
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
权重的维度保持为 2 的幂
即便是运行最先进的深度学习模型,使用最新、最强大的计算硬件,内存管理仍然在字节(byte)级别上进行。所以,把参数保持在 64, 128, 512, 1024 等 2 的次方永远是件好事。这也许能帮助分割矩阵和权重,导致学习效率的提升。当用 GPU 运算,这变得更明显。
权重初始化 (Weight Initialization)
永远用小的随机数字初始化权重,以打破不同单元间的对称性(symmetry)。但权重应该是多小呢?推荐的上限是多少?用什么概率分布产生随机数字?
当使用 Sigmoid 激励函数时,如果权重初始化为很大的数字,那么 sigmoid 会饱和(尾部区域),导致死神经元(dead neurons)。如果权重特别小,梯度也会很小。因此,最好是在中间区域选择权重,比如说那些围绕平均值均衡分布的数值。
参数初始化应该使得各层激活值不会出现饱和现象且激活值不为0。我们把这两个条件总结为参数初始化条件:
初始化必要条件一:各层激活值不会出现饱和现象。
初始化必要条件二:各层激活值不为0。
tensorflow几种普通的参数初始化方法
1. tf.constant_initializer() 常数初始化
2. tf.ones_initializer() 全1初始化
3. tf.zeros_initializer() 全0初始化
4. tf.random_uniform_initializer() 均匀分布初始化
5. tf.random_normal_initializer() 正态分布初始化
6. tf.truncated_normal_initializer() 截断正态分布初始化
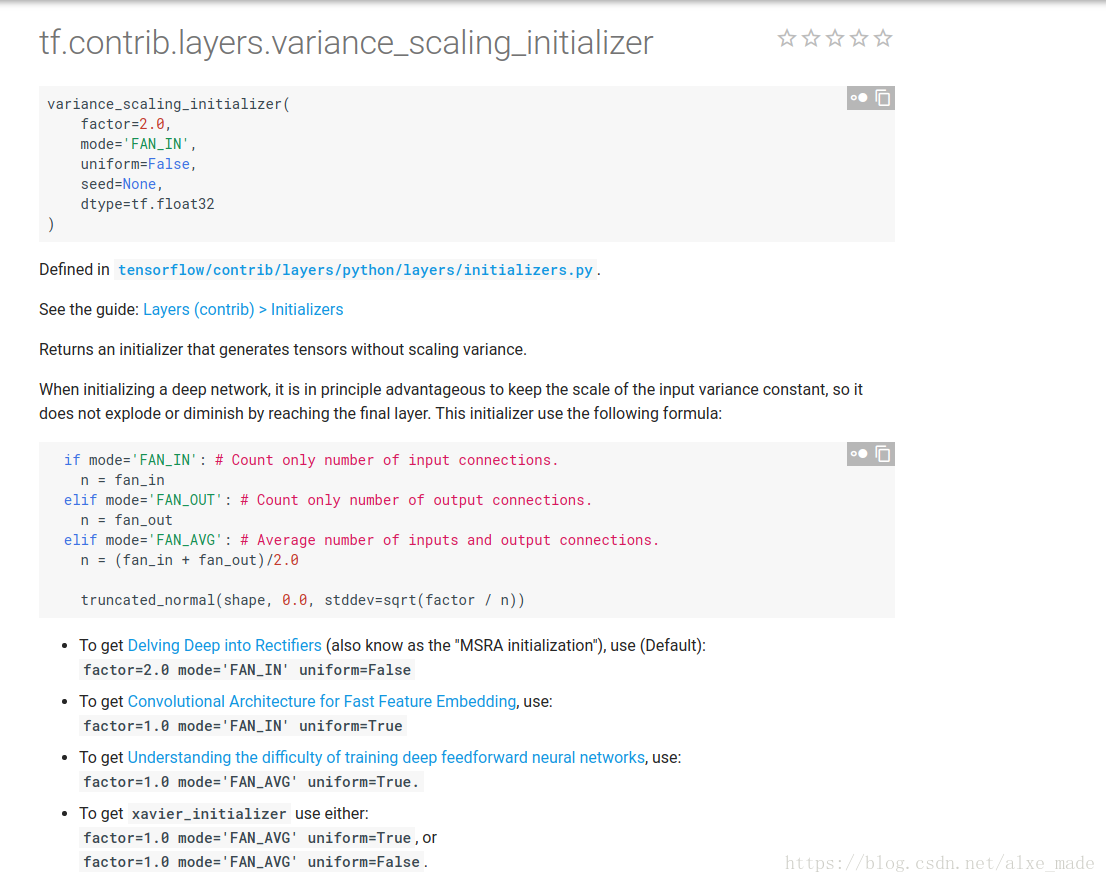
7. tf.uniform_unit_scaling_initializer() 这种方法输入方差是常数
8. tf.variance_scaling_initializer() 自适应初始化
9. tf.orthogonal_initializer() 生成正交矩阵
Xavier初始化和 MSRA初始化(He初始化)
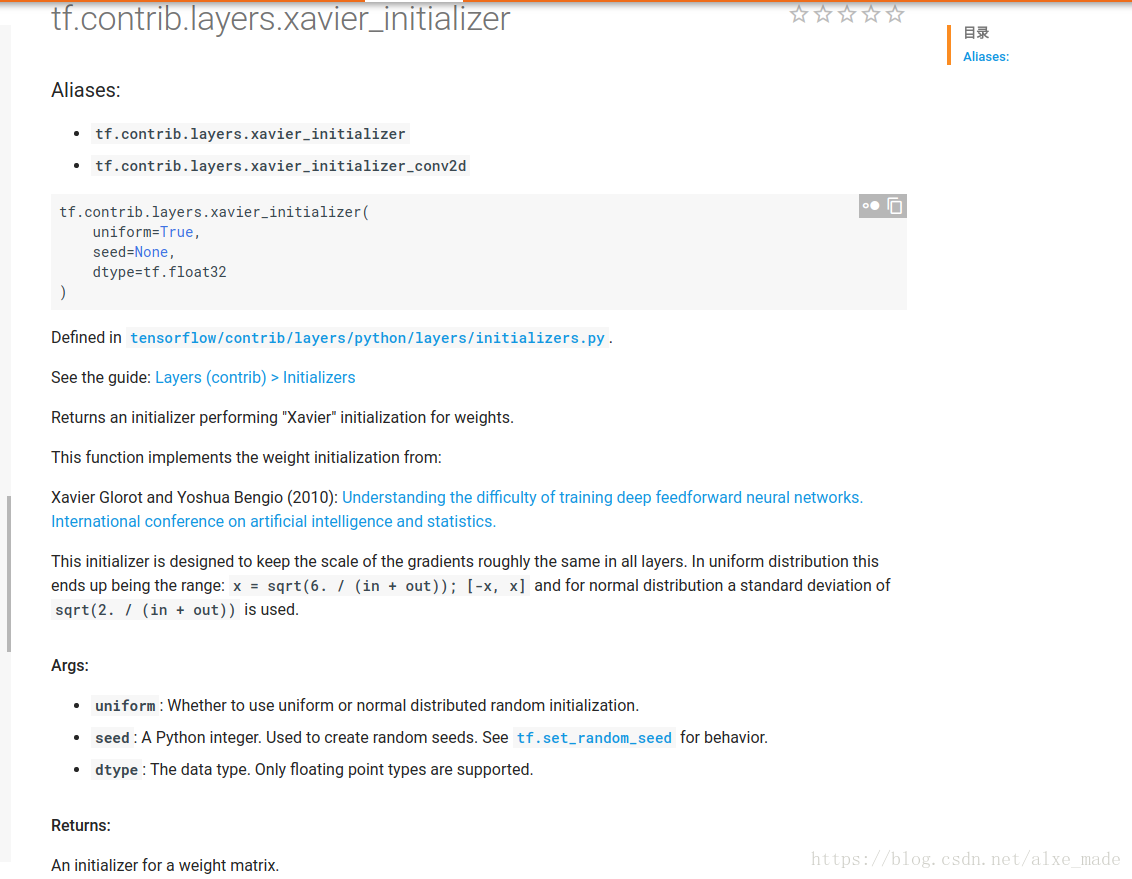
