
大家好,又见面了,我是你们的朋友全栈君。
什么是模板引擎?
模板引擎是将数据要变为试图最优雅的解决方案,从数据到视图的转换中,发展出的转换写法都是为了方便让数据和视图的对应关系更清晰。
数据变试图的方法
- 纯DOM法:非常笨拙,没有实战价值
let div = document.createElement('div')
div.innerText = '小明'
doument.body.append(div)
- 数组join法:曾经非常流行,是曾经前端必会的知识
let ul = document.createElemet('ul');
let data = [
{
name: '小明', age: 18},
{
name: '小白', age: 16}
]
for (let i = 0; i < data.length; i++) {
ul.innerHTML += [
'<li>',
' <div>姓名:' + data[i].name + '</div>',
' <div>年龄:' + data[i].age + '</div>',
'</li>'
].join('')
}
doument.body.append(ul)
- ES6的反引号法:ES6中新增的`${a}`语法糖
let ul = document.createElemet('ul');
let data = [
{
name: '小明', age: 18},
{
name: '小白', age: 16}
]
for (let i = 0; i < data.length; i++) {
ul.innerHTML += ` <li> <div>姓名:${
data[i].name}</div> <div>年龄:${
data[i].age}</div> </li> `
}
doument.body.append(ul)
- 模板引擎:解决数据变为试图的最优雅的方法
mustache是“胡子”的意思,因为它的数据模板语法是{
{}}非常像胡子
官方git:https://github.com/janl/mustache.js
模板引擎mustache
mustache简单使用,创建html文件并在添加上mustache的cdn链接。在官方的例子中,使用就script标签来防止html结构的模板,使用script标签来存放模板有两个好处。一是script中的标签可以通过非规则的type属性值来避免该标签内的脚本被解析,且script标签内的内容不会直接显示到用户的页面上;二是在编写模板的时候可以得到IDE的语法提示功能。
script的type可选值:
- text/javascript
- text/ecmascript
- application/ecmascript
- application/javascript
- text/vbscript
<html>
<body>
<div id="app"></div>
<script id="template" type="mustache-template"> Hello {
{
name}} </script>
<script src="https://unpkg.com/mustache@latest"></script>
<script> let template = document.getElementById('template').innerHTML; let app = document.getElementById('app'); let data = {
name: '小明'}; let rendered = Mustache.render(template, data); app.innerHTML = rendered; </script>
</body>
</html>
mustache引擎调用的Mustache.render()来渲染模板并返回渲染后的字符串,第一个参数为HTML结构模板,第二个参数为数据对象。
mustache机制
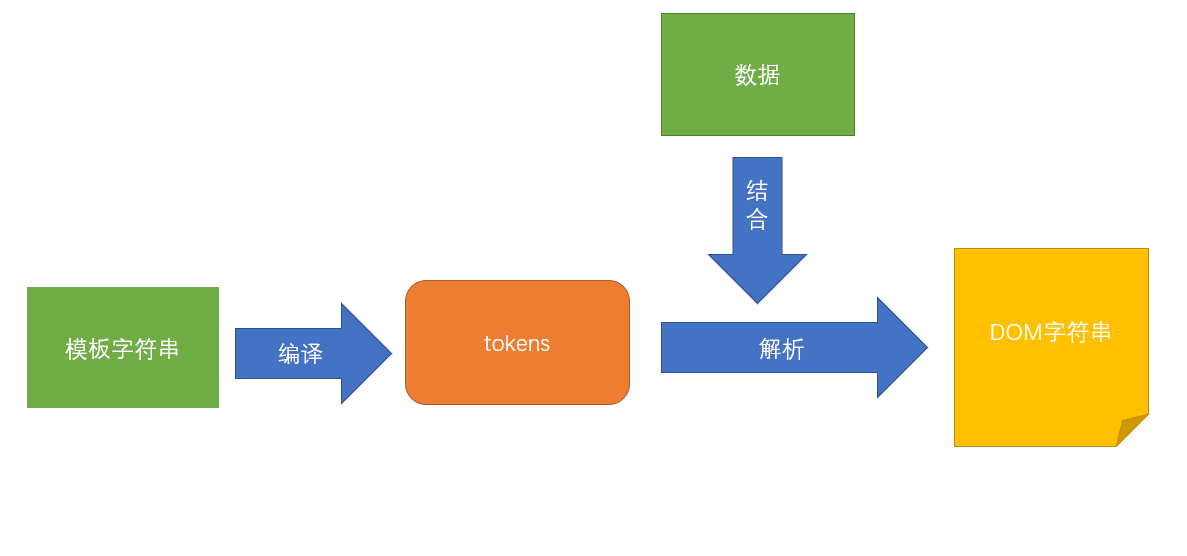

mustache首先将模板字符串编译形成tokens数组,然后解析tokens数组并结合数组而形成DOM字符串。
tokens是一个JS的嵌套数组,即模板字符串的JS表示。它是“抽象语法树”、“虚拟节点”的开山鼻祖。
例如:模板字符串为
<h1>我是{
{name}},今年{
{age}}岁了。</h1>
tokens数组的结构如下:
tokens = [
["text", "<h1>我是"],
["name", "name"],
["text", ",今年"],
["name", "age"],
["text", "岁了。</h1>"]
]
如果数据中有需要遍历渲染的数据,(遍历数组或对象的语法为#name.../name如果是数组取值时用点(句号),如果是对象取值时用属性名)模板如下:
<div>
{
{comic}}的反派怪兽:
<ol>
{
{#monsters}}
<li>
{
{.}}
</li>
{
{/monsters}}
</ol>
</div>
则tokens数组样式如下:
tokens = [
["text", "<div>"],
["name", "comic"],
["text", "的反派怪兽:<ol>"],
["#", "mosters", [
["text", "<li>"],
["name", "."],
["text", "</li>"]
]],
["text", "</ol></div>"]
]
tokens数组内的每一个元素都是一条token,每条token一般有2个元素,分别为标识符和模板子串。
