
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
DTW(动态时间调整)
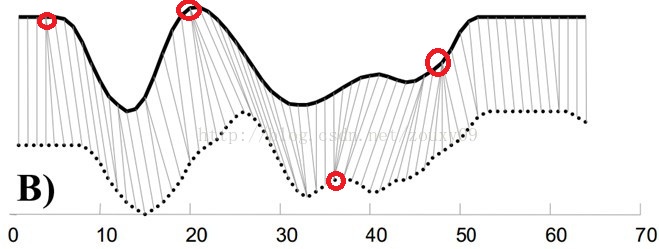

动态时间调整算法是大多用于检测两条语音的相似程度,由于每次发言,每个字母发音的长短不同,会导致两条语音不会完全的吻合,动态时间调整算法,会对语音进行拉伸或者压缩,使得它们竟可能的对齐。
如上图红圈标注的位置,可以发现下面那条线中有许多的点与之对应,如果换成一个个离散的点表示的话,实际上是对上一条曲线该点进行了拉伸处理,使得它们最大化对齐。
最近在研究时间序列的问题,时间序列类似这个。假如我想计算两条天气的时间序列是否相似,由于时间序列有的时候会出现延迟的现象,导致两条时间序列吻合的不好,可以通过这样的方法来准确的计算。
这个算法的实现和动态规划十分相似。
为了对齐这两个序列,我们需要构造一个n x m的矩阵网格,矩阵元素(i, j)表示qi和cj两个点的距离d(qi, cj)(也就是序列Q的每一个点和C的每一个点之间的相似度,距离越小则相似度越高。这里先不管顺序),一般采用欧式距离,d(qi, cj)= (qi-cj)2(也可以理解为失真度)。每一个矩阵元素(i, j)表示点qi和cj的对齐。DP算法可以归结为寻找一条通过此网格中若干格点的路径,路径通过的格点即为两个序列进行计算的对齐的点。
那么这条路径我们怎么找到呢?那条路径才是最好的呢?也就是刚才那个问题,怎么样的warping才是最好的。
注明:两个序列长度不同,不能使用欧氏距离进行匹配。使用dtw时,上图方格中的每个连续的点(开头(1,1)和结尾(m,n)还是要保证的)构成的曲线都有可能,这是就要找出代价最小的那条曲线,如图中标出的黑色曲线。
我们把这条路径定义为warping path规整路径,并用W来表示, W的第k个元素定义为wk=(i,j)k,定义了序列Q和C的映射。这样我们有:
首先,这条路径不是随意选择的,需要满足以下几个约束:
1)边界条件:w1=(1, 1)和wK=(m, n)。任何一种语音的发音快慢都有可能变化,但是其各部分的先后次序不可能改变,因此所选的路径必定是从左下角出发,在右上角结束。
2)连续性:如果wk-1= (a’, b’),那么对于路径的下一个点wk=(a, b)需要满足 (a-a’) <=1和 (b-b’) <=1。也就是不可能跨过某个点去匹配,只能和自己相邻的点对齐。这样可以保证Q和C中的每个坐标都在W中出现。
3)单调性:如果wk-1= (a’, b’),那么对于路径的下一个点wk=(a, b)需要满足0<=(a-a’)和0<= (b-b’)。这限制W上面的点必须是随着时间单调进行的。以保证图B中的虚线不会相交。
结合连续性和单调性约束,每一个格点的路径就只有三个方向了。例如如果路径已经通过了格点(i, j),那么下一个通过的格点只可能是下列三种情况之一:(i+1, j),(i, j+1)或者(i+1, j+1)。
满足上面这些约束条件的路径可以有指数个,然后我们感兴趣的是使得下面的规整代价最小的路径:
分母中的K主要是用来对不同的长度的规整路径做补偿。我们的目的是什么?或者说DTW的思想是什么?是把两个时间序列进行延伸和缩短,来得到两个时间序列性距离最短也就是最相似的那一个warping,这个最短的距离也就是这两个时间序列的最后的距离度量。在这里,我们要做的就是选择一个路径,使得最后得到的总的距离最小。
这里我们定义一个累加距离cumulative distances。从(0, 0)点开始匹配这两个序列Q和C,每到一个点,之前所有的点计算的距离都会累加。到达终点(n, m)后,这个累积距离就是我们上面说的最后的总的距离,也就是序列Q和C的相似度。
累积距离γ(i,j)可以按下面的方式表示,累积距离γ(i,j)为当前格点距离d(i,j),也就是点qi和cj的欧式距离(相似性)与可以到达该点的最小的邻近元素的累积距离之和:
注明:先把模板序列和测试序列的每个点相对应的距离算出来,构成一个m xn的矩阵。然后根据每个元素的代价计算一条最短路径。这里的计算要符合以上三个约束。即,一个点的代价=这个点的值+来自min{下、左、斜下这三个方向的值}。下、左、斜下这三个方向的值可以依次递归求得,直到(1,1)点
3 例子
这个例子中假设标准模板R为字母ABCDEF(6个),测试模板T为1234(4个)。R和T中各元素之间的距离已经给出。如下:

