
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
使用Python爬取简单数据
闲暇时间学习Python,不管以后能否使用,就算了解计算机语言知识。
因为有一点Java基础,所以Python的基本语法就很快的过了一遍,表达或许有点混乱,以后慢慢改进。
一、导入爬取网页所需的包。
from bs4 import BeautifulSoup #网页解析
import xlwt #excel
import re #正则表达式
import urllib.request,urllib.error #指定url,获取网页数据
二、Python属于脚本语言,没有类似Java的主入口(main),对于这里理解不是很深,就是给这个类添加一个主入口的意思吧。
if __name__ == '__main__':
main()
三、接着在定义主函数main(),主函数里应包括
- 所需爬取的网页地址
- 得到网页数据,进行解析舍取
- 将得到的数据保存在excel中
def main():
#指定所需爬取网页路径
basePath = "https://www.duquanben.com/"
#获取路径
dataList = getData(basePath)
#保存数据
saveData(dataList)
四、需对爬取网页进行数据的采集
- 因为使用的Pycharm软件来进行爬取,首先需要进行下伪装,将浏览器的代理信息取出
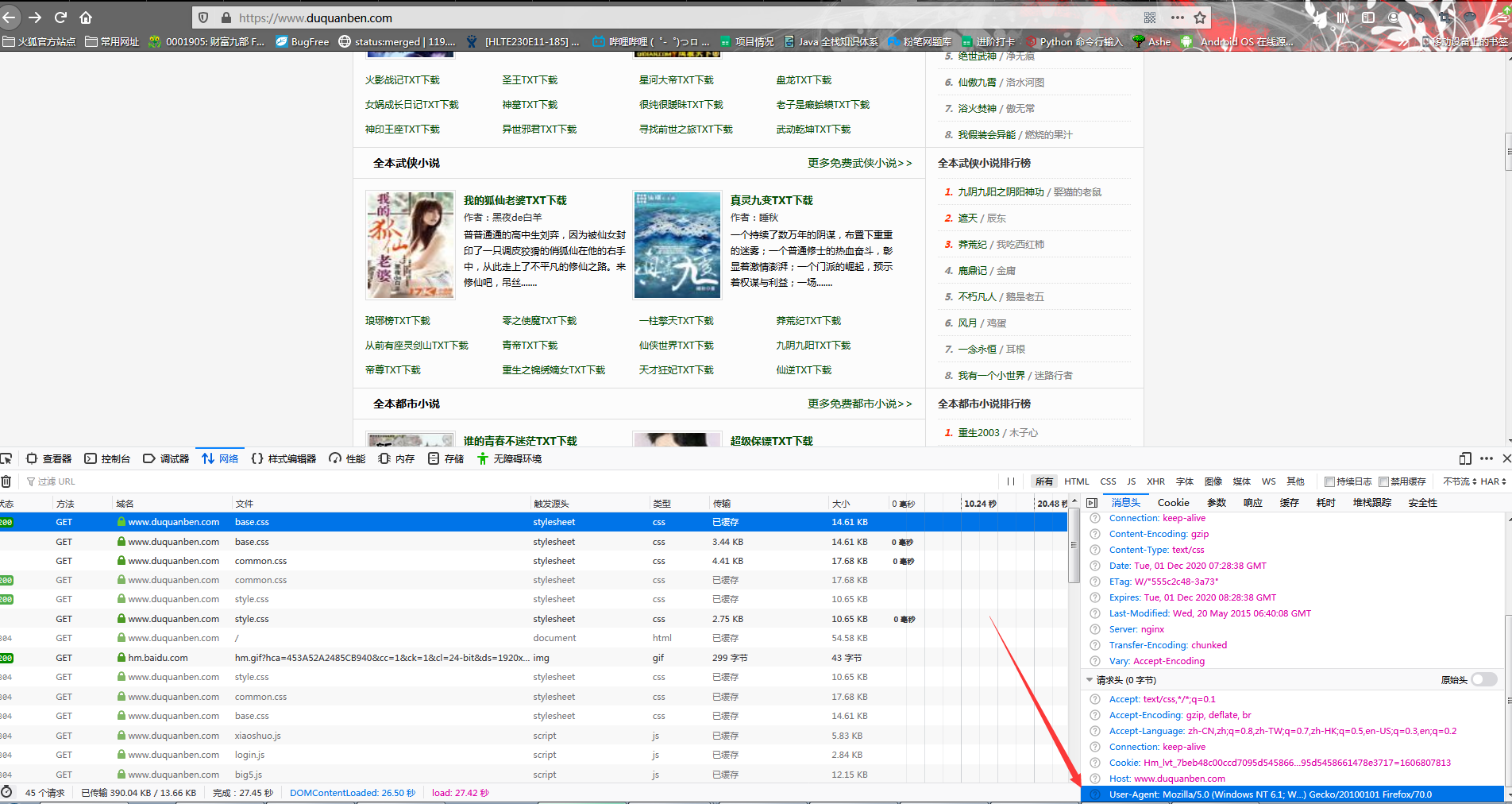
 待解析网页数据时,使用此信息进行伪装
待解析网页数据时,使用此信息进行伪装
五、定义获取数据方法
- 进入网页取数据,需得到网页认可(解析网页)
def getData(basePath):
#解析数据
html = uskURL(basePath)
- uskURL方法有点类似于死方法,根据浏览器的不同,改变下用户代理人信息即可
def uskURL(basePath):
heard = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0" #伪装为浏览器
}
