
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
文章目录
一、前置知识
在前一篇文章【云原生&微服务一】SpringCloud之Ribbon实现负载均衡详细案例(集成Eureka、Ribbon)我们讨论了SpringCloud如何集成Eureka和Ribbon,本文就在其基础上讨论一下如何自定义Ribbon的负载均衡策略、以及Ribbon的核心API。
二、Ribbon核心API
博主习惯性的在深入研究一门技术的时候去GitHub上看文档,然而Ribbon在GitHub上的文档(https://github.com/Netflix/ribbon)真的是没啥可看的;就给了一个demo和Release notes。
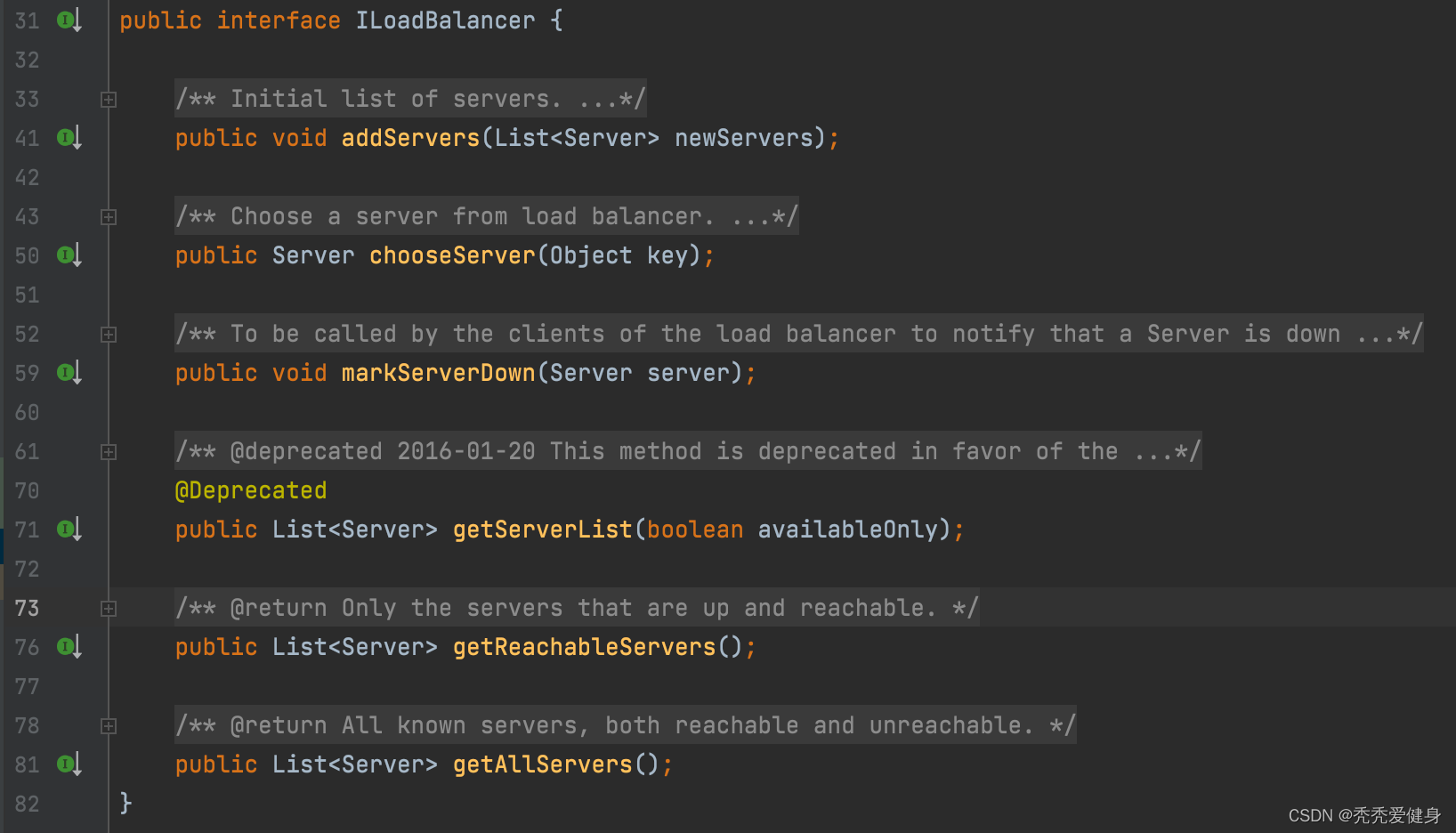
Ribbon有三个核心接口:ILoadBalancer、IRule、IPing,其中:
- ILoadBalancer是负载均衡器;
- IRule 复杂负载均衡的规则,ILoadBalancer根据其选择一个可用的Server服务器;
- IPing负责定时ping每个服务器,判断其是否存活。

三、自定义负载均衡策略IRule
1、编写IRule实现类
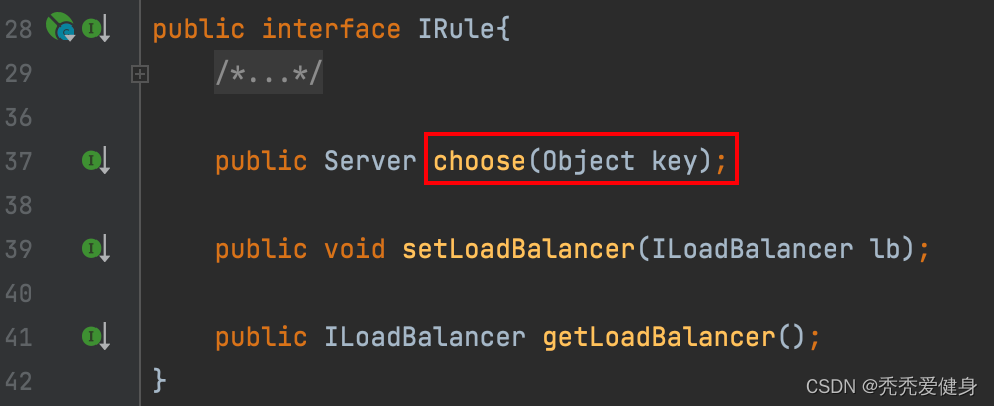
MyRule重写IRule的choose(Object o)方法,每次都访问List<Server>中第一个服务实例;
import com.netflix.loadbalancer.ILoadBalancer;
import com.netflix.loadbalancer.IRule;
import com.netflix.loadbalancer.Server;
import java.util.List;
/** * 自定义负载均衡规则,只用第一个实例; * * @author Saint */
public class MyRule implements IRule {
private ILoadBalancer loadBalancer;
@Override
public Server choose(Object o) {
final List<Server> allServers = this.loadBalancer.getAllServers();
return allServers.get(0);
}
@Override
public void setLoadBalancer(ILoadBalancer iLoadBalancer) {
this.loadBalancer = iLoadBalancer;
}
@Override
public ILoadBalancer getLoadBalancer() {
return loadBalancer;
}
}
注意:一般很少需要自己定制负载均衡算法的,除非是类似hash分发的那种场景,可以自己写个自定义的Rule,比如说,每次都根据某个请求参数,分发到某台机器上去。不过在分布式系统中,尽量减少这种需要hash分发的情况。
下面我接着看如何把自定义的MyRule应用到指定的服务上 或 全部服务上。
2、编写Ribbon配置类
