
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
引言
之所以谈到布隆过滤器主要是因为以前工作中用到redis,为了防止缓冲穿透而使用了布隆过滤器(BloomFilter)。这次温故而知新,再深入学习它的原理,顺带提提它的其他用途。
1、简介
简单来说,布隆过滤器(BloomFilter)是一种数据结构。特点是存在性检测,如果布隆过滤器中不存在,那么实际数据一定不存在;如果布隆过滤器中存在,实际数据不一定存在。相比于传统数据结构(如:List、Set、Map等)来说,它更高效,占用空间更少。缺点是它对于存在的判断是具有概率性。
2、实现原理
在谈到原理之前,我们先来看看布隆过滤器的数据结构,它是一个bit数组。如下图所示:
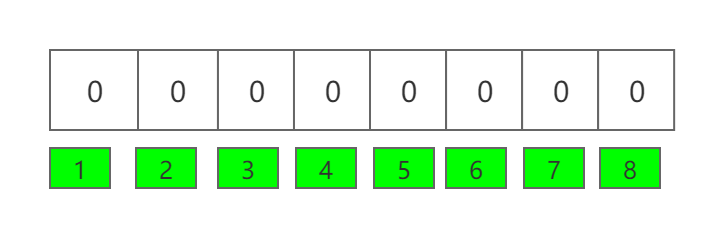

这是一个长度为8,默认都是0的bit数组。如果我们想要映射一个值到布隆过滤器中,怎么操作呢?首先是使用多个不同的哈希函数生成多个哈希值,再把哈希值指向的bit位置1。例如:我们要将值“baidu”映射到布隆过滤器上,怎么操作呢?假如我们使用三个不同的哈希函数生成了三个哈希值分别是:1、3、6,那么上图就转变为下图这样:
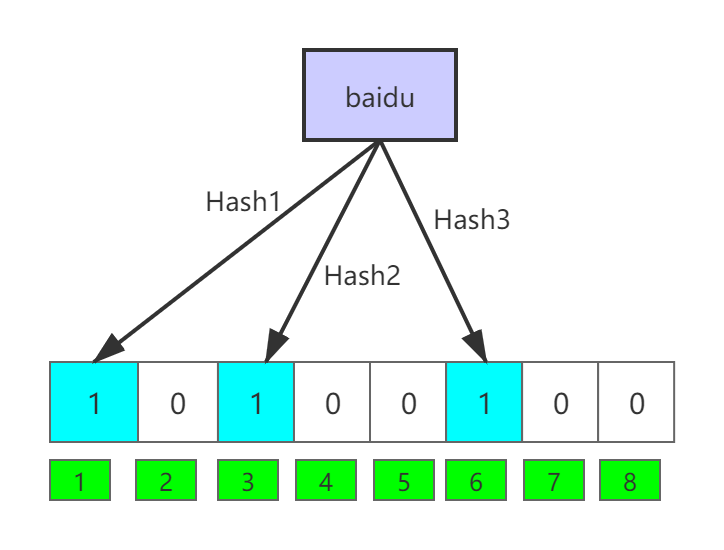
从图中看出,标有浅蓝色的bit位的值都被置为1,表示该数据已经映射上了。接着我们再把值“alibaba”和三个不同哈希函数生成的值:2、6、8映射到上面布隆过滤器中,它就会变为下图的样子:

很显然,它把之前映射的哈希值6覆盖了,这就是布隆过滤器是有误报率的一个因素。如果这时候,我们想拿一个未插入映射的值“tencent”查询它是否在上面布隆过滤器中存在。该怎么操作呢?首先,把值“tencent”用上面三个不同哈希函数生成三个哈希值分别是:2、4、6;再去布隆过滤器上找这三个值对应的bit位的值是否都是1,我们发现2和6都返回了1,而4返回0,说明值“tencent”没有做过映射,即不存在。实际上我们并没有事先做过此值的插入映射操作。这当然是正确的。
-
为什么说,如果布隆过滤器中存在,实际数据不一定存在呢?
这里回答一个小问题,为什么说,一个值如果在布隆过滤器中存在,实际数据不一定存在呢?拿上图为例,我们先后分别插入了“baidu”和“tencent”的哈希映射。现在如果我们再拿“baidu”这个值查询是否存在,我们使用三个不同哈希函数生成哈希值分别是:1、3、6,跟之前映射时生成的哈希值是一样的。当然这个结果是必然的。接下来,我们发现这三个bit位的值都是1,但是,我们不能说“baidu”是存在的。为什么呢?因为随着增加的值越来越多,bit位被置为1的位数也越来越多。这样即使某个值,比如:“meituan”没有做过存储,但是它的哈希值对应的bit位正好被其他值置为1了,虽然出现这种情况的概率很低,但实际不能排除有这种可能性。所以说,一个值如果在布隆过滤器中存在,实际数据是不一定存在。
接着上面的话题继续说,很显然,长度过小的布隆过滤器很快所有的bit位都被置为1了,查询任意值都会返回“可能存在”的,这样就起不到过滤的目的。说明,布隆过滤器的长度越小,其误报率就越高,布隆过滤器的长度越长,误报率越低。
接下来再看看哈希函数的个数是否对误报率有影响。如果哈希函数的个数越多,那么bit位会迅速填满,也就是布隆过滤器bit位置为1的速度会加快,且布隆过滤器的效率越低。换句话说,如果哈希函数的个数越多,布隆过滤器bit位置为1的速度就越快,且效率就会越低;如果哈希函数个数越少,bit位置为1的速度就越慢,但是误报率就越高了。很显然,布隆过滤器的长度,哈希函数的个数,误报率以及插入元素的个数4者之间存在着某种关系,可能是线性关系。到底存在怎么样的关系呢?直接上公式:
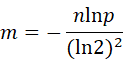
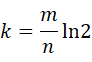
上面两个公式中,斜体字母m,n,p,k分别代表,m为布隆过滤器长度,n为插入的元素个数,k为哈希函数个数,p为误报率。这样,有了上面两个公式就可以方便选择哈希函数的个数和布隆过滤器的长度了。至于如何推导这两个公式,我将会在后续文章中写到,欢迎继续关注。
3、布隆过滤器为什么可以防止缓冲穿透
解答这个问题前,先来看看缓冲穿透是怎么回事。百度百科给的概念是:“缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,进而给数据库带来压力。”,由此可见,缓冲穿透的特点是访问查询的数据一定在缓冲和数据库中都不存在。而一般在数据库存在的数据会通过配置自动同步或更新到缓存中,如果数据库中不存在的数据,那么就不会同步到缓存中,自然缓存中也不存在。反过来说,缓存中不存在的数据,数据库中肯定不存在。所以,当这样不存在的数据到达缓存层经过不存在的过滤,并及时返回结果,这样的数据自然也不会到达数据库的。布隆过滤器虽然对存在数据的过滤具有误报率的缺点,但是对数据做不存在的过滤是100%准确的。所以布隆过滤器可以防止缓存穿透。而且前面简介中提到了它的优点是高效,占用空间更少。尤其针对上亿级数据,在高并发场景下,,它的性能更优。
实现布隆过滤器常用google guava框架,在后续的博文中我会专门讲解,欢迎持续关注。
参考资料
https://zhuanlan.zhihu.com/p/43263751
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/185094.html原文链接:https://javaforall.net


