
大家好,又见面了,我是你们的朋友全栈君。
什么是莫兰指数?
根据百度百科的定义是“空间自相关系数的一种,其值分布在[-1,1],用于判别空间是否存在自相关。”
简单的说就是判定一定范围内的空间实体相互之间是否存在相关关系,比如:一座座居民楼它们是聚集在一块还是离散分布在各处。
莫兰指数数值分布在[-1,1],[0,1]说明各地理实体之间存在正相关的关系,[-1,0]之间说明存在负相关的关系,而0值则无相关关系。
- 因为位置的确定是相对的,相对于基点而言。如:高程的确定需要黄海基准,地理位置的确定需要西安80坐标系。
- 一簇数据点的空间的分布是聚集还是离散也是相对的,是相对于更大空间范围而定的。如:霍乱病例的发病地点数据,它的空间分布,是聚集还是离散,是相对于更大尺度的空间范围而言,相对于街区它是离散的,相对于城市它是集聚的。
- 空间自相关的分析方法是通过假设检验进行的,对于霍乱病例数据,它首先假设病例的分布符合某种分布关系,比如:离散或聚集,这种进行统计检验时预先建立的假设,称为零假设或原假设。零假设成立时,有关统计量应服从已知的某种概率分布。
- 空间自相关工具同时根据要素位置和要素值来度量空间自相关。在给定一组要素及相关属性的情况下,该工具评估所表达的模式是聚类模式、离散模式还是随机模式。该工具通过计算 Moran’s I 指数值、z 得分和 p 值来对该指数的显著性进行评估。p 值是根据已知分布的曲线得出的面积近似值(受检验统计量限制)。
在理解莫兰指数之前需要一些先验知识的支撑:
假设检验/统计检验:统计检验亦称“假设检验”。根据抽样结果,在一定可靠性程度上对一个或多个总体分布的原假设作出拒绝还是不拒绝(予以接受)结论的程序。决定常取决于样本统计量的数值与所假设的总体参数是否有显著差异。这时称差异显著性检验。检验的推理逻辑为具有概率性质的反证法。例如,在参数假设检验中,当对总体分布的参数作出原假设 H0 后,先承认总体与原假设相同,然后根据样本计算一个统计量,并求出该统计量的分布,再给定一个小概率(一般为 0.05,0.01 等,视情况而定),确定拒绝原假设 H0 的区域(拒绝域)。
零假设:统计学术语,又称原假设,指进行统计检验时预先建立的假设。 零假设成立时,有关统计量应服从已知的某种概率分布。
计算公式:

以下通过一个详细的实验具体说明。
实验
实验目的
通过Arcgis空间自相关工具分析旧金山区域犯罪与地区位置的关系,从而熟悉空间自相关工具的使用和莫兰I指数的判读。
数据准备
- 旧金山区域行政区划数据
- 区域破坏、抢劫、毒品、偷车犯罪点数据
部分数据展示(来源于Center for Spatial Data Science):
图1 旧金山行政区划数据
图2 毒品犯罪矢量数据
实验步骤
基于空间位置与另一图层作连接,计算各区域面内犯罪数量,结果如下:
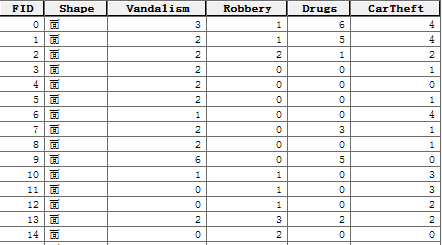
图3 区域面犯罪数量统计
