
大家好,又见面了,我是你们的朋友全栈君。
简介:本文主要介绍netflix conductor的基本概念和主要运行机制。


作者 | 夜阳
来源 | 阿里技术公众号
本文主要介绍netflix conductor的基本概念和主要运行机制。
一 简介
netflix conductor是基于JAVA语言编写的开源流程引擎,用于架构基于微服务的流程。它具备如下特性:
- 允许创建复杂的业务流程,流程中每个独立的任务都是由一个微服务所实现。
- 基于JSON DSL 创建工作流,对任务的执行进行编排。
- 工作流在执行的过程中可见、可追溯。
- 提供暂停、恢复、重启等多种控制模型。
- 提供一种简单的方式来最大限度重用微服务。
- 拥有扩展到百万流程并发运行的服务能力。
- 通过队列服务实现客户端与服务端的分离。
- 支持 HTTP 或其他RPC协议进行数据传送
二 基本概念
1 Task
Task是最小执行单元,承载了一段执行逻辑,如发送HTTP请求等。
- System Task:被conductor服务执行,这些任务的执行与引擎在同一个JVM中。
- Worker Task:被worker服务执行,执行与引擎隔离开,worker通过队列获取任务后,执行并更新结果状态到引擎。Worker的实现是跨语言的,其使用Http协议与Server通信。
conductor提供了若干内置SystemTask:
-
功能性Task:
- HTTP:发送http请求
- JSON_JQ_TRANSFORM:jq命令执行,一般用户json的转换,具体可见jq官方文档
- KAFKA_PUBLISH: 发布kafka消息
-
流程控制Task:
- SWITCH(原Decision):条件判断分支,类似于代码中的switch case
- FORK:启动并行分支,用于调度并行任务
- JOIN:汇总并行分支,用于汇总并行任务
- DO_WHILE:循环,类似于代码中的do while
- WAIT:一直在运行中,直到外部时间触发更新节点状态,可用于等待外部操作
- SUB_WORKFLOW:子流程,执行其他的流程
- TERMINATE:结束流程,以指定输出提前结束流程,可以与SWITCH节点配合使用,类似代码中的提前return语句
-
自定义Task:
- 对于System Task,Conductor提供了WorkflowSystemTask 抽象类,可以自定义扩展实现。
- 对于Worker Task,可以实现conductor的client Worker接口实现执行逻辑。
2 Workflow
- Workflow由一系列需要执行的Task组成,conductor采用json来描述Task的流转关系。
- 除基本的顺序流程外,借助内置的SWITCH、FORK、JOIN、DO_WIHLE、TERMINATE任务,还能实现分支、并行、循环、提前结束等流程控制。
3 Input&Output
Task的输入是一种映射,其作为工作流实例化的一部分或某些其他Task的输出。允许将来自工作流或其他Task的输入/输出作为随后执行的Task的输入。
- Task有自己的输入和输出,输入输出都是jsonobject类型。
- Task可以引用其他Task的输入输出,使用${taskxxx.output}的方式引用。引用语法为json-path,除最基础的${taskxxx.output}的值解析方式外,还支持其他复杂操作,如过滤等,具体见json-path语法。
- 启动Workflow时可以传入流程的输入数据,Task可以通过${workflow.input}的方式引用。
Task实现原子操作的处理以及流程控制操作,Workflow定义描述Task的流转关系,Task引用Workflow或者其它Task的输入输出。通过这些机制,conductor实现了JSON DSL对流程的描述。
三 整体架构
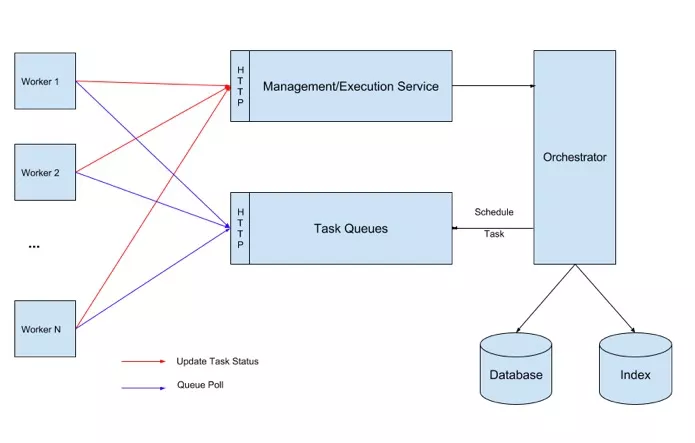
- Orchestrator: 负责流程的流转调度工作;
- Management/Execution Service: 提供流程、任务的管理更新等操作;
- TaskQueues: 任务队列,Orchestrator解析出来的待执行Task会放到队列中;
- Worker: 任务执行worker,从TaskQueues中获取任务,通过Execution Service更新任务状态与结果数据;
- Database: 元数据&运行时数据库,用于保存运行时的Workflow、Task等状态信息,以及流程任务定义的等原信息;
- Index: 索引数据库,用于存储执行历史;
四 运行模型
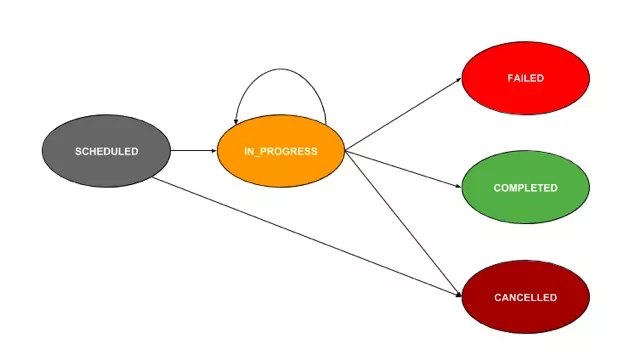
