
大家好,又见面了,我是你们的朋友全栈君。
文章目录
摘要
七夜大佬的《python爬虫开发与项目实战》,买了好多年了,学习了好多东西,基本上爬虫都是在这里面学的,后期的scrapy框架爬虫一直不得门而入,前段时间补了下面向对象的知识,今天突然顿悟了!写个笔记记录下学习过程
1.scrapy安装
# -i参数后跟清华镜像源,加速下载,其他pip的包也可这么操作
pip install Scrapy -ihttps://pypi.tuna.tsinghua.edu.cn/simple
测试如下图表示安装成功
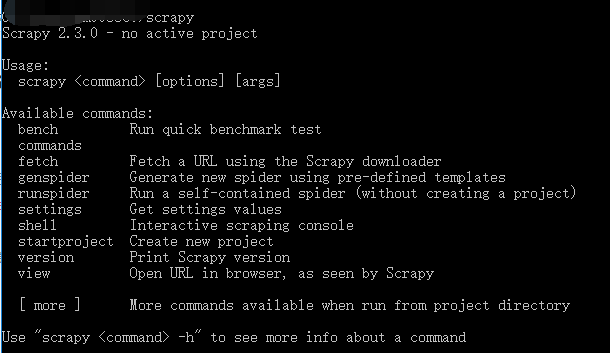

其他参考方法:win7安装scrapy
2.相关命令介绍
scrapy命令分为
- 全局命令:全局命令就是在哪都能用;
- 项目命令:项目命令就是只能依托你的项目;
2.1全局命令
全局命令就是上图安装测试时主动跳出来的那些命令
startproject、genspider、settings、runspider、shell、fetch、view、version
比较常用的有三个:
scrapy startproject project_name # 创建项目
scrapy crawl spider_name # 运行名为spider_name的爬虫项目
# 调试网址为https://blog.csdn.net/qq_35866846的网站
scrapy shell "https://blog.csdn.net/qq_35866846"
全局命令就是不依托项目存在的,也就是不关你有木有项目都能运行,
比如:startproject它就是创建项目的命令,肯定是没有项目也能运行;
详细用法说明:
-
startproject
# 使用频次最高,用于项目创建,eg:创建一个名为:cnblogSpider的项目 scrapy strartproject cnblogSpider -
genspider
# 用于创建爬虫模板,example是spider名称,生成文件在spiders下面,也是后面写爬虫的地方 # 注意spider名称不能和项目相同 scrapy genspider example example.com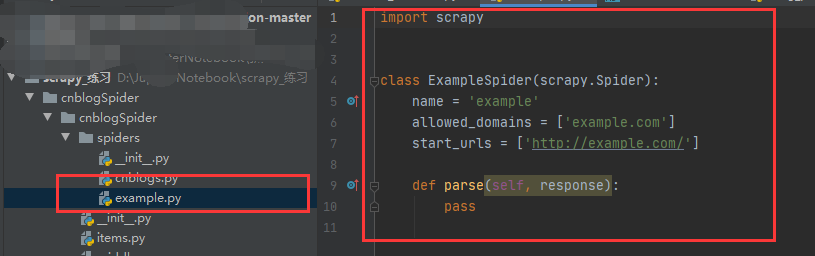
-
settings
# 查看scray参数设置 scrapy settings --get DOWNLOAD_DELAY # 查看爬虫的下载延迟 scrapy settings --get BOT_NAME # 爬虫的名字 -
runspider
运行蜘蛛除了使用前面所说的scrapy crawl XX之外,我们还能用:runspider;
crawl是基于项目运行,runspide是基于文件运行,
也就是说你按照scrapy的蜘蛛格式编写了一个py文件,如果不想创建项目,就可以使用runspider,eg:编写了一个:test.py的蜘蛛,你要直接运行就是:scrapy runspider test.py -
shell
# 这个命令比较重要,主要是调试用,里面还有很多细节的命令 # 最简单常用的的就是调试,查看我们的选择器到底有木有正确选中某个元素 scrapy shell "https://www.cnblogs.com/qiyeboy/default.html?page=1" # 然后我们可以直接执行response命令, #比如我们要测试我们获取标题的选择器正不正确: response.css("title").extract_first() # 以及测试xpath路径选择是否正确 response.xpath("//*[@id='mainContent']/div/div/div[2]/a/span").extract()

-
fetch
这个命令其实也可以归结为调试命令的范畴!它的功效就是模拟我们的蜘蛛下载页面,也就是说用这个命令下载的页面就是我们蜘蛛运行时下载的页面,这样的好处就是能准确诊断出,我们的到的html结构到底是不是我们所看到的,然后能及时调整我们编写爬虫的策略!举个栗子,淘宝详情页,我们一般看得到,但你如果按常规的方法却爬不到,为神马?因为它使用了异步传输!因此但你发现获取不到内容的时候,你就要有所警觉,感觉用fetch命令来吧它的html代码拿下来看看,到底有木有我们想要的那个标签节点,如果木有的话,你就要明白我们需要使用js渲染之类的技术!用法很简单:scrapy fetch http://www.scrapyd.cn就这样,如果你要把它下载的页面保存到一个html文件中进行分析,我们可以使用window或者linux的输出命令,这里演示window下如下如何把下载的页面保存:
scrapy fetch http://www.scrapyd.cn >d:/3.html
可以看到,经过这个命令,scrapy下载的html文件已经被存储,接下来你就全文找找,看有木有那个节点,木有的话,毫无悬念,使用了异步加载! -
view