既然是模板匹配,所以各分量的先后匹配顺序已经确定了,虽然不是一一对应的。现在题目的目的是要计算出测试模板T和标准模板R之间的距离。因为2个模板的 长度不同,所以其对应匹配的关系有很多种,我们需要找出其中距离最短的那条匹配路径。现假设题目满足如下的约束:当从一个方格((i-1,j-1)或者 (i-1,j)或者(i,j-1))中到下一个方格(i,j),如果是横着或者竖着的话其距离为d(i,j),如果是斜着对角线过来的则是 2d(i,j).其约束条件如下图像所示:

其中g(i,j)表示2个模板都从起始分量逐次匹配,已经到了M中的i分量和T中的j分量,并且匹配到此步是2个模板之间的距离。并且都是在前一次匹配的结果上加d(i,j)或者2d(i,j),然后取最小值。
所以我们将所有的匹配步骤标注后如下:

怎么得来的呢?比如说g(1,1)=4, 当然前提都假设是g(0,0)=0,就是说g(1,1)=g(0,0)+2d(1,1)=0+2*2=4.
g(2,2)=9是一样的道理。首先如果从g(1,2)来算的话是g(2,2)=g(1,2)+d(2,2)=5+4=9,因为是竖着上去的。
如果从g(2,1)来算的话是g(2,2)=g(2,1)+d(2,2)=7+4=11,因为是横着往右走的。
如果从g(1,1)来算的话,g(2,2)=g(1,1)+2*d(2,2)=4+2*4=12.因为是斜着过去的。
综上所述,取最小值为9. 所有g(2,2)=9.
当然在这之前要计算出g(1,1),g(2,1),g(1,2).因此计算g(I,j)也是有一定顺序的。
其基本顺序可以体现在如下:

计算了第一排,其中每一个红色的箭头表示最小值来源的那个方向。当计算了第二排后的结果如下:

最后都算完了的结果如下:

到此为止,我们已经得到了答案,即2个模板直接的距离为26. 我们还可以通过回溯找到最短距离的路径,通过箭头方向反推回去。如下所示:


注明:不管哪个方向,我都只加上了其本身的数值,即d(i j),没有x2.得出的路径是一样的。
PYTHON代码一个简单的例子
import numpy as np # We define two sequences x, y as numpy array # where y is actually a sub-sequence from x x = np.array([2, 0, 1, 1, 2, 4, 2, 1, 2, 0]).reshape(-1, 1) y = np.array([1, 1, 2, 4, 2, 1, 2, 0]).reshape(-1, 1) from dtw import dtw euclidean_norm = lambda x, y: np.abs(x - y) d, cost_matrix, acc_cost_matrix, path = dtw(x, y, dist=euclidean_norm) print(d) >>> 0.1111111111111111 # Only the cost for the insertions is kept # You can also visualise the accumulated cost and the shortest path import matplotlib.pyplot as plt plt.imshow(acc_cost_matrix.T, origin='lower', cmap='gray', interpolation='nearest') plt.plot(path[0], path[1], 'w') plt.show()