1 Task状态转移
- SCHEDULED:待调度,task放到队列中还没有被poll出来执行时的状态
- IN_PROGRESS:执行中,被poll出来执行但还没有完成时的状态
- COMPLETED:执行完成
- FAILED:执行失败
-
CANCELLED:被中止时为此状态,一般出现在两种情况:
- 手动中止流程时,正在运行中的task会被置为此状态;
- 多个fork分支,当某个分支的task失败时,其它分支中正在运行的task会被置为此状态;
任务的执行(同步的系统任务除外)都会先添加到任务队列中,是典型的生产者消费者模式。
- 任务队列,是一个带有延迟、优先级功能的队列;
- 每种类型的Task是一个单独的队列,此外,如果配置了domain、isolationGroup,还会拆分成多个队列实现执行隔离;
- decider service是生产者,其根据流程配置与当前执行情况,解析出可执行的task后,添加到队列;
- 任务执行器(SystemTaskWorker、Worker)是消费者,其长轮询对应的队列,从队列中获取任务执行;
队列接口可插拔,conductor提供了Dynomite 、MySQL、PostgreSQL的实现。
3 核心功能实现机制
conductor调度的核心是decider service,其根据当前流程运行的状态,解析出将要执行的任务列表,将任务入队交给worker执行。
decide主要流程简化如下,详细代码见WorkflowExecutor.java的decide方法:
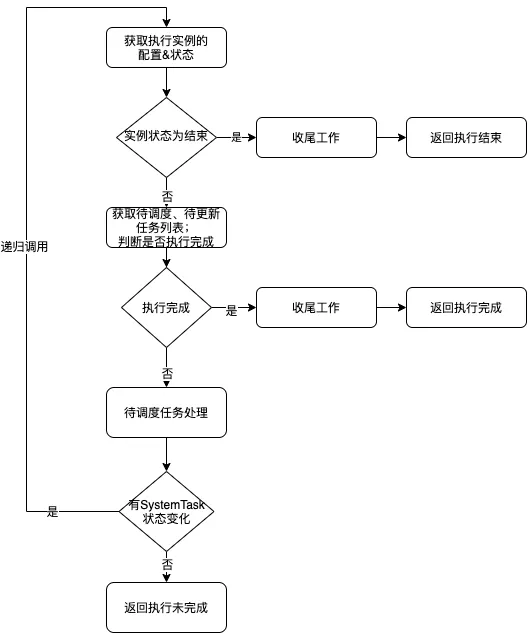
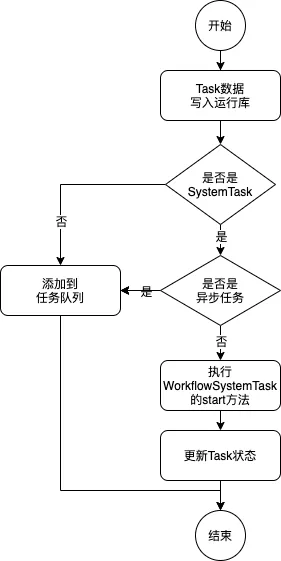
最主要的触发时机:
- 新启动执行时,会触发decide操作
- 系统任务执行完成时,会触发decide操作
- Workder任务通过ExecutionService更新任务状态时,会触发decide操作
流程控制节点的实现机制
1)Task & TaskMapper
对于每一个Task来说,都有Task和TaskMapper两部分:
- Task:任务的执行逻辑代码,它的作用是Task的执行
- TaskMapper:任务的映射逻辑代码,它通过Task的定义配置、当前实例的执行状态等信息,返回实际需要执行的Task列表
对于一般的任务来说,TaskMapper返回的是就是Task本身,补充一些执行实例的状态信息。但是对于控制节点来说,会有不同的逻辑。
2)条件分支(SWITCH)的实现机制
SWITCH用于根据条件判断,执行不同的分支。
实际上,该节点的Task不做任何操作,TaskMapper根据分支条件,判断出要走的分之后,返回对应分支的第一个Task。
SwitchTaskMapper.java getMappedTasks方法关键代码:
// 待调度的Task list,最终返回结果
List<Task> tasksToBeScheduled = new LinkedList<>();
// evalResult是分支条件变量的值(case)
// decisionCases是一个Map结构,key为分支的case值,value为对应分支的任务定义list(分支内的任务定义会有多个)
// 根据分支变量的实际值,获取对应分支的任务定义list
List<WorkflowTask> selectedTasks = taskToSchedule.getDecisionCases().get(evalResult);
// default的逻辑:如果获取不到对应的分支或者分支为空,则用默认的分支
if (selectedTasks == null || selectedTasks.isEmpty()) {
selectedTasks = taskToSchedule.getDefaultCase();
}
if (selectedTasks != null && !selectedTasks.isEmpty()) {
// 获取分支的第一个(下标0)task,返回给decider service去做调度(decider会把任务添加到队列里,交给worker去执行)
WorkflowTask selectedTask = selectedTasks.get(0);
// 调用了deciderService的getTasksToBeScheduled方法,此方法里又获取到TaskMapper调用了getMappedTasks。这里采用了递归调用的方式,解析嵌套的Task
List<Task> caseTasks = taskMapperContext.getDeciderService()
