
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
一、概述
Hadoop起源:hadoop的创始者是Doug Cutting,起源于Nutch项目,该项目是作者尝试构建的一个开源的Web搜索引擎。起初该项目遇到了阻碍,因为始终无法将计算分配给多台计算机。谷歌发表的关于GFS和MapReduce相关的论文给了作者启发,最终让Nutch可以在多台计算机上稳定的运行;后来雅虎对这项技术产生了很大的兴趣,并组建了团队开发,从Nutch中剥离出分布式计算模块命名为“Hadoop”。最终Hadoop在雅虎的帮助下能够真正的处理海量的Web数据。
Hadoop集群是一种分布式的计算平台,用来处理海量数据,它的两大核心组件分别是HDSF文件系统和分布式计算处理框架mapreduce。HDFS是分布式存储系统,其下的两个子项目分别是namenode和datanode;namenode管理着文件系统的命名空间包括元数据和datanode上数据块的位置,datanode在本地保存着真实的数据。它们都分别运行在独立的节点上。Mapreduce的两大子项目分别是jobtracker和tasktracker,jobtracker负责管理资源和分配任务,tasktracker负责执行来自jobtracker的任务。
Hadoop1升级成hadoop2后,为解决原来HDFS的namenode的单点故障问题,于是有了HA集群的出现;为解决原来mapreduce的jobtracker的单点故障以及负担过重的问题,于是有了mapreduce2也就是YARN的出现。
二、为什么需要hadoop?
在数据量很大的情况下,单机的处理能力无法胜任,必须采用分布式集群的方式进行处理,而用分布式集群的方式处理数据,实现的复杂度呈级数增加。所以,在海量数据处理的需求下,一个通用的分布式数据处理技术框架能大大降低应用开发难点和减少工作量。
三、对hadoop的理解简述
hadoop是用于处理(运算分析)海量数据的技术平台,并且是采用分布式集群的方式。
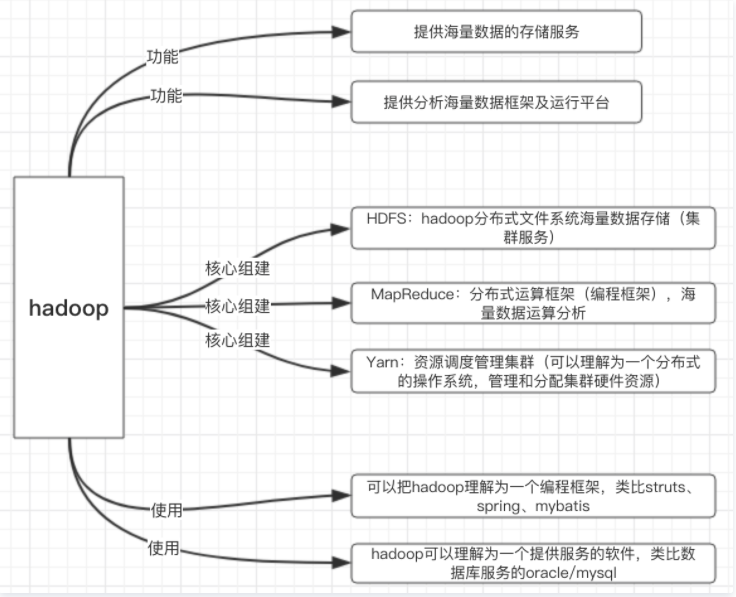

hadoop有两大功能:
1)提供海量数据的存储服务。
2)提供分析海量数据框架及运行平台。 关键词为存储、分析海量数据和运行平台。
四、hadoop三大核心组件
1)HDFS:hadoop分布式文件系统海量数据存储(集群服务)。
2)MapReduce:分布式运算框架(编程框架),海量数据运算分析。
3)Yarn:资源调度管理集群(可以理解为一个分布式的操作系统,管理和分配集群硬件资源)。
用MapReduce编写一个程序,到Yarn运行平台上去运行。
五、Hadoop技术生态圈的核心框架组件简介
1)ZooKeeper
Zookeeper是Hadoop生态圈中一个非常基础的服务框架,是各分布式框架公用的一个分布式协调服务系统。它通过为各类分布式框架提供状态数据的记录和监听,来让各类分布式系统的开发变得更加便捷。
2)Mahout
Mahout是一个开源的机器学习库,它能使Hadoop用户高效地进行诸如数据分析,数据挖掘以及集群等一些列操作。 Mahout对于大数据集特别高效,它提供的算法经过性能优化能够在HDFS文件系统上高效地运行MapReduce框架。
3)Ambari
Ambari提供一套基于网页的界面来管理和监控Hadoop集群。让Hadoop集群的部署和运维变得更加简单。它提供了一些列特性,诸如:安装向导,系统警告,集群管理,任务性能等。
4)Avro
如何用过其它编程语言来有效地组织Hadoop的大数据,Avro便是为了这个目的而生。Avro提供了各个节点上的数据的压缩以及存储。基于Avro的数据存储能够轻松地被很多脚本语言诸如Python,或者非脚本语言如Java来读取。另外,Avro还可被用来MapReduce框架中数据的序列化。
5)Sqoop
Sqoop被用来在各类传统的关系型数据库(比如MYSQL、ORACLE等数据库)和Hadoop生态体系中的各类分布式存储系统(比如HDFS、Hive、HBASE等)之间进行数据迁移。从而可以让开发人员快速地加载业务系统数据库中的数据到Hadoop中综合其他日志数据进行分析,并能方便地将分析结果导出到关系型数据库中以便查询分析和数据可视化。
6)Flume
Flume常被用来进行日志的采集、汇聚,它能从各类数据源中读取数据后汇聚到诸如HDFS、HBASE、Hive等各种类型的大型存储系统中。并且,在使用Flume时,用户几乎不用进行任何编程,只需要将数据源和汇聚存储系统的属性配置在Flume的配置文件中,即可快速搭建起一个大型分布式数据采集系统。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/181077.html原文链接:https://javaforall.net