2、生成空间权重矩阵
参数设置:空间关系的概念化选择INVERSE_DISTANCE(一个要素对另一个要素的影响随着距离的增加而减少),距离法选择MANHATTAN(计算每个要素与邻近要素之间的距离的方式为城市街区计算类型)。
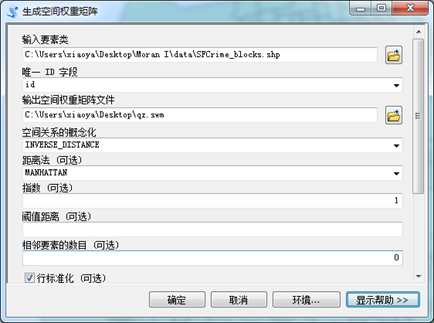
图4 权重矩阵设置
空间关系的概念化:
空间统计分析和传统(非空间)统计分析的一个重要区别是空间统计分析将空间和空间关系直接整合到算法中。因此,空间统计工具箱中的很多工具都要求用户在执行分析之前为空间关系的概念化表述参数选择一个值。
常见的概念化包括:
反距离/反距离平方、距离范围、无差别的区域、面邻接、K最近领域、Delaunay三角测量
空间关系的概念化参数选择:
对要素在空间中彼此交互方式构建的模型越逼真,结果就越准确。空间关系的概念化参数的选择应反映要分析的要素之间的固有关系。考虑到所用数据为犯罪数据,目的为分析旧金山区域犯罪与地区位置的关系,因而选择反距离空间关系的概念化方法能更好的达到分析目的。
“反距离的平方”与“反距离”两者的概念是一样的,只是“反距离的平方”的曲线的坡度更陡,相邻要素之间的影响下降得更快,并且只有目标要素的最近相邻要素会对要素的计算产生重大影响。
对于反距离幂的影响,幂越大,距离近的点的作用越大,插值的结果越陡峭;幂越小,距离的间隔作用越小,插值的结果越平滑;常规上幂值不应该太大。
距离法:
指定计算每个要素与邻近要素之间的距离的方式。分为两种:
EUCLIDEAN —两点间的直线距离
MANHATTAN —沿垂直轴度量的两点间的距离(城市街区);计算方法是对两点的 x 和 y 坐标的差值(绝对值)求和。
指数:
选择幂值。
阈值距离:
为空间关系的反距离和固定距离概念化指定中断距离。使用在环境输出坐标系中指定的单位输入此值。为空间关系的空间时间窗概念化定义空间窗的大小。零值表示未应用任何距离阈值。此参数留空时,将根据输出要素类范围和要素数目计算默认阈值。
相邻要素的数目:
用于表示相邻要素最小数目或精确数目的整数。
对于 K_NEAREST_NEIGHBORS,每个要素的相邻要素数目正好等于这个指定数目。对于 INVERSE_DISTANCE 或 FIXED_DISTANCE,每个要素将至少具有这些数目的相邻要素(如有必要,距离阈值将临时增大以确保达到这个相邻要素数目)。选中一个邻接空间关系的概念化后,将向每个面分配至少该最小数目的相邻要素。对于具有少于此相邻要素数目的面,将根据要素质心邻近性获得附加相邻要素。
3、通过空间权重矩阵计算莫兰I指数,分析毒品犯罪与空间位置的相关性。
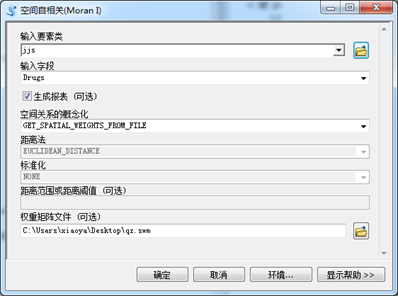
图5 空间自相关工具设置
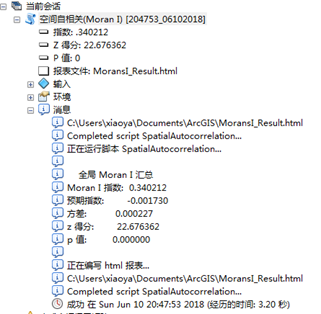
图6 运行结果
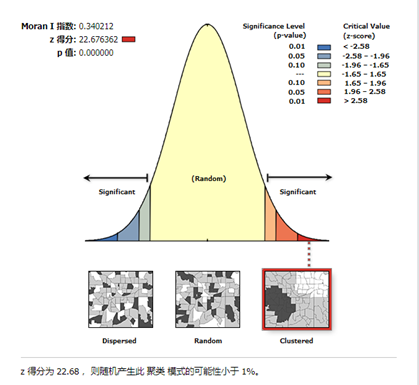
