
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
————————————————————2020.8.11更新————————————————————
强化学习的一些相关概念
- 智能体(Agent): 智能体对环境进行观察,决策出行动,获得一个从环境返回的奖励
- 决策(Decision):意识层面的
- 行动(Action , a):物质层面的
- 环境(Environment):与智能体交互的对象
- 状态(State,s):是历史信息的函数,包含所有已有的信息。
- 奖励(Reward,R):是智能体采取行动后环境的一个反馈
- 策略(Policy):是状态到动作的函数
- 价值函数(Value function):是评价状态的一个指标
- 模型(Model):是个体对环境的建模
例题 1
背景描述:假设某个楼层共有 5 个房间,房间之间通过一道门相连,正如下图所示。我们将
房间编号为房间 0 到房间 4,楼层的外部,编号为 5。注意到房间 1 和房间 4 都可以直接通
到外部 5。
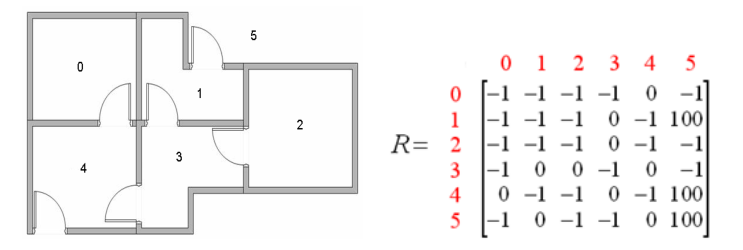

问题:假设有一个机器人对楼层的布局事先不知道,如何让一个机器人,从任意房间出发,能走到外面吗?
从奖励矩阵 R 出发来理解各个概念:
智能体(Agent):机器人
决策(Decision):从当前所在房间准备往哪里去
行动(Action):决策好到哪里去后,行动到那里去
环境(Environment):楼层布局
状态(State):当前所在房间
奖励(Reward):从当前房间走到另一个房间的奖励值(奖励矩阵中-1 表示无效值)
奖励矩阵 R(state, action)或 R(s, a): 每个元素值 R(s,a)表示在当前状态 s 下,采取行动 a 后
的即时奖励。
Q-学习简介
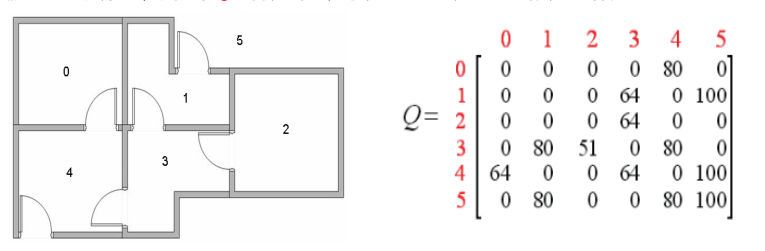
Q 矩阵:跟 R 矩阵维数相同,不同的是 Q(s, a)表示在当前状态 s 下,采取行动 a 后的后续累计奖励。是状态 s 和行动 a的函数, Q(s, a)用于评价当前状态 s 下,采取行动 a的结果好坏,Q也叫动作价值函数
假定已经获得一个最优的 Q 矩阵,则对任意状态 s 出发,到达目标状态的算法如下
步骤 1:随机选择一个初始状态 s
步骤 2:确定行动 a,使它满足 a = argmax{ Q(s , a ~ \widetilde{a} a
)}, a ~ \widetilde{a} a
∈A ,A是所有可能行动集合
步骤 3:令 s = s ~ \widetilde{s} s
,( s ~ \widetilde{s} s
为执行动作 a 后对应的下一个状态)
步骤 4:返回步骤 2
假定初始状态为 2,根据最优 Q 矩阵,有 2→3→1(4) →5→5;
假定初始状态为 1,根据最优 Q 矩阵,有 1→5→5;
假定初始状态为 0,根据最优 Q 矩阵,有 0→4→5→5;
如何获取最优的 Q 矩阵?