1、Xavier初始化:
优点:这个初始化器是用来保持每一层的梯度大小都差不多相同。通过使用这种初始化方法,可以避免梯度在最后一层网络中爆炸或者弥散。
条件:正向传播时,激活值的方差保持不变;反向传播时,关于状态值的梯度的方差保持不变。
初始化方法:
W ∼ U [ − 6 n i + n i + 1 , 6 n i + n i + 1 ] W \sim U\left[-\frac{\sqrt{6}}{\sqrt{n_{i}+n_{i+1}}}, \frac{\sqrt{6}}{\sqrt{n_{i}+n_{i+1}}}\right] W∼U[−ni+ni+16,ni+ni+16]
假设激活函数关于0对称,且主要针对于全连接神经网络。适用于tanh和softsign
论文地址:Understanding the difficulty of training deep feedforward neural networks

2、He初始化:
条件:正向传播时,状态值的方差保持不变;反向传播时,关于激活值的梯度的方差保持不变。
适用于ReLU的初始化方法:
W ∼ N [ 0 , 2 n i i ^ ] W \sim N\left[0, \sqrt{\frac{2}{n_{i} \hat{i}}}\right] W∼N[0,nii^2]
适用于Leaky ReLU的初始化方法:
W ∼ N [ 0 , 2 ( 1 + α 2 ) n ^ i ] W \sim N\left[0, \sqrt{\frac{2}{\left(1+\alpha^{2}\right) \hat{n}_{i}} ]}\right. W∼N[0,(1+α2)n^i2]
n ^ i = h i ∗ w i ∗ d i \hat{n}_{i}=h_{i} * w_{i} * d_{i} n^i=hi∗wi∗di
h i , w i h_{i}, w_{i} hi,wi分别表示卷积层中卷积核的高和宽,而di为当前层卷积核的个数。

论文地址:Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
权重衰减(weight decay)
参考:权重衰减(weight decay)与学习率衰减(learning rate decay)