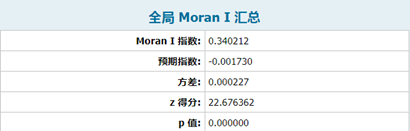
图7 报表文件
4、选择INVERSE_DISTANCE空间关系概念化方法分析区域破坏犯罪与空间位置的相关性。
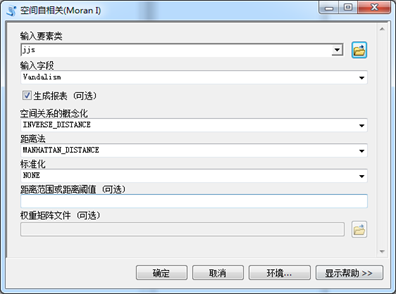
图8 参数设置
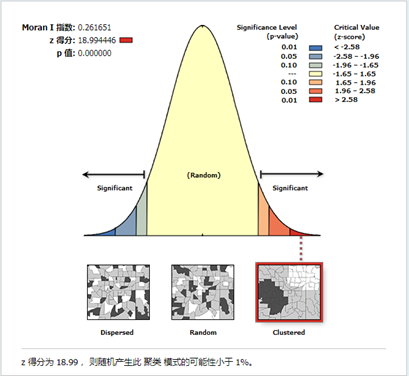
图9 报表文件
5、选择INVERSE_DISTANCE_SQUARED空间关系概念化方法分析抢劫犯罪与空间位置的相关性。

图10 报表文件
6、选择FIXED_DISTANCE_BAND空间关系概念化方法分析偷盗车辆犯罪与空间位置的相关性。
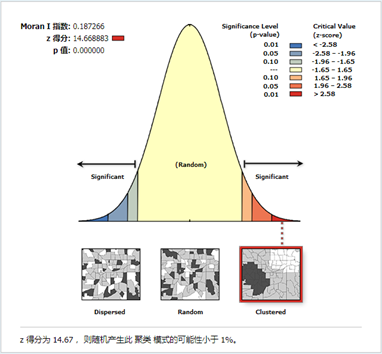
图11 报表文件
结果分析
参数解释
标准差:在概率统计中最常使用作为统计分布程度(statistical dispersion)上的测量。标准差定义是总体各单位标准值与其平均数离差平方的算术平均数的平方根。它反映组内个体间的离散程度。
置信区间:置信区间是指由样本统计量所构造的总体参数的估计区间。在统计学中,一个概率样本的置信区间是对这个样本的某个总体参数的区间估计。置信区间展现的是这个参数的真实值有一定概率落在测量结果的周围的程度。置信区间给出的是被测量参数的测量值的可信程度,即前面所要求的“一个概率”。
- 在置信水平相同的情况下,样本量越多,置信区间越窄。
- 置信区间变窄的速度不像样本量增加的速度那么快。
- 在样本量相同的情况下,置信水平越高,置信区间越宽。
P值:p 值表示概率。对于模式分析工具来说,p 值表示所观测到的空间模式是由某一随机过程创建而成的概率。当 p 很小时,意味着所观测到的空间模式不太可能产生于随机过程(小概率事件),因此您可以拒绝零假设。
Z得分:Z 得分表示标准差的倍数。
莫兰指数:
Moran’s I 值范围在(-1,1)之间。Moran’s I >0表示空间正相关性,其值越大,空间相关性越明显。Moran’s I <0表示空间负相关性,其值越小,空间差异越大,否则,Moran’s I = 0,空间呈随机性。
报表分析
以选择FIXED_DISTANCE_BAND空间关系概念化方法生成的报表为例分析,
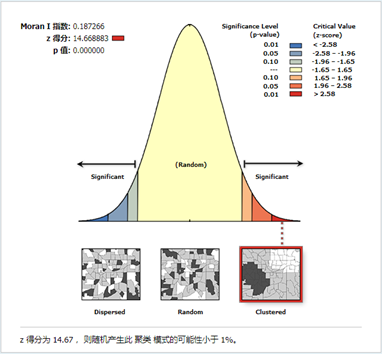
其Moran’I指数为0.18,表明犯罪事件具有强烈的空间相关性、聚集性即某地的犯罪率与该地区的位置有关。Z得分约为15,表明是标准差的15倍,结果分布在正在正态分布的两端,结合Moran’I值为正,可以得出结果分布在正态分布的右端,为聚集型。P值为0,表明该结果百分百不为随机数据生成,结果具有可信度。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/153054.html原文链接:https://javaforall.net