.getTasksToBeScheduled(workflowInstance, selectedTask, retryCount, taskMapperContext.getRetryTaskId());
tasksToBeScheduled.addAll(caseTasks);
switchTask.getInputData().put("hasChildren", "true");
}
return tasksToBeScheduled; 
3)并行(FORK)的实现机制
FORK用于开启多个并行分支。
实际上,该节点的Task不做任何操作,TaskMapper返回所有并行分支的第一个Task。
ForkJoinTaskMapper.java getMappedTasks关键代码:
// 待调度的Task list,最终返回结果
List<Task> tasksToBeScheduled = new LinkedList<>();
// 配置中的所有fork分支
List<List<WorkflowTask>> forkTasks = taskToSchedule.getForkTasks();
for (List<WorkflowTask> wfts : forkTasks) {
// 每个分支取第一个Task
WorkflowTask wft = wfts.get(0);
// 调用了deciderService的getTasksToBeScheduled方法,此方法里又获取到TaskMapper调用了getMappedTasks。这里采用了递归调用的方式,解析嵌套的Task
List<Task> tasks2 = taskMapperContext.getDeciderService()
.getTasksToBeScheduled(workflowInstance, wft, retryCount);
tasksToBeScheduled.addAll(tasks2);
}
return tasksToBeScheduled;
总的来说,分支(SWITCH)、并行(FORK)节点本身没有执行逻辑,其通过TaskMapper返回到实际要执行的Task,然后交给Decider Service处理。
重试的实现机制
重试和其延迟时间设置,都是借助任务队列的功能实现的。
重试:将任务重新添加到任务队列
重试的延迟时间:添加到任务队列时设置延迟时间,延迟时间过后,任务才能在队列中被poll出来执行
五 完整性保障机制
由于调度过程中可能会出现因机器重启、网络异常、JVM崩溃等偶发情况,这些会导致的decide过程意外终止,流程执行不完整,展现出如流程一直运行中(实际已经没有在调度),或者其它状态错误等异常现象。
1 WorkflowReconciler
针对这种情况,conductor有一个WorkflowReconciler,会定期尝试decide所有正在运行中的流程,修复流程执行的一致性。此外,它还有一个作用是校验流程超时时间。
2 decideQueue
那么WorkflowReconciler是如何获取到当前运行中的流程呢,答案是decideQueue。
decideQueue和任务队列相同,也是一个具有延迟功能的队列,其存放的是正在执行中的流程的实例id。在任务开始执行时(包括新启动执行、重试执行、恢复执行、重跑执行等),会将实例id push到decideQueue中;在执行结束(成功、失败)时,会从decideQueue中删除实例id。
3 ExecutionLockService
WorkflowReconciler会定期尝试decide所有正在运行中的流程用于超时判断、维护流程一致性。但是流程本身正常执行也会触发decide,如果同一个执行同时触发两个decide,可能会导致状态混乱,执行卡住等问题。
conductor采用了锁来解决这个问题,其提供了单机LocalOnlyLock(基于信号量实现)、redis分布式锁(基于redission实现)、zookeeper分布式锁三种实现。
decide方法中最开始会尝试获取锁,如果获取失败则直接返回。通过锁来保障不会对同一个流程实例并发执行decide。
if (!executionLockService.acquireLock(workflowId)) {
return false;
}
由于锁是可配置的,可能会导致一个误区:单台机器的话不用配置锁。其实单机也是需要配置锁的,因为WorkflowReconciler和流程正常执行会产生冲突,可能会导致偶发的流程状态混乱问题。
原文链接
本文为阿里云原创内容,未经允许不得转载。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/155115.html原文链接:https://javaforall.net