req=urllib.request.Request(basePath,headers=heard,method="GET")
html = ""
try:
response=urllib.request.urlopen(req)
html = response.read()
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
3、准备集合装载数据,解析网页数据,匹对正则表达式
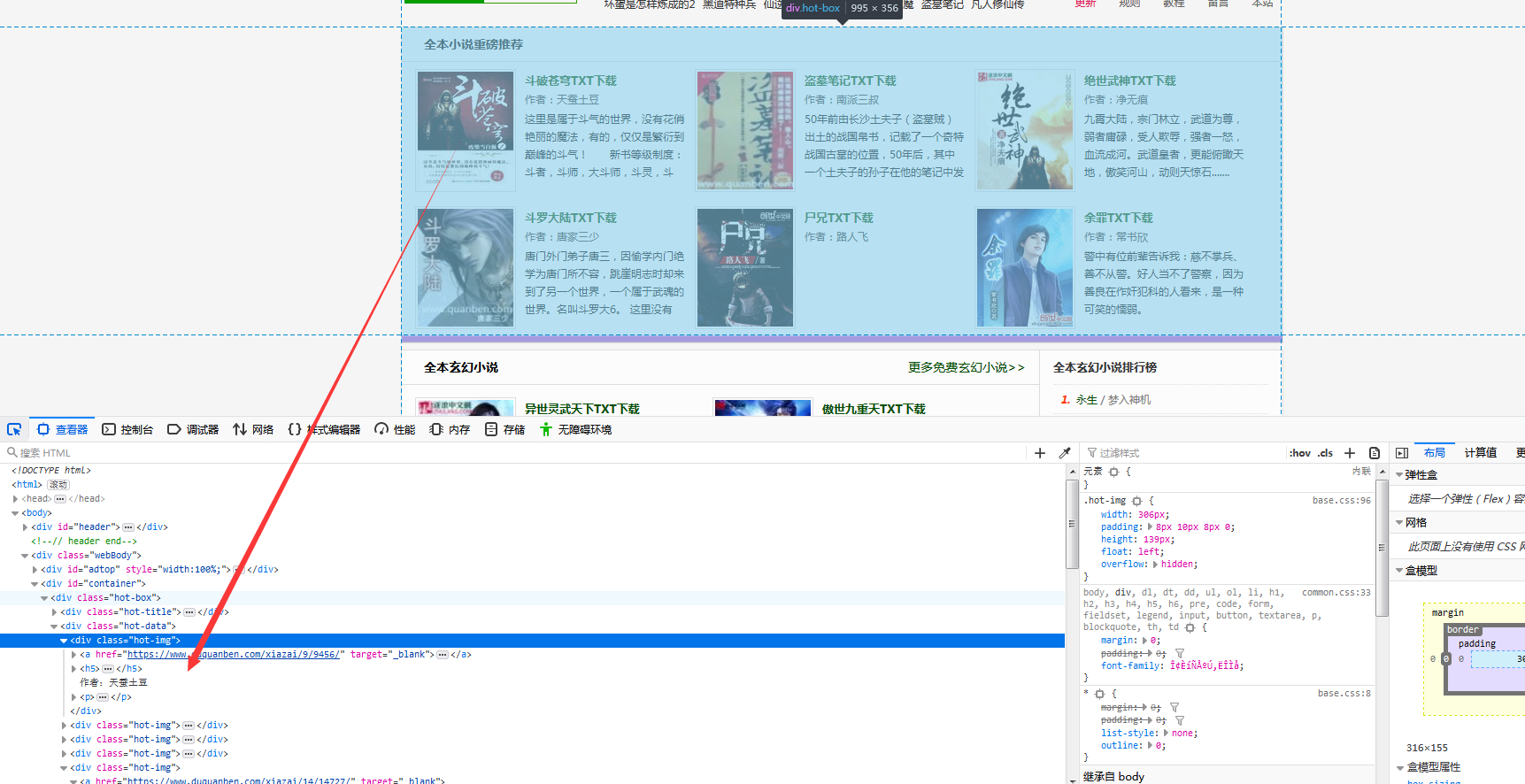 可以看出爬取的数据由
可以看出爬取的数据由
标签包裹,所以只需遍历循环此标签即可。
#正则表达式定义为全局变量
link = re.compile(r'<h5><a href="(.*)" target="_blank">')
author = re.compile(r'作者:(.*)')
content = re.compile(r'<p><a href="(.*)" target="_blank">(.*?)</a></p>',re.S) #re.S表示忽略换行符等
def getData(basePath):
#解析数据
html = uskURL(basePath)
#解析网页数据
bs = BeautifulSoup(html,"html.parser")
#t_list=bs.find_all("div",class_="hot-img") #因为class是一个类别,所以需要加一个下划线,不然会报错<div class="hot-img">
#print(t_list)
# 装数据的集合
datalist = []
for item in bs.find_all("div",class_="hot-img"):
data = [] #另准备一个集合装取数据
item = str(item) #转化为字符串
linklist = re.findall(link, item) #findall(1,2)1表示正则表达式,2表示所要匹对的字符串
#print(linklist)
data.append(linklist)