# 和fetch类似都是查看spider看到的是否和你看到的一致,便于排错
scrapy view https://blog.csdn.net/qq_35866846
- version
# 查看scrapy版本
scrapy version
2.2项目命令
项目命令比较简单,感觉没什么好说的,我也没怎么详细测试,
直接参考这篇【scrapy 命令行:scrpay项目命令】
3.scrapy框架介绍
Scrapy 是一个用python写的Crawler Framework,简单轻巧,并且十分方便,使用Twisted这个一部网络库来处理网络通信,架构清晰,并包含了各种中间件接口,可以灵活地完成各种需求,整体架构组成如下图
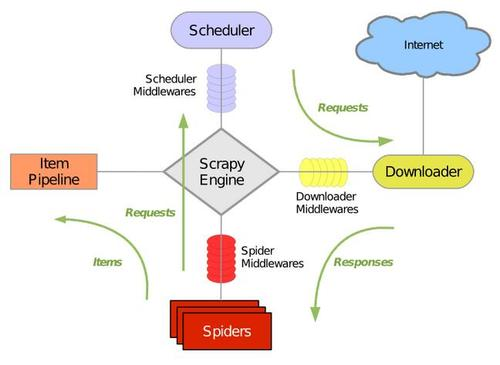
- Scrapy引擎(Engine): 引擎负责控制数据流在系统的所有组件中流动,并在相应动作发生时触发事件;
- 调度器(Scheduler): 调度器从引擎接收request 并将他们入队,以便之后引擎请求request时提供引擎;
- 下载器(Downloader): 下载器负责获取页面数据并提供给引擎,而后提供给Spider;
- Spider: Spider是Scrapy用户编写用于分析Response 并提取Item(即获取到的Item)或额外跟进的URL的类,每个Spider负责处理一个特定(或一些)网站
- Item Pipeline: Item Pipeline 负责处理被Spider提取出来的Item .典型的处理有清理验证及持久化(例如存储到数据库中);
- 下载器中间件(Downloader middlewares): 下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的Response。其提供了一个简单的机制,通过插入自定义代码来扩展Scrapy功能;
- Spider中间件(Spider middlwares): Spider中间件是在引擎及Spider之间的特定钩子(specific hook), 处理Spider的输入(response)和输出(items 及request)其中提供了一个简便的机制,通过插入自定义代码来实现Scrapy功能。
4.Scrapy中数据流的流转
-
引擎打开一个网站(open a domain),找到处理该网站的Spider 并向该Spider请求第一个要爬取的URL
-
引擎从Spider中获取第一个要爬取的URL并通过调度器(Schedule)以Request进行调度
-
引擎向调度器请求下一个要爬取的URL
-
调度器返回下一个要爬取的URL给引擎,引擎降URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)
-
一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎
-
引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理
-
Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎
-
引擎将(Spider返回的)爬取到的Item 给Item Pipeline,将(Spider返回的)Request给调度器
-
(从第二步)重复直到调度器中没有更多的Request,引擎关闭网站
5.第一个scrapy爬虫
七夜大佬《》的案例项目,由于书买的比较早,里面用的还是python2
自己动手在python3的环境下实现一下
5.1创建项目
# 创建一个名为cnblogSpider 的Scrapy项目
scrapy startproject cnblogSpider

创建好项目之后,直接使用pycharm打开,继续工作即可
结构性文件自动生成,把框架填充起来即可
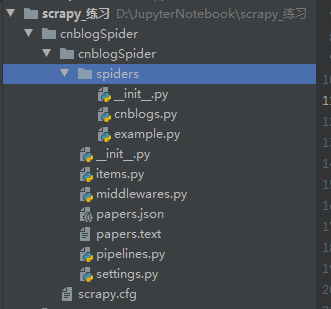
- scrapy.cfg: 项目部署文件
- cnblogSpider/ : 给项目的python模块,之后可以在此加入代码
- cnblogSpider/items.py:项目中的Item文件
- cnblogSpider/pipelines.py:项目中的Pipelines文件
- cnblogSpider/settings.py:项目的配置文件
- cnblogSpider/spiders/:放置Spider代码的目录
5.2创建爬虫模块
from ..items import CnblogspiderItem
class CnblogsSpider(scrapy.Spider):
name = "cnblogs" # 爬虫的名称
allowed_domains = ["cnblogs.com"] # 允许的域名
start_urls = [
"https://www.cnblogs.com/qiyeboy/default.html?page=1"
]
def parse(self, response):