在Ribbon配置类中通过@Bean注解将自定义的IRule实现类MyRule注入到Spring容器中。
import com.netflix.loadbalancer.IRule;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/** * 自定义Ribbon配置 * * @author Saint */
@Configuration
public class MyRibbonConfiguration {
@Bean
public IRule getRule() {
return new MyRule();
}
}
3、应用到全部服务上(Ribbon全局配置)
Ribbon全局配置有两种方式:一种是依赖Spring的自动扫描、一种是依赖@RibbonClients注解。
1)Spring的自动扫描
所谓Spring的自动扫描,就是将自定义的Ribbon配置类放在Spring容器可以扫描到的包目录下即可。
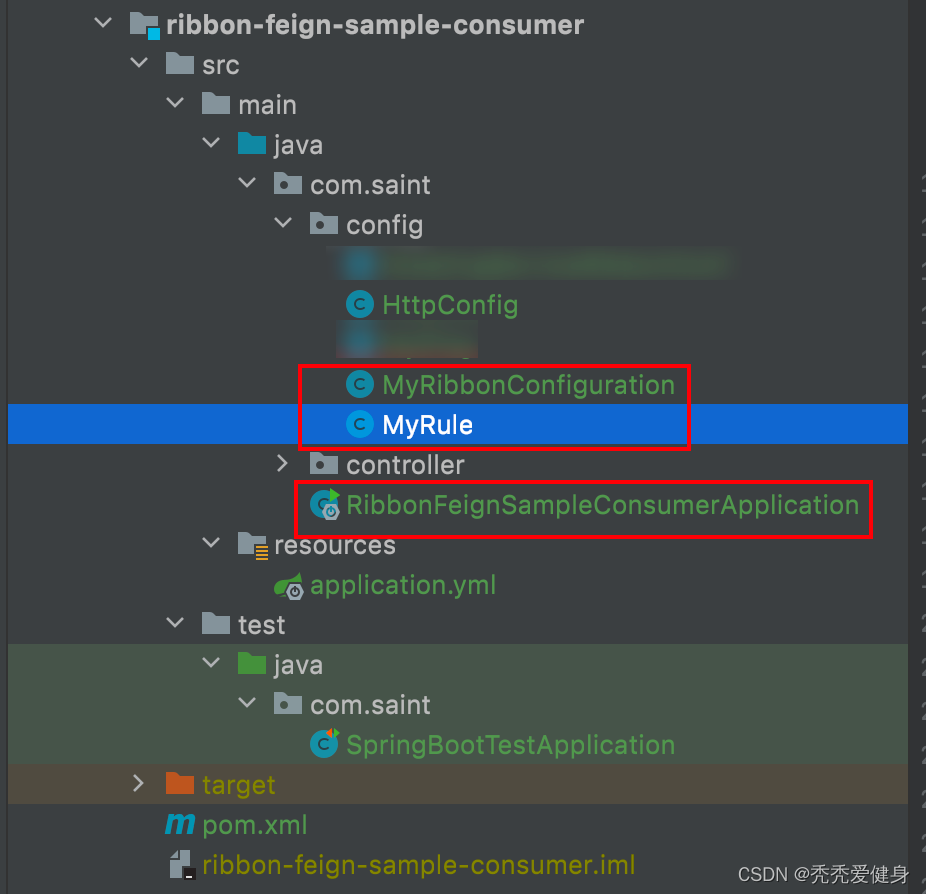

如上图所示,程序的启动类RibbonFeignSampleConsumerApplication所在的目录为com.saint,Ribbon配置类MyRibbonConfiguration 所在的目录为com.saint.config;又因没有指定包扫描的路径,所以目录会扫描启动类所在的包com.saint,因此Spring可以自动扫描到MyRibbonConfiguration、进而扫描到MyRule。
注意:Ribbon的配置类一定不能Spring扫描到。因为Ribbon有自己的子上下文,Spring的父上下文如果和Ribbon的子上下文重叠,会有各种各样的问题。比如:Spring和SpringMVC父子上下文重叠会导致事务不生效。
所以不推荐使用这种方式。
2)@RibbonClients注解
在启动类所在目录的父目录(com.saint)中新建config文件夹(com.config),并将MyRibbonConfiguration类移动到其中,代码目录结构如下:
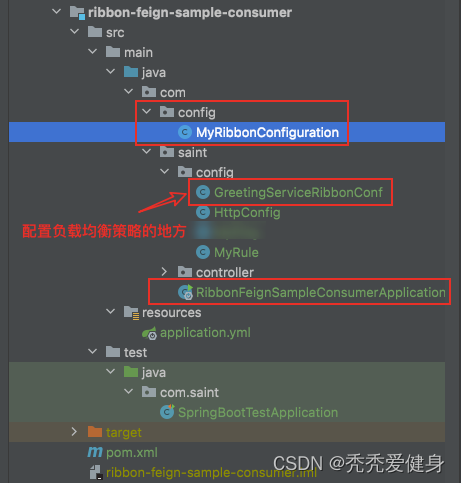
这样操作之后,Ribbon配置类讲不会被Spring扫描到。所以需要利用@RibbonClients注解做一些配置;
在com.saint.config目录下新增GreetingServiceRibbonConf类:
package com.saint.config;
import com.config.MyRibbonConfiguration;
import org.springframework.cloud.netflix.ribbon.RibbonClients;
import org.springframework.context.annotation.Configuration;
/** * @author Saint */
@Configuration
@RibbonClients(defaultConfiguration = MyRibbonConfiguration.class)
public class GreetingServiceRibbonConf {
}
3、应用到指定服务上(Ribbon局部配置)
