
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
InfluxDB是一个由InfluxData开发的开源时序型数据。它由Go写成,着力于高性能地查询与存储时序型数据。InfluxDB被广泛应用于存储系统的监控数据,IoT行业的实时数据等场景。
InfluxDB有三大特性:
- Time Series (时间序列):你可以使用与时间有关的相关函数(如最大,最小,求和等)
- Metrics(度量):你可以实时对大量数据进行计算
- Eevents(事件):它支持任意的事件数据
InfluxDB详解_顺其自然~的博客-CSDN博客_influxdb
database:数据库;
measurement:数据库中的表;
points:表里面的一行数据。
influxDB中独有的一些概念:Point由时间戳(time)、数据(field)和标签(tags)组成。series:一些数据结合,同一个database下,retention policy、measurement、tag sets完全相同的数据同属于一个 series,同一个series的数据物理上会存放在一起;
在influxdb中,字段必须存在。因为字段是没有索引的。如果使用字段作为查询条件,会扫描符合查询条件的所有字段值,性能不及tag。类比一下,fields相当于SQL的没有索引的列。
tags是可选的,但是强烈建议你用上它,因为tag是有索引的,tags相当于SQL中的有索引的列。tag value只能是string类型。
常用InfluxQL
-- 查看所有的数据库
show databases;
-- 使用特定的数据库
use database_name;
-- 查看所有的measurement
show measurements;
-- 查询10条数据
select * from measurement_name limit 10;
-- 数据中的时间字段默认显示的是一个纳秒时间戳,改成可读格式
precision rfc3339; -- 之后再查询,时间就是rfc3339标准格式
-- 或可以在连接数据库的时候,直接带该参数
influx -precision rfc3339
-- 查看一个measurement中所有的tag key
show tag keys
-- 查看一个measurement中所有的field key
show field keys
-- 查看一个measurement中所有的保存策略(可以有多个,一个标识为default)
show retention policies;
create database db1 -- 创建数据库db1
drop database db1 -- 删除数据库db1
drop measurement mt1 -- 删除表mt1
delete from measurement [WHERE <tag_key> <operator>]
drop shard <shard_id_num> 删除分片influxdbV1 和influxdbV2
1. 查询方法变更
原来使用InfluxQL方式查询,现在使用内置的Flux方式查询
2. 底层数据结构变更
原来的bucket+时间保留计划=现在的bucket
3. task取代连续查询
1.x版本和2.x版本最大的差异是连续查询(continuous query)已经被任务(task)所取代。influxdb中的连续查询功能是对外提供的对数据处理的功能,如为了预防我们的存储日志过大会建立起保存策略,超过设置的超时时间数据就丢失了。针对这种情况,我们可以通过连续查询功能,对用户的数据进行汇总、抽样等操作,再插入到另外的表中即可,虽然丢失了一定的精度,但是让数据占用的空间大大减小。
安装与访问
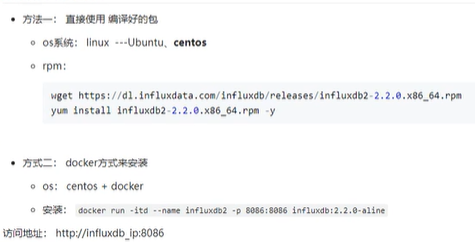

2.x版本,需要记住 bucket host org token
时序数据库influxDB(一)Linux安装与图形化/CLI连接influxDB2.2.0_xuehu96的博客-CSDN博客_influxdb连接
Flux query basics | Flux 0.x Documentation
from(bucket: "example-bucket") // ── Source
|> range(start: -1d) // ── Filter on time
|> filter(fn: (r) => r._field == "foo") // ── Filter on column values
|> group(columns: ["sensorID"]) // ── Shape
|> mean() // ── Process发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/185840.html原文链接:https://javaforall.net