结果图中的白线,就是寻找到的两条曲线的最小距离,曲线的开始是直线,纵坐标的零点对应横坐标的0,和2点,说明对该处进行了拉伸。
DTW Barycenter Averaging (DBA)
DBA 是在DTW的基础上做重心平均,为什么这么做,因为往往我们需要比较的时间序列不是一条而是一个集合,所以通过把时间序列压缩成一条来进行比较
DBA代表动态时间扭曲重心平均。DBA是一种与动态时间扭曲一致的平均方法。下面给出一个时间序列集合的传统算术平均值与DBA之间的区别的例子。
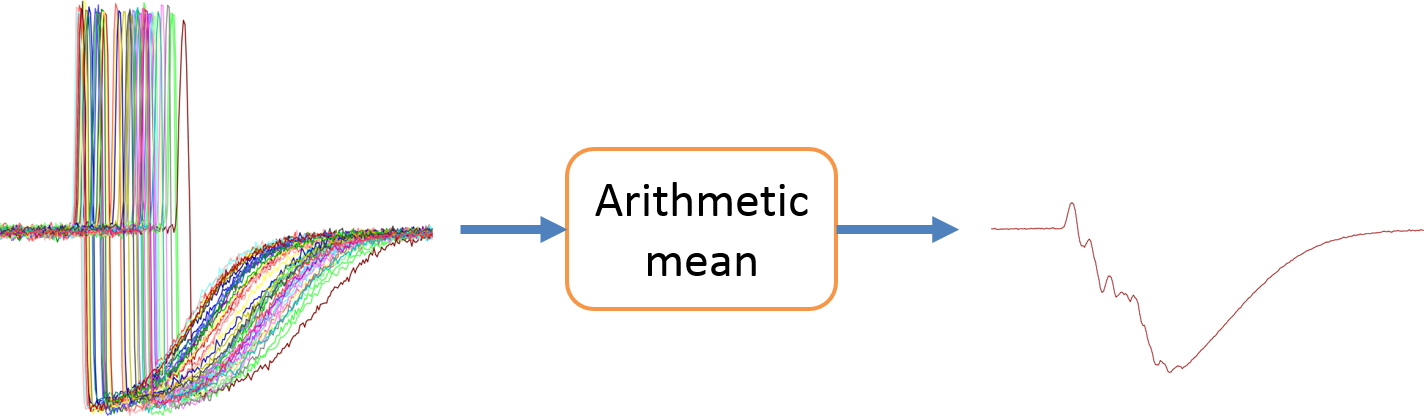
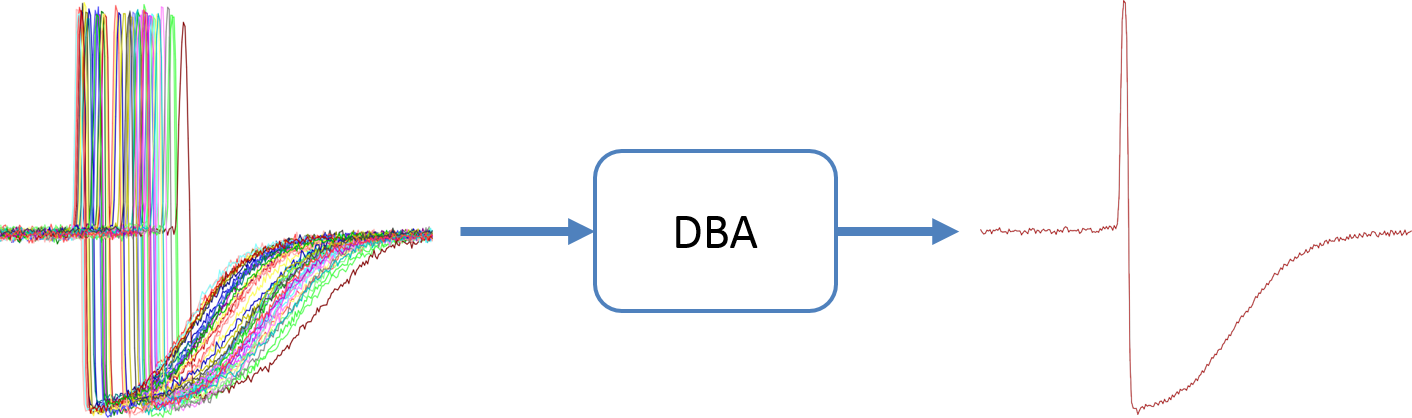
上图可知,DBA的结果要好于传统的求平均值结果。接下来介绍DBA算法,这个过程是一个迭代过程,每一次迭代都会执行以下两步。
(1) 计算每个单独时间序列与待细化的临时平均序列之间的DTW,为了找出平均序列的坐标与时间序列集合的坐标之间的关系(其实就是找相似性)。
(2)在第一步中,将平均序列的每个坐标更新为与之关联的重心坐标。
Let S = {S1, · · · , SN} 为要取平均值的时间序列集,
let C = (C1, . . . , CT )为迭代第 i 次和的平均序列
let C’ = (C1’…….,CT’) 为迭代i+1次对C集合的更新
我们要找到它的坐标。此外,平均序列的每个坐标都定义在任意向量空间E中(通常使用欧几里得距离)