答案:Q-学习算法

Q-学习算法流程
步骤 1:给定奖励矩阵 R 和学习参数 γ,初始化 Q = 0,
步骤 2:随机选择一个初始状态 s,在当前状态 s 的所有可能行动中选取一个行动 a
步骤 3:利用选定的行为 a , 得到下一个状态 s ~ \widetilde{s} s
步骤 4:按照转移规则,计算Q(s,a)
步骤 5:s = s ~ \widetilde{s} s
,判断得到的Q矩阵是否收敛,不收敛则返回步骤 2,收敛则退出,完成q矩阵的学习
matlab算法如下
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 机器人如何从五个房间中的任意一个走出来?
% 中南大学 自动化学院 智能控制与优化决策课题组
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Q学习算法
% function Q = Reinforcement_Learning(R,gamma)
clear all
clc;
format short %显示4位小数
format compact %压缩空格
% 输入: R and gamma
% R:即时奖励矩阵; 行、列表示状态
% -1 = 表示无效值
R = [-1,-1,-1,-1,0, -1;
-1,-1,-1,0,-1, 100;
-1,-1,-1,0,-1, -1;
-1, 0, 0,-1,0, -1;
0,-1,-1,0,-1, 100;
-1,0, -1,-1,0, 100];
gamma = 0.80; % 学习参数
N = size(R,1); % R的行数,所有状态的个数,一行代表一个状态的所有信息
Q = zeros(size(R)); % 初始化Q矩阵,其行数和列数和R一样。Q初始全是0
Q1 = ones(size(R))*inf; % 前一次比较对象,判定收敛,Q初始全是无穷大
count = 0; % 计数器
for episode = 0:50000
% 产生随机初始状态
state = ceil(N*rand); %产生1-N之间的随机数
% 从当前状态出发,选择一个行动
x = find(R(state,:)>=0); % 所有可能行动,R(state,:)代表R的第state行,find(R(state,:)>=0)代表R的第state行里面大于0的数的列位置集合,是个行向量,
%上一句代码理解成找出当前状态可以向那些状态转移
if ~isempty(x) %如果有可以转移的
x1= x((ceil(length(x)*rand))); % 随机选择一个行动,理解成随机向一个状态转移,x1代表第几行(即为第几个状态)
end
qMax = max(Q,[],2); %返回矩阵中每行的最大值,是一个列向量,大小是Q的行数,每行最大值物理含义是这个状态下的最好奖励(最好出路)
Q(state,x1) = R(state,x1) + gamma*qMax(x1); % 转移规则。qMax(x1)代表x1这个状态下的最好奖励
% 判定是否收敛 其实就是前后两个Q矩阵的差很小就认为是收敛了
if sum(sum(abs(Q1-Q)))<0.0001 && sum(sum(Q>0)) %sum(sum(Q>0))代表Q大于0的数的个数,sum(sum(abs(Q1-Q)))代表Q1与Q对应位置相减绝对值之和
if count > 1000 %且学习了超过1千次
disp(strcat('强化学习的总次数: ',num2str(episode)));
break %跳出for循环
else %没有学习了超过1千次
count = count+1;
end
else %不收敛,差距很大
Q1 = Q; %把最新的一个Q作为比较对象,覆盖掉原来的
count = 0;
end
end
% 归一化
Qmax = max(max(Q));%max(max(Q))代表Q里面最大的元素,max(Q)代表每一列最大的元素
if Qmax >0
Q = 100*Q/Qmax;
end
Q
本文来源于中南大学 自动化学院 智能控制与优化决策课题组周晓君老师的学习笔记,加了一些我自己对代码的注释,
还有两个问题未解决
1、Q-学习算法的转移规则可以换成其他的公式来产生新解迭代吗
2、除了Q-学习算法还可以用其他方法来解决Q矩阵的求取吗?
继续学强化学习,看看有啥新的体会与想法没
强化学习学习什么东西?
1、Q矩阵,动作价值函数算出来的一个矩阵,其中的Q(s,a)评价当前状态 s 下,采取行动 a 后的结果好坏程度。
2、策略函数π,π(s,a)代表当前状态 s 下,采取行动 a 的一个概率。当前状态下所有行动的概率和为1.
只要学到其中一个就可以实现对智能体的控制了。上面代码显示的就是第一种——Q矩阵的学习
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/186446.html原文链接:https://javaforall.net


