
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
这是云从大佬在CVPR上的一篇paper。基本思想就是通过对global feature进行多粒度的切分,提取更局部的细节特征。当时在Market-1501,CUHK03,DukeMTMC-reID三个数据集刷新了SOTA纪录,其中最高在Market-1501上的首位命中率(Rank-1 Accuracy)达到96.6%,让(ReID)在准确率上首次达到商用水平,很大程度上可以说是推动了整个reid行业的发展。
论文:https://arxiv.org/pdf/1804.01438.pdf
GitHub:https://github.com/xr-Yang/MGN-Pytorch
看完整个paper想说点关于自己的想法:MGN是对global feature进行了1,2,3层的切分,开启了大家对多粒度attention的思考,那么借鉴这个思想,我们很自然的会想到如果对global feature切得更细,比如对global切1,2,3,4层分别送loss效果会不会进一步提升,对local feature的提取是不是会更好。
目前我们组内有尝试这部分的工作,通过对MGN的改进,将global feature进行更细粒度的切分,并且使用上下local feature的协同机制,得到的比MGN更好的效果,相关detail可以看我的另一篇:《Collaborative Attention Network for Person Re-identification》
OK,我们回到MGN。
MGN的主要思想就是通过区域分割,来获得不同粒度的特征,比如全局和局部特征以及更细粒度的局部特征,通过一个网络的不同分支得到这些特征,每个分支都对不同的分割块进行特征提取。
论文提出通过融合行人的全局信息以及具有辨识力的多粒度局部信息的思路,为解决ReID问题提供了一个非常不错的思路。
(1)结构精巧:该方案实现了端到端的直接学习,并没有增加额外的训练流程;
(2)多粒度:融合了行人的整体信息与有区分度的多粒度细节信息;
(3)关注细节:模型真正懂得什么是人,模型会把注意力放在膝盖,衣服商标等能够显著区分行人的一些核心信息上。
难点:
ReID技术与人脸识别技术类似,存在较多的困难点需要克服,例如光线、遮挡、图片模糊等客观因素。另外,行人的穿着多样,同一人穿不同的衣服,不同的人穿相似的衣服等等也对ReID技术提出更高的要求。行人的姿态多变导致人脸上广泛使用的对齐技术也在ReID失效。行人的数据获取难度远远大于人脸识别数据获取难度,而行人的信息复杂程度又远远大于人脸,这两个因素叠加在一起使得ReID的算法研究变得更加困难,也更加重要。通过算法的有效设计,降低对数据依赖来实现ReID效果的突破是现在业内的共识。
Introduction
从不同的安防摄像机采集到的大批行人图像中检索出给定的行人是行人重识别一个极具挑战性的任务。由于监控视频图像的场景复杂性,person -ReID的主要挑战来自于人的较大变化诸如姿势、遮挡、衣服、背景混乱,检测失败等。深度卷积网络的蓬勃发展,对行人图像的识别和鲁棒性提出了更为强大的表现形式,将RID的性能提升到了一个新的水平。近几个月来,一些深层次的RID方法(3, 37, 32,25)取得了突破性的高识别率和平均平均精度。