我们假设一个函数assoc,它将平均序列的每个坐标与S序列的一个或多个坐标联系起来。这个函数是在计算C和S序列之间的DTW时计算出来的。然后定义 t 次平均序列 Ct’ 的坐标为

Where
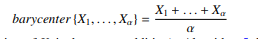
然后,通过再次计算平均序列与所有S序列之间的DTW,可以改变DTW产生的关联。由于无法预测这些关联将如何变化,我们建议让C迭代收敛。下图显示了四个迭代(即(四次更新),其中一个例子包含两个序列。
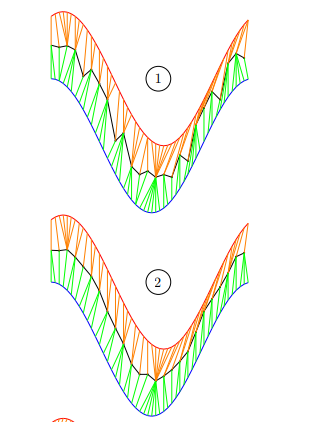
综上所述,本文提出的动态时间扭曲平均方法是一种全局方法,可以对一组序列进行平均。两个迭代之间的平均序列的更新与各个序列用于计算它们对所述更新的贡献的顺序无关。图3显示了一个使用DBA在[19]的一个数据集上计算平均序列的示例。这个图显示DBA保留了DTW的能力,可以识别时间的变化。

- Pattern Recognition 2011: A global averaging method for Dynamic Time Warping
Transfer learning for time series classification
这篇论文是讲把迁移学习的思想用到时间序列的训练上,最新颖的地方是使用DTW来比较两个时间序列的相似性。
如果遇到时间序列集,使用DAB来整合一个时间序列集为一条时间序列,再使用DTW来比较相识性。
选用到训练模型是一般的CNN(卷积神经网络),迁移的方法是,对于不同时间序列集通过修改最后一层的 softmax 实现迁移。
使用热力图来表示不同的数据集使用迁移学习的效果,有的不仅没有提高反而恶化,有的和没有使用迁移学习一样,有的有所提高。
说明了迁移学习对于相似的时间序列训练具有优势。
但是我觉得把迁移学习用于时间序列还是十分局限,条件也很多,两条时间序列相似的时候才会获得较好的效果,否则适得其反,会更加糟糕。
对于图片的迁移学习比较顺利,因为图片在抽象层中具有相似性,比较普遍,统一类图像就可以用迁移学习能获得很好的效果,而且已经存在训练好的模型VGG16,用于迁移学习十分方便,所以能不能训练一个通用的时间序列模型?
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/168395.html原文链接:https://javaforall.net