token第一个元素
- text:标识无需数据的模板子串
- name:标识数据键名
- #:标识此处需要一个嵌套的数据,数组、对象等
如果是#标识的token,则还会有第三个元素,该元素为下一级的tokens,后面的嵌套数据就如此嵌套下去。
仿写mustache
仿写前需要先确定好大体的框架结构,需要哪些方法及步骤等,这里只模仿简单的实现及渲染功能。
在mustache的机制中能够看到需要用户提供的是数据和模板字符串,而引擎需要执行的功能有编译模板生成tokens、解析tokens并提取数据、渲染dom字符串等功能。
1、编译(解析模板成tokens)
在编译前肯定是需要先扫描模板字符串,并将字符串分段再根据每一段字串来判断token的组合。
先定义一个扫描辅助类
class Scanner {
constructor(templateStr) {
this.templateStr = templateStr; // 原模板字符串
this.pos = 0; // 当前扫描字符串时的下标,初始从0开始
this.tail = templateStr; // 剩余待扫描的模板子串,初始为整串
}
// 判断模板字符串是否扫描完成,true表示扫描完成(end of string)
eos() {
return this.pos >= this.templateStr.length;
}
// 扫描模板字符串,直到遇到停止标识符号
scanUtil(stopTag) {
const posBackUp = this.pos; // 记录扫描开始前的下标
// 字符串没有扫描完成且未扫描的字符串开头不是停止标识
while(!this.oes && this.tail.indexOf(stopTag) !== 0) {
this.pos++; // 下标前进
this.tail = this.templateStr.substring(this.pos); // 扫描一个字符就去除待扫描串开头的一个字符
}
return this.templateStr.substring(posBackUp, this.pos); // 返回扫描到的子串
}
// 跳过开头tag
scan(tag) {
if (this.tail.indexOf(tag) === 0) {
// 监测是否为tag开头,不是则不操作
this.pos += tag.length; // 下标滑过tag
this.tail = this.templateStr.substring(this.pos); // 待扫描串滑过tag
}
}
}
扫描类存在3个方法,eos()、scanUtil()、scan()在扫描模板字符串时,调用方式应该为scanUtil(开始标志) => scan(开始标志) => scanUtil(结束标志) => scan(结束标志),这样就成功取到了一次token的模板子串,只需要循环判断eos()是否完成就可以扫描出模板中的全部token。
扫描工具将整个模板字符串拆分成了模板子串,然后就是将模板子串组合成token了。定义函数parseTemplateToTokens(),该函数返回组合好了tokens数组,参数为模板字符串
function parseTemplateToTokens(templateSte) {
let tokens = [];
let scanner = new Scanner(templateStr);
let words; // 扫描到的模板子串
let startTag = '{
{', endTag = '}}'; // 定义模板的语法标记
while (!scanner.eos()) {
words = scanner.scanUitl(startTag);
if (words !== '') {
// 如果一开始就是{
{,就无需再执行,所以要排除这种情况
// 删除模板子串中的多余空格和换行(不考虑需要正常输出的空格)
let isInLabel = false; // 单个空白字符,包括空格、制表符、换页符、换行符
let _words = '';
for (let i = 0; i < words.length; i++) {
if (words[i] === '<') {
isInLabel = true;
} else if (words[i] === '>') {
isInLabel = false;
}
if (!/\s/.test(word[i])) {
// \s 匹配单个空白字符,包括空格、制表符、换页符、换行符
_words += words[i];
} else {
if (isInLabel) {
_words += ' ';
}
}
}
tokens.push(['text', _words]);
}
scanner.scan(startTag);
// 开始扫描变量
words = scanner.scanUtil(endTag);
if (words !== '') {
if (words[0] === '#') {
tokens.push(['#', words.substring(1)]); // 嵌套结构开始符
} else if (words[0] === '/') {
tokens.push(['/', words.substring(1)]); // 嵌套结构结束符
} else {
tokens.push(['name', words]); // 变量名称
}
}
scanner.scan(endTag);
}
return nestTokens(tokens); // 收缩嵌套结构
}