L2正则化的目的就是为了让权重衰减到更小的值,在一定程度上减少模型过拟合的问题,所以权重衰减也叫L2正则化。
L2正则化与权重衰减系数
L2正则化就是在代价函数后面再加上一个正则化项:
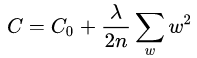
其中C0代表原始的代价函数,后面那一项就是L2正则化项,它是这样来的:所有参数w的平方的和,除以训练集的样本大小n。λ就是正则项系数,权衡正则项与C0项的比重。另外还有一个系数1/2,1/2 1/211经常会看到,主要是为了后面求导的结果方便,后面那一项求导会产生一个2,与1/2相乘刚好凑整为1。系数λ就是权重衰减系数。
为什么可以给权重带来衰减

权重衰减(L2正则化)的作用
作用:权重衰减(L2正则化)可以避免模型过拟合问题。
思考:L2正则化项有让w变小的效果,但是为什么w变小可以防止过拟合呢?
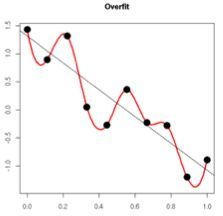
原理:(1)从模型的复杂度上解释:更小的权值w,从某种意义上说,表示网络的复杂度更低,对数据的拟合更好(这个法则也叫做奥卡姆剃刀),而在实际应用中,也验证了这一点,L2正则化的效果往往好于未经正则化的效果。(2)从数学方面的解释:过拟合的时候,拟合函数的系数往往非常大,为什么?如下图所示,过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。而正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况。
No bias decay:
一般来说,权重衰减会用到网络中所有需要学习的参数上面。然而仅仅将权重衰减用到卷积层和全连接层,不对biases,BN层的 \gamma, \beta 做权重衰减,效果会更好。
Bag of Tricks for Image Classification with Convolutional Neural Networks
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/185613.html原文链接:https://javaforall.net

![汽车电子设计之SBC芯片简单认识[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