authorlist = re.findall(author,item)
data.append(authorlist)
#print(authorlist)
contentlist = re.findall(content,item)[0][1] #contentlist里我们只需要第二个数据,将他看作为二维数组,后面对应取值即可
if contentlist == "": #无字符串时,根据自己想法而定
data.append("暂无简介")
else:
data.append(contentlist)
datalist.append(data)
#print(datalist)
return datalist
六、将得到的数据保存在excel中
def saveData(dataList):
Book=xlwt.Workbook(encoding="utf-8",style_compression=0)#style_compression:表示是否压缩,不常用
sheet=Book.add_sheet("小说.xls",cell_overwrite_ok=True)#cell_overwrite_ok,表示是否可以覆盖单元格
line = ("详情链接","笔名","简介")
for item in range(len(line)): #此处循环如果line里只有一个字符串,那么生成的xls里,只会出现一个‘详’字
#print(len(line))
sheet.write(0,item,line[item])#wirte(row, col, *args)
for i in range(len(dataList)):#第一次循环应是将行数,有多少数据有多少行
data=dataList[i] #每一条数据应该放在一行里,所以将在一次进行for循环
for j in range(len(line)):
sheet.write(i+1,j,data[j])
Book.save("测试.xls")
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/182486.html原文链接:https://javaforall.net