# 实现网页解析
# 首先抽取所有文章
papers = response.xpath("//*[@class='day']")
# 从每篇文章中抽取数据
for paper in papers:
url = paper.xpath(".//*[@class='postTitle']/a/@href").extract()[0]
title = paper.xpath(".//*[@class='postTitle']/a/span/text()").extract()[0]
time = paper.xpath(".//*[@class='dayTitle']/a/text()").extract()[0]
content = paper.xpath(".//*[@class='postCon']/div/text()").extract()[0]
# print(url, title, time, content)
item = CnblogspiderItem(url=url, title=title, time=time, content=content)
yield item
next_page = Selector(response).re(u'<a href="(\S*)">下一页</a>')
if next_page:
yield scrapy.Request(url=next_page[0], callback=self.parse)
5.3定义item
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class CnblogspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
url = scrapy.Field()
time = scrapy.Field()
title = scrapy.Field()
content = scrapy.Field()
class newCnblogsItem(CnblogspiderItem):
body = scrapy.Field()
# title = scrapy.Field(CnblogspiderItem.Fields['title'], serializer = my_serializer)
5.4构建Item Pipeline
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import json
from scrapy.exceptions import DropItem
from .items import CnblogspiderItem
class CnblogspiderPipeline(object):
def __init__(self):
self.file = open('papers.json', 'w', encoding='UTF-8')
def process_item(self, item, spider):
if item['title']:
line = json.dumps(dict(item)) + '\n'
# print(type(line))
# self.file.write(line.encode())
# 注意open "wb" 写入的是字节流,“w”写入的是str
# 使用decode 和 encode进行字节流和str的相互转化
self.file.write(line)
return item
else:
raise DropItem(f"Missing title in {
item}")
5.5 激活Item Pipeline
定制完Item Pipeline ,它是无法工作的需要进行激活,要启用一个Item Pipeline组件
必须将它的类添加到settings.py中的ITEM_PIPELINES 变量中
自动创建的Scrapy直接把settings.py中的该行取消注释即可
TEM_PIPELINES 变量中可以配置很多个Item Pipeline组件,分配给每个类的整型值确定了他们的运行顺序,item 按数字从低到高的顺序通过Item Pipeline,取值范围0 ~1000
ITEM_PIPELINES = {
'cnblogSpider.pipelines.CnblogspiderPipeline': 300,
}
激活完成后,将命令行切换到项目目录下执行
scrapy crawl cnblogs

参考资料
【1】书《python爬虫开发与项目实战》和 随书代码
【2】scrapy1.5中文文档
写在最后的拉票环节
最近参加了CSDN官方组织的“GEEK+”原创·博主大赛
历经重重筛选,终于上榜TOP 50
原创不易,帮忙投个免费的票
支持一下:点击投票
谢谢大家!!!
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/153151.html原文链接:https://javaforall.net