针对Ribbon局部配置,有两种方式:代码配置 和 属性配置,上面提到的@RibbonClients就属于代码配置的方式,区别在于Ribbon局部配置使用的是@RibbonClient注解;
1)代码配置 – @RibbonClient
将GreetingServiceRibbonConf类的内容修改如下:
package com.saint.config;
import com.config.MyRibbonConfiguration;
import org.springframework.cloud.netflix.ribbon.RibbonClient;
import org.springframework.context.annotation.Configuration;
/** * 自定义 调用greeting-service服务时 使用的配置 * * @author Saint */
@Configuration
@RibbonClient(name = "GREETING-SERVICE", configuration = MyRibbonConfiguration.class)
public class GreetingServiceRibbonConf {
}
当然我们也可以不使用GreetingServiceRibbonConf作为一个配置类,直接将@RibbonClient(name = "GREETING-SERVICE", configuration = MyRibbonConfiguration.class)加在启动类中也是一样的。
2)属性配置 – application.yml
首先将GreetingServiceRibbonConf类中的内容全部注释掉:
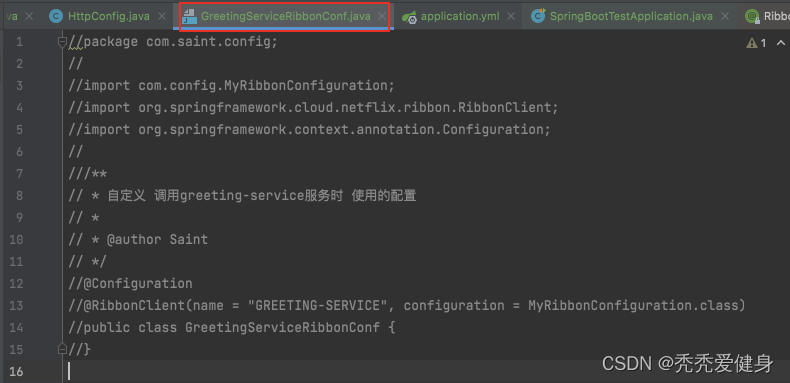
然后在application.yml文件中添加如下内容:
# GREETING-SERVICE为要调用的微服务名
GREETING-SERVICE:
ribbon:
NFLoadBalancerRuleClassName: com.saint.config.MyRule
3)两种方式对比:
- 代码配置:基于代码、更加灵活;但是线上修改得重新打包、发布,并且还有小坑(父子上下文问题)
- 属性配置: 配置更加直观、优先级更高(相对代码配置)、线上修改无需重新打包、发布;但是极端场景下没有代码配置方式灵活。
注意:如果代码配置和属性配置两种方式混用,属性配置优先级更高。
4)细粒度配置-最佳实践:
- 尽量使用属性配置,属性方式实现不了的情况下再考虑代码配置。
- 同一个微服务内尽量保持单一性,使用同样的配置方式,避免两种方式混用,增加定位代码的复杂性。
4、使用浏览器进行调用服务消费者
结合博文:【云原生&微服务一】SpringCloud之Ribbon实现负载均衡详细案例(集成Eureka、Ribbon),我们已经依次启动了eureka-server、ribbon-feign-sample-8081、ribbon-feign-sample-8082、ribbon-feign-sample-consumer;三个服务、四个实例。
此处我们针对服务消费者ribbon-feign-sample-consumer做四次接口调用,分别为:
