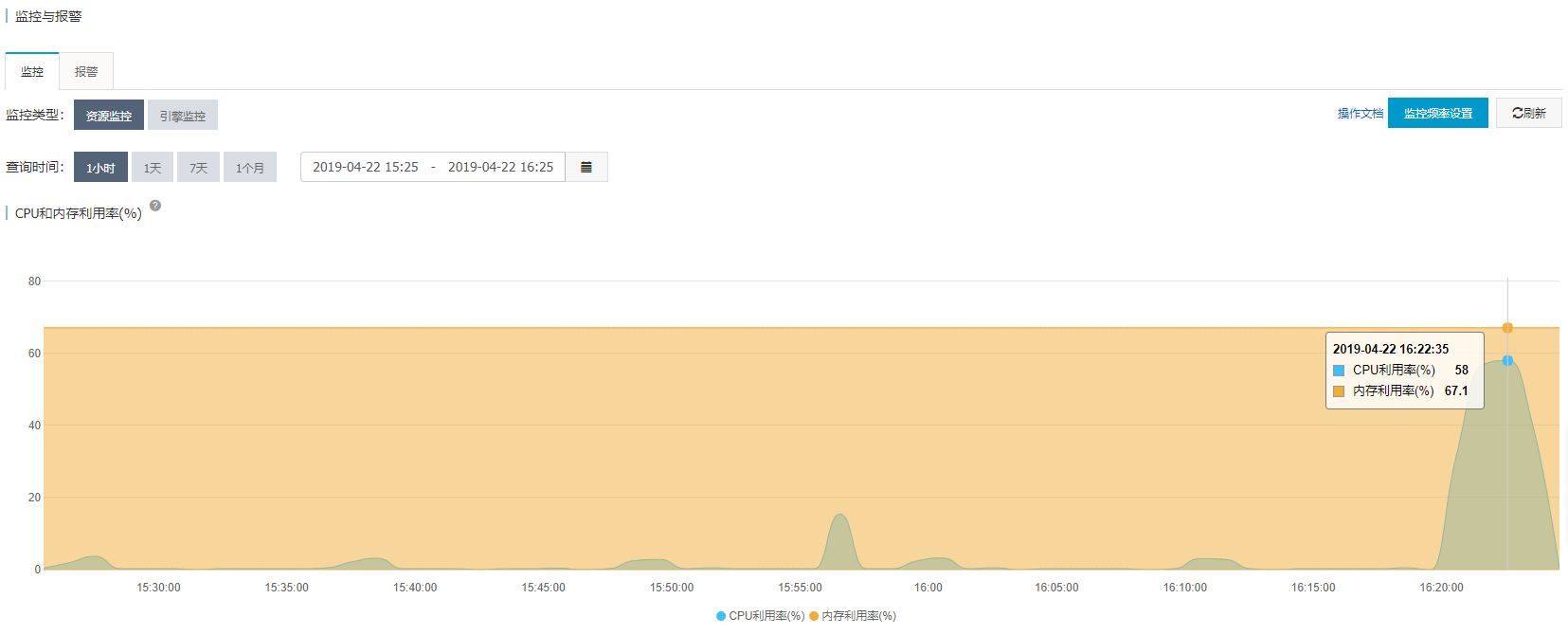
四、小结
mysql全文索引查询 ,虽然mysql在innodb上支持了全文索引,但是还是不推荐 ,并发高的时候 Rds 的cpu会爆掉。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/151900.html原文链接:https://javaforall.net