上面解析模板的方法最后的tokens中,是多条token的结合,但是如果存在数据为嵌套结构时就需要将嵌套的结构放到token数组的第三个元素的位置,所以返回前要调用nestTokens(tokens)。
nestTokens()方法是用来折叠token的,如果不折叠的话解析函数将返回如下tokens
tokens = [
["text", "<div>"],
["name", "comic"],
["text", "的反派怪兽:<ol>"],
["#", "mosters"],
["text", "<li>"],
["name", "."],
["text", "</li>"],
["/", "mosters"],
["text", "</ol></div>"]
]
可以明显的开到结构中的#和/是将须折叠的内容是包裹起来的,所以才需要将#与/之间的元素合并起来放到token的第三个元素上,这样结构就能够更清晰。
nestToTokens()函数如下:
function nestToTokens() {
let nestedTokens = [];
let stack = [];
// 收集器,默认往嵌套好的tokens数组中收集
// 收集器指向哪个数组就表示往哪个数组中进行收集数据
let collector = nestedTokens; // 用于操作当前正在收集的项,如果进入#中就表示收集的嵌套项
for (let i = 0; i< tokens.length; i++) {
let token = tokens[i];
switch (token[0]) {
case '#': // 嵌套开始
collector.push(token);
stack.push(token);
collector = token[2] = [];
break;
case '/': // 嵌套结束
stack.pop();
collector = stack.length > 0 ? stack[stack.length - 1][2] : nestedTokens;
break;
default:
collector.push(token); // 不嵌套token,直接放入nestedTokens,此时collector一定指向nestedTokens
}
}
return nestedTokens;
}
2、数据读取
在tokens数组中以及构建好了需要使用的变量名及数据的多层嵌套,所以现在只需要根据变量名和嵌套结构来取值了。创建lookup函数用于获取变量值,参数一:用户提供需要渲染的data对象,参数二:模板中的变量名
在获取属性值时需要考虑两种情况,一是只有一层属性名的方式,二是带有多层级的属性名
function lookup(data, keyName) {
if (keyName.indexOf('.') !== -1 && keyName !== '.') {
let keys = keyName .split('.');
let temp = data;
for (let i = 0; i < keys.length; i++) {
temp = temp[keys[i]]; // 深度遍历属性名
}
return temp; // 返回最后的属性值
}
return data[keyName]; // 如果没有.属性就直接获取
}
3、渲染数据到模板
创建renderTemplate函数来将tokens和数据data进行结合解析成dom字符串。
function renderTemplate(tokens, data) {
let resultStr = '';
for (let i = 0; i < tokens.length; i++) {
let token = tokens[i];
if (token[0] === 'text') {
// 直接添加模板子串
resultStr += token[1];
} else if (token[0] === 'name') {
// 添加变量值
resultStr += lookup(data, token[1]);
} else if (token[0] === '#') {
// 处理嵌套token
resultStr += parseArray(token, data); // 因为嵌套的token填写属性名时有可能是.所以要另外处理
}
}
return resultStr;
}
tokens数组中不仅有直接使用属性名的变量,还有嵌套token中的变量名.,所以处理嵌套token的时候需要另外处理,定义parseArray函数,参数一:带嵌套结构的token,参数二:data数据
function parseArray(token, data) {
let v = lookup(data, token[1]);
let resultStr = '';
for (int i = 0; i < v.length; i++) {
// 在嵌套渲染时可能存在.的属性名,所以在解构后的对象中加入一个.属性
resultStr += renderTemplate(token[2], {
...v[i], '.': v[i]}); // 因为嵌套token的第三个元素也是一个tokens,所以可以直接递归的调用渲染函数
}
return resultStr;
}
到此整个渲染过程就完成了,从模板字符串加数据到拼接好的dom字符串。将数据返回后只需将dom字符串添加到dom中就可以实现渲染后的展示了。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/161557.html原文链接:https://javaforall.net


