
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
摘要
当今研究领域的一项事实就是,前向神经网络(feed-forward neural networks)的训练速度比人们所期望的速度要慢很多。并且,在过去的几十年中,前向神经网络在应用领域存在着很大的瓶颈。导致这一现状的两个关键因素就是:
- 神经网络的训练,大多使用基于梯度的算法,而这种算法的训练速度有限;
- 使用这种训练算法,在迭代时,网络的所有参数都要进行更新调整。
而在2004年,由南洋理工学院黄广斌教授所提出的极限学习机器(Extreme Learning Machine,ELM)理论可以改善这种情况。最初的极限学习机是对单隐层前馈神经网络(single-hidden layer feed-forward neural networks,SLFNs)提出的一种新型的学习算法。它随机选取输入权重,并分析以决定网络的输出权重。在这个理论中,这种算法试图在学习速度上提供极限的性能。
如需转载本文,请注明出处:http://blog.csdn.net/ws_20100/article/details/49555959
极限学习机原理
ELM是一种新型的快速学习算法,对于单隐层神经网络,ELM 可以随机初始化输入权重和偏置并得到相应的隐节点输出:

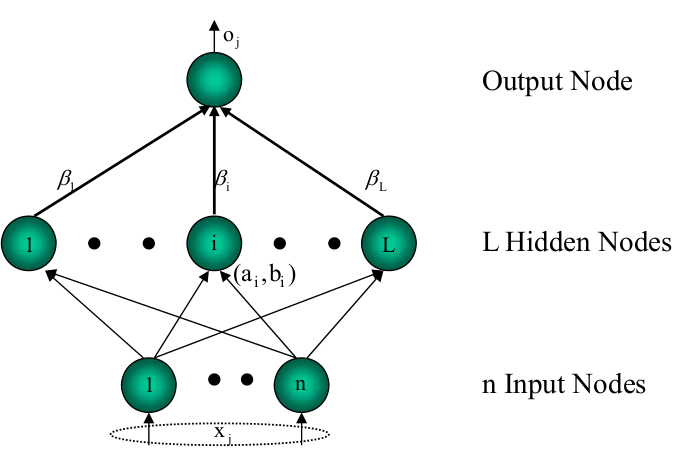
对于一个单隐层神经网络(结构如上图所示),假设有
N
(xj,tj)
xj=[xj1,xj2,...,xjn]T∈Rn , tj=[tj1,tj2,...,tjm]T∈Rm
对于一个有
L
∑i=1Lβig(wi⋅xj+bi)=oj, j=1,2,...,N
其中,
g(x)
wi=[wi1,wi2,...,win]T
i
bi
i
βi=[βi1,βi2,...,βim]T
i
wi⋅xj
wi
xj
1.学习目标
单隐层神经网络学习的目标是使得输出的误差最小,可以表示为
∑j=1N||oj−tj||=0
即存在
wi
xj
bi
∑i=1Lβig(wi⋅xj+bi)=tj, j=1,2,...,N
可以矩阵表示:
H⋅β=T
其中,
H
β
T
H(w1,...,wL,b1,...,bL,x1,...,xN)=⎡⎣⎢⎢g(w1⋅x1+b1)⋮g(w1⋅xN+b1)⋯⋯⋯g(wL⋅x1+bL)⋮g(wL⋅xN+bL)⎤⎦⎥⎥N×Lβ=⎡⎣⎢⎢β1T⋮βLT⎤⎦⎥⎥L×m T=⎡⎣⎢⎢t1T⋮tNT⎤⎦⎥⎥N×m
为了能够训练单隐层神经网络,我们希望得到
wi^
bi^
βi^
||H(wi^,bi^)⋅β^−T||=minw,b,β||H(wi,bi)⋅β−T||
其中,
i=1,2,...,L
E=∑j=1N||∑i=1Lβi⋅g(wi⋅xj+bi)−tj||22
2.学习方法
传统的一些基于梯度下降法的算法,可以用来求解这样的问题,但是基本的基于梯度的学习算法需要在迭代的过程中调整所有参数。而在ELM算法中, 一旦输入权重
wi
bi
H
H⋅β=T
β^=H†⋅T
其中,
H†
H
Moore−Penrose
β^
实现代码
代码下载:http://download.csdn.net/detail/ws_20100/9230271
输入的训练数据,格式为一个
N×(1+n)
N
tj
xj∈Rn
对于回归应用,一个例子为:
[TrainingTime, TestingTime, TrainingAccuracy, TestingAccuracy] = elm('sinc_train', 'sinc_test', 0, 20, 'sig')对于分类应用,一个例子为:
elm('diabetes_train', 'diabetes_test', 1, 20, 'sig')这两个训练和测试集在黄广斌教授的网站上都可以下载。
参考资料:
[1] G.-B. Huang, Q.-Y. Zhu, and C.-K. Siew, “Extreme learning machine: A new learning scheme of feedforward neural networks,” in Proc. Int. Joint Conf. Neural Networks, July 2004, vol. 2, pp. 985–990.
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/167918.html原文链接:https://javaforall.net