- http://localhost:9090/say/saint
- http://localhost:9090/say/saint2
- http://localhost:9090/say/saint3
- http://localhost:9090/say/saint4
然后我们去看ribbon-feign-sample-8081、ribbon-feign-sample-8082的控制台输出:
1> ribbon-feign-sample-8081控制台输出:
2> ribbon-feign-sample-8082控制台输出:
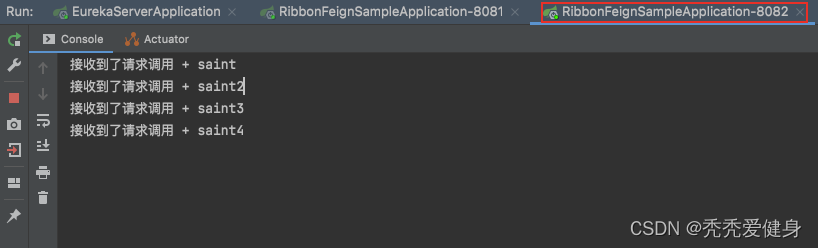
3> 结果说明:
我们可以发现,四个请求,ribbon-feign-sample-8082实例处理了所有的请求,我们自定义的IRule已经生效。
四、自定义服务实例是否存活判定策略IPing
和IRule的自定义方式一样,这里只提供自定义的IPing,具体配置方式和IRule一样。
1、自定义IPing
MyPing表示实例永不失活,因为其isAlive(Server server)永远返回TRUE。
package com.saint.config;
import com.netflix.loadbalancer.IPing;
import com.netflix.loadbalancer.Server;
/** * 自定义IPing,判断每个服务是否还存活 * @author Saint */
public class MyPing implements IPing {
@Override
public boolean isAlive(Server server) {
return true;
}
}
2、修改Ribbon配置类
package com.config;
import com.netflix.loadbalancer.IPing;
import com.netflix.loadbalancer.IRule;
import com.saint.config.MyPing;
import com.saint.config.MyRule;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/** * 自定义Ribbon配置 * * @author Saint */
@Configuration
public class MyRibbonConfiguration {
@Bean
public IRule getRule() {
return new MyRule();
}
@Bean
public IPing getPing() {
return new MyPing();
}
}
五、性能优化-饥饿加载
Ribbon默认是懒加载微服务,所以第一次调用特别慢,我们可以修改饥饿加载。
ribbon:
eager-load:
# 开启饥饿加载
enabled: true
# 开启饥饿加载的微服务列表,多个以,分隔
clients: user-center,xxx
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/182333.html原文链接:https://javaforall.net