结合全局与局部特征是提高提取行人关键可分辨信息的重要方法。之前的局部特征提取的方法专注在基于位置的显著信息提取,导致训练难度提高,同时在复杂场景的鲁棒性并不尽如人意。而作者新设计了一个多分支的端到端的深度网络,使得不同级别的网络分支能够关注不同粒度的分辨信息,也能够有效兼顾整体信息。损失函数部分,作者表示为了充分体现网络的真实潜力,该文章中只使用了在深度学习中非常常见的Softmax Loss与Triplet Loss。


多粒度的解析如图所示,从左到右是人体部分从粗粒度到精细粒度的过程。左边三张是完整的行人图片,中间是将行人图片分割为上下两部分,最有右边是将行人图片分成上中下三个部分。
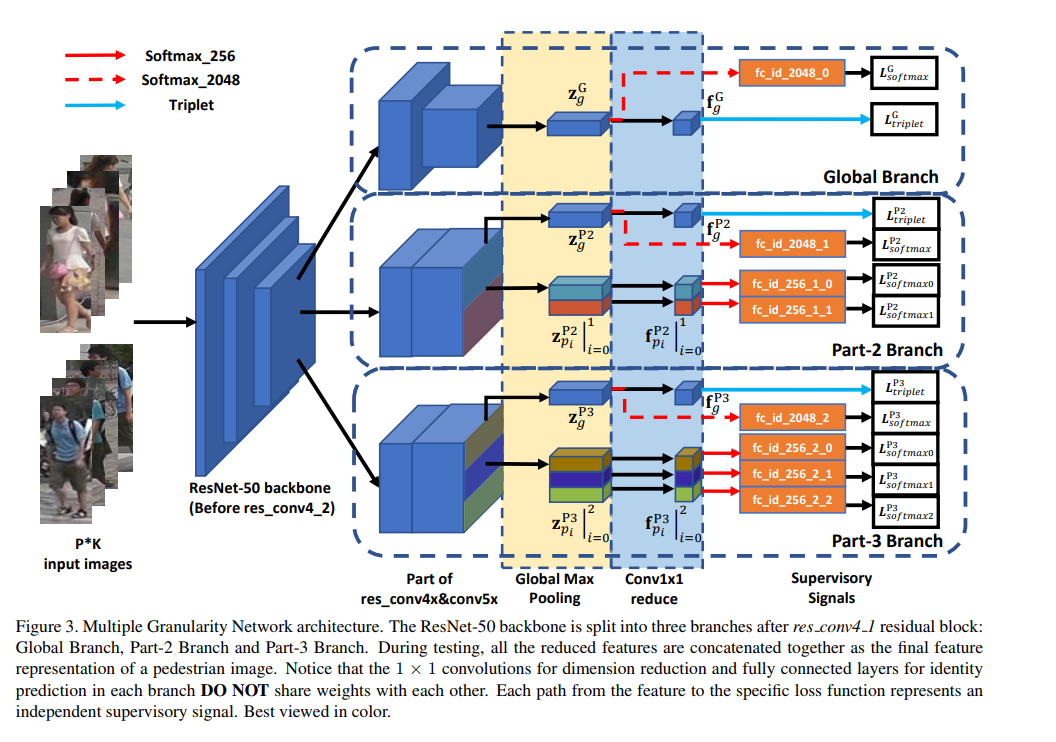
多粒度网络(Multiple Granularity Network,MGN)如上图所示,该结构的基础网络部分采用业内最为常用的Resnet50。根据对Resnet50网络以及跨镜追踪的深刻分析,作者创新性地对Resnet50进行了合理的修改,使用Resnet50前三层提取图像的基础特征,而在高层次的语意级特征作者设计了3个独立分支。如图所示,第一个分支负责整张图片的全局信息提取,第二个分支会将图片分为上下两个部分提取中粒度的语意信息,第三个分支会将图片分为上中下三个部分提取更细粒度的信息。这三个分支既有合作又有分工,前三个低层权重共享,后面的高级层权重独立,这样就能够像人类认知事物的原理一样即可以看到行人的整体信息与又可以兼顾到多粒度的局部信息。
同时文章对损失函数部分也进行了精心而巧妙的设计。三个分支最后一层特征都会进行一次全局MaxPooling操作,而第二分支与第三分支还会分别再进行局部的MaxPooling,然后再将特征由2048维降为256维。最后256维特征同时用于Softmax Loss与Triplet Loss计算。另外,作者在2048维的地方添加一个额外的全局Softmax Loss,该任务将帮助网络更全面学习图片全局特征。
而在测试的时候只需使用使用256维特征作为该行人的特征进行比较,无需使用2048维的特征,使用欧氏距离作为两个行人相似度的度量。
正是这样简约的设计,使得整个网络对行人完成由粗粒度特征到精细粒度特征的理解。
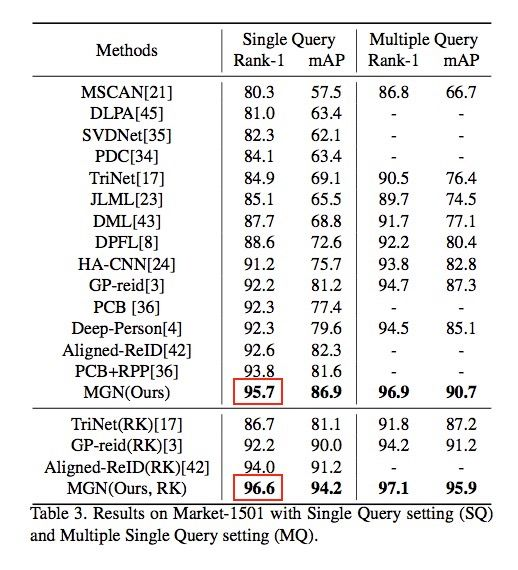
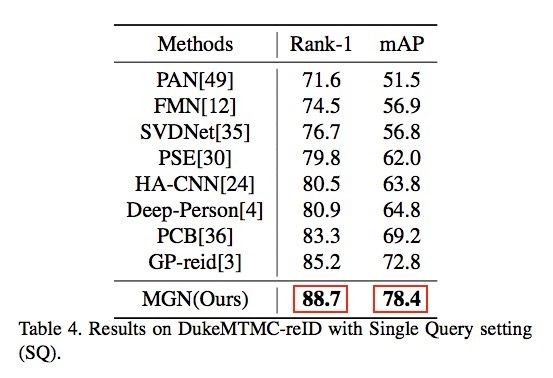
作者最后使用Re-Ranking技术对结果进行处理。需要着重强调的是文章的数据显示,本方法在Market-1501的Rank1数值即使在没有使用Re-Ranking技术的情况下已达到95.7%,这个结果已经超越了当时其他方案使用Re-Ranking技术后的结果。另外MGN的所有结果都是根据每个数据集官方提供的训练数据以及评测方法进行,并没有做数据扩充或者将多个数据集融合训练。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/185586.html原文链接:https://javaforall.net

![phpstrom2021.5 激活码[在线序列号]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
